本文主要是介绍【python量化】将DeepAR用于股票价格多步概率预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

写在前面
DeepAR是亚马逊提出的一种针对大量相关时间序列建模的预测算法,该算法采用了深度学习的技术,通过在大量时间序列上训练自回归递归网络模型,可以从相关的时间序列中有效地学习全局模型,并且能够学习复杂的模式,例如季节性,周期性等特性,从而实现对各条时间序列进行预测。下面的这篇文章主要教大家如何搭建一个基于DeepAR的简单预测模型,并将其用于股票价格预测当中。
1
DeepAR模型
DeepAR采用了以RNN模型为基础的seq2seq架构,实现多步概率预测。具体地,首先用encoder对conditioning range的数据,也即是过去的历史数据进行编码,得到隐层输出,然后将其作为decoder网络的初始化隐层状态。之后,经过decoder的多次迭代,将输出的结果转化为概率分布的参数,从而实现通过DeepAR得到预测的概率分布。其中,对于训练数据,prediction range的数据,也即是ground truth数据是已知的,所以可以直接用于decoder的输入,来实现通过最大化似然函数对于模型参数进行训练。而对于测试数据,prediction range是没有给定的,所以就需要通过上一时刻的值进行采样,得到一个估计值用于不断迭代输出。模型的基本架构如下所示:
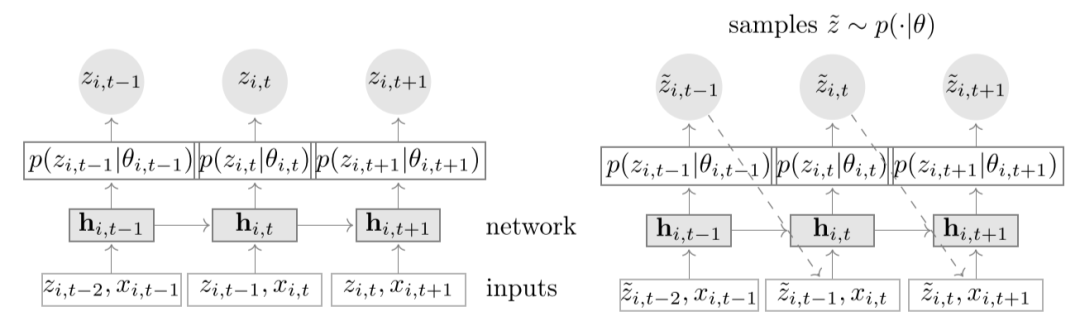
模型架构
相比于传统的时间序列预测模型,如ARIMA、VAR,DeepAR则可以很方便地将额外信息进行引入,并且其预测目标是序列在每个时间步上取值的概率分布。相比于直接预测数据,概率预测更有实际意义。
2
环境配置
DeepAR模型的实现主要依赖于GluonTS库 (Gluon Time Series),它是一个专门为概率时间序列建模而设计的工具包,由亚马逊开源维护。GluonTS 简化了时间序列模型的开发和实验,常用于预测或异常检测等常见任务。股票数据的获取通过baostock库进行实现。
库版本:
baostock 0.8.8
mxnet 1.7.0.post2
gluonts 0.9.4
matplotlib 3.5.13
代码实现
1、数据获取
首先,定义一个数据获取的函数,其中通过baostock库获取指定代码股票从2020/1/1到2022/1/1两年的日线数据。
def get_stockdata(code):rs = bs.query_history_k_data_plus(code,'date,close,volume,turn',start_date='2020-01-01',end_date='2022-01-01',frequency='d', adjustflag='2') return rs.get_data()2、数据划分
之后,定义预测长度以及需要获取的股票代码。然后将获取到的数据划分为训练集和测试集。这里prediction_length变量定义了预测长度,stock_list中选取了三支上海证券交易所中三支医疗板块的股票。之后,将得到的股票数据转换为GluonTS指定的输入数据格式ListDataset。其中,start表示预测起始值,target表示预测的目标变量,cat表示引入的静态变量,这里用到了股票的id,dynamic_feat表示其他的动态标量,这里引入了交易量跟换手率,它的长度需要跟target一致。
prediction_length = 20
stock_list = ['sh.600227', 'sh.600200', 'sh.600201']
