本文主要是介绍数据挖掘案例——基于RFM模型的药店会员价值分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、背景
“互联网+”及“大数据”的助力下,几乎所有药店都实行了会员制,从传统的品类驱动转为客户为中心的销售模式。经我们数据分析发现,目前药店会员的年销售占比差不多在60%左右,对会员实行精细化管理,是药店在日益激烈的竞争市场中必不可少的举措。
如何进行会员的精细化管理?首先要建立合理的会员价值评估模型,对客户进行分类。
以下是某系统后台筛选会员的口径,这只是其中的一部分。我们发现,筛选的特征标签还是很多的,但是这样的会员筛选方式可以满足某一特定主体的会员营销需求(如客单价>120元、年消费次数大于14次),但是如果我们这个时候统一的想筛选出“高价值”的会员进行会员营销,我们理解“高价值”的含义,却往往难以入手。什么样的会员算是“高价值”会员,该选哪个指标的哪个区间呢?
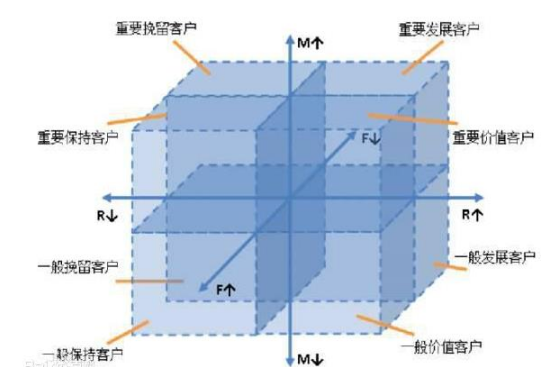
在以往的零售行业,传统的用户价值评估模型主要是建立在RFM模型上,通过三个指标:最近消费时间间隔(Recency)、消费频率(Frequency)、消费金额(Monetary),依照各属性“均值”进行分区。但是该方式也有明显的缺点:
-
细分的用户群体太多,相应的营销成本也会增加,如下图。
-
未考虑各属性之间的量纲差异及分布。
本文对在传统的RFM模型之后,进行了改进,并运用聚类方法(K-Means),综合各个维度,根据会员价值对会员进行划分。并对不同的会员类别进行特征分析,比较不同类会员的客户价值; 对不同价值的会员类别提供个性化服务,制定相应的营销策略。
二、数据集描述
1、主表
药店动销流水表(buyrecord):两年的会员动销数据,唯一标识为订单id,药品id。
-
数据条数:657373条;
-
门店数 57家;
-
会员数:大约35117个;
-
时间跨度:两年(2017-12-1~2019-11-30);
-
会员销售额占比:65.72%;
2、辅助表
- 药品分类标签(corpdrugtype):唯一标识为药店的药品编号,用于保存药品的分类标签。
- 会员表(users);唯一标识为会员的id,用于保存全量会员数据。
- 药品信息表(druginfo):唯一标识为药品的商品条码(gtn),用于保存药品的说明数据等。
三、分析思路
首先我们的分析模型是建立在RFM模型之上的。所以,我们先建立这三个指标:最近消费时间间隔(Recency)、消费频率(Frequency)、消费金额(Monetary)。我们先结合实际的业务来定义药店的这三个指标:
- 消费金额(M):两年内的销售总额。
- 最近消费时间间隔(R):最近一次销售时间距离2019年11月30日的天数。
- 消费频率(F):两年内购买订单数。
另外根据实际业务,我们认为以下的指标也同样需要被考虑进去:
- 办卡至今时间间隔(L):办卡日期距离2019年11月30日的天数。
- 疾病价值(D):慢病药品,保健品,阶段性药品的购药金额占比。
结合以上五个指标,我们采用K-Means聚类,识别会员的价值。
四、python库导入
#1、数据处理
import pandas as pd
import numpy as np
#2、可视化
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.family']='SimHei'
plt.rcParams['axes.unicode_minus']=False
#3、特征工程
import sklearn
from sklearn import preprocessing #数据预处理模块
from sklearn.preprocessing import LabelEncoder #标签转码
from sklearn.preprocessing import StandardScaler #归一化
from imblearn.over_sampling import SMOTE #过抽样
from sklearn.model_selection import train_test_split #数据分区
from sklearn.decomposition import PCA
#4、聚类算法
from sklearn.cluster import KMeans#5、模型评价
from sklearn.