train_dic_list = []
test_dic_list = []
lg = bs.login()for stock_id in stock_list:df = get_stockdata(stock_id)train_dic = {'start':df.date[0],'target':df.close,'cat':int(stock_id.split('.')[1]),'dynamic_feat':[df.volume, df.turn]}test_dic = {'start':df.date[0],'target':df.close[:-prediction_length],'cat':int(stock_id.split('.')[1]),'dynamic_feat':[df.volume[:-prediction_length], df.turn[:-prediction_length]]}train_dic_list.append(train_dic)test_dic_list.append(test_dic)bs.logout()3、模型构造与训练
之后,需要构造DeepAR模型,并进行训练。其中,prediction_length:预测范围的长度;context_length表示在计算预测之前要为RNN展开的步骤数(默认context_length等于prediction_length);num_layers表示RNN层数;num_cells表示每层的RNN的神经元个数。
estimator = DeepAREstimator(prediction_length=prediction_length,context_length=60,freq='1d',num_layers=2,num_cells=64,trainer=Trainer(epochs=20,learning_rate=1e-2,num_batches_per_epoch=32)
)
predictor = estimator.train(train_data)4、模型测试与可视化
首先,定义一个函数用于结果的可视化。
def plot_prob_forecasts(ts_entry, forecast_entry, path, sample_id):plot_length = 150prediction_intervals = (50, 80)legend = ['observations', 'median prediction'] + [f'{k}% prediction interval' for k in prediction_intervals][::-1]_, ax = plt.subplots(1, 1, figsize=(10, 7))ts_entry[-plot_length:].plot(ax=ax)forecast_entry.plot(prediction_intervals=prediction_intervals, color='g')ax.axvline(ts_entry.index[-prediction_length], color='r')plt.legend(legend, loc='upper left')plt.savefig('{}forecast_{}.png'.format(path, sample_id))plt.close()之后调用模型评估的方法对训练好的模型进行评估,其中num_samples表示可视化数据的长度。最后,将plot的结果保存在本地。
forecast_it, ts_it = make_evaluation_predictions(dataset=test_data,predictor=predictor,num_samples=100
)tss = list(tqdm(ts_it, total=len(test_data)))
forecasts = list(tqdm(forecast_it, total=len(test_data)))plot_log_path = './plots/'
directory = os.path.dirname(plot_log_path)
if not os.path.exists(directory):os.makedirs(directory)for i in tqdm(range(len(stock_list))):ts_entry = tss[i]forecast_entry = forecasts[i]plot_prob_forecasts(ts_entry, forecast_entry, plot_log_path, i)5、运行结果与分析
经过20个epoch的训练,可以看出模型的loss不断下降,实际应用中可以通过超参优化,warmup,early stop,dropout等一系列的操作来使得模型具有更好的训练效果,这里不再赘述。
100%|██████████| 32/32 [00:12<00:00, 2.63it/s, epoch=1/20, avg_epoch_loss=1.99]
100%|██████████| 32/32 [00:13<00:00, 2.34it/s, epoch=2/20, avg_epoch_loss=1.01]
100%|██████████| 32/32 [00:07<00:00, 4.49it/s, epoch=3/20, avg_epoch_loss=1.07]
100%|██████████| 32/32 [00:06<00:00, 4.61it/s, epoch=4/20, avg_epoch_loss=0.87]
100%|██████████| 32/32 [00:06<00:00, 4.63it/s, epoch=5/20, avg_epoch_loss=0.614]
100%|██████████| 32/32 [00:05<00:00, 5.40it/s, epoch=6/20, avg_epoch_loss=0.595]
100%|██████████| 32/32 [00:05<00:00, 6.18it/s, epoch=7/20, avg_epoch_loss=0.474]
100%|██████████| 32/32 [00:05<00:00, 5.82it/s, epoch=8/20, avg_epoch_loss=0.399]
100%|██████████| 32/32 [00:05<00:00, 5.85it/s, epoch=9/20, avg_epoch_loss=0.36]
100%|██████████| 32/32 [00:05<00:00, 5.58it/s, epoch=10/20, avg_epoch_loss=0.273]
100%|██████████| 32/32 [00:05<00:00, 5.78it/s, epoch=11/20, avg_epoch_loss=0.208]
100%|██████████| 32/32 [00:05<00:00, 5.83it/s, epoch=12/20, avg_epoch_loss=0.169]
100%|██████████| 32/32 [00:05<00:00, 6.04it/s, epoch=13/20, avg_epoch_loss=0.156]
100%|██████████| 32/32 [00:05<00:00, 6.04it/s, epoch=14/20, avg_epoch_loss=0.26]
100%|██████████| 32/32 [00:05<00:00, 5.98it/s, epoch=15/20, avg_epoch_loss=0.189]
100%|██████████| 32/32 [00:05<00:00, 5.69it/s, epoch=16/20, avg_epoch_loss=0.138]
100%|██████████| 32/32 [00:05<00:00, 5.62it/s, epoch=17/20, avg_epoch_loss=0.0314]
100%|██████████| 32/32 [00:05<00:00, 5.79it/s, epoch=18/20, avg_epoch_loss=-.033]
100%|██████████| 32/32 [00:05<00:00, 5.73it/s, epoch=19/20, avg_epoch_loss=0.0111]
100%|██████████| 32/32 [00:05<00:00, 5.67it/s, epoch=20/20, avg_epoch_loss=0.00313]三只股票的预测结果可视化如下三张图所示,其中蓝色的线代表ground truth,绿色的线代表概率预测的中值,两个绿色区域则代表了80%跟50%的置信区间。从可视化的结果中也可以看出,随着时间的推移,模型预测结果的误差逐渐扩大,这也侧面说明了进行多步预测的难度之大。
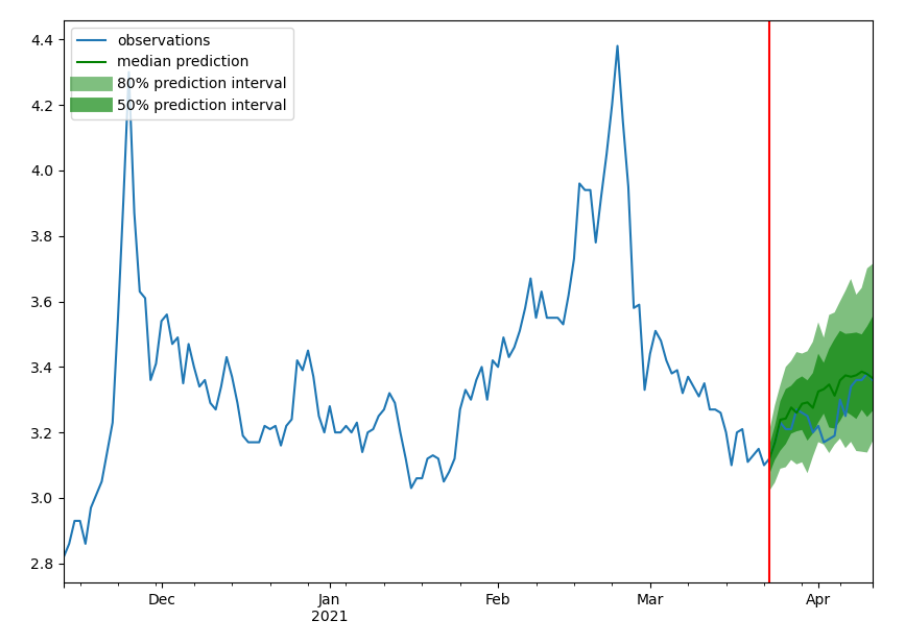
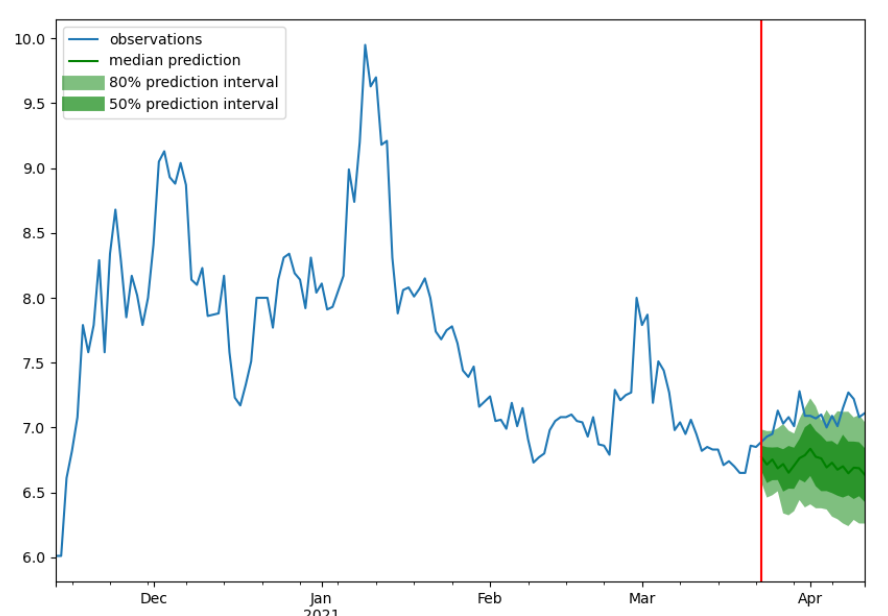
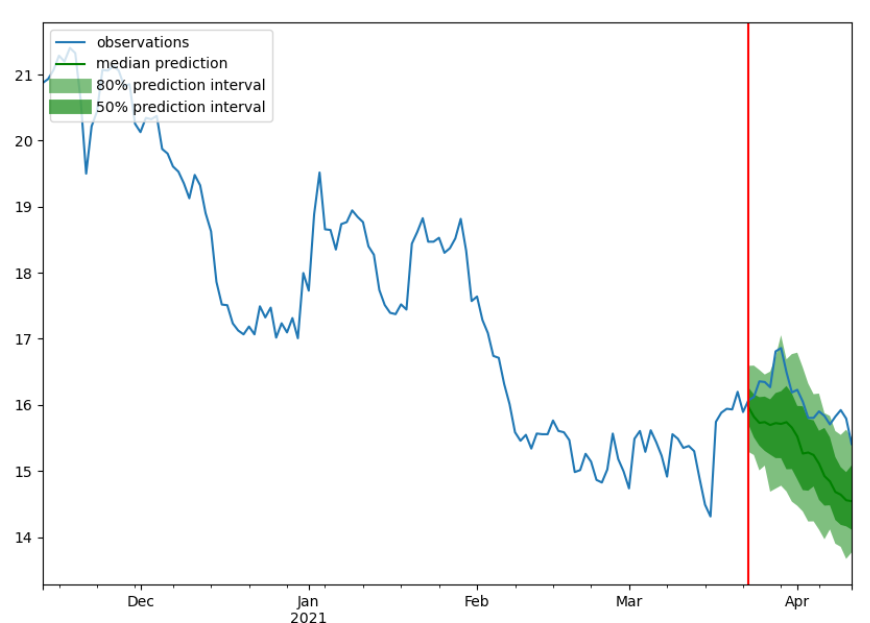
4
总结
本文简单介绍了DeepAR模型在股价多步预测方面的实现,并通过真实股票数据进行了实验验证。在深度学习预测应用方面中,目前主流的方法是利用RNN、LSTM等递归神经网络来进行预测,对于多步预测则同样是基于RNN模型的seq2seq架构,DeepAR模型也是如此,只不过DeepAR模型并不是简单地输出一个预测数值,而是输出预测值的一个概率分布,相比之下,这样做具有多方面的好处,输出一个概率分布则更加具有实际意义,或许还可以实现更高的预测精度。另外,在股价预测方面,通过给出预测值的概率分布,可以给出未来预测结果的不确定性以及相应的风险评估。本文内容仅仅是技术探讨和学习,并不构成任何投资建议。
参考文献:
Salinas, D., Flunkert, V., Gasthaus, J., & Januschowski, T. (2020). DeepAR: Probabilistic forecasting with autoregressive recurrent networks. *International Journal of Forecasting*, *36*(3), 1181-1191.

《人工智能量化实验室》知识星球

加入人工智能量化实验室知识星球,您可以获得:(1)定期推送最新人工智能量化应用相关的研究成果,包括高水平期刊论文以及券商优质金融工程研究报告,便于您随时随地了解最新前沿知识;(2)公众号历史文章Python项目完整源码;(3)优质Python、机器学习、量化交易相关电子书PDF;(4)优质量化交易资料、项目代码分享;(5)跟星友一起交流,结交志同道合朋友。(6)向博主发起提问,答疑解惑。

这篇关于【python量化】将DeepAR用于股票价格多步概率预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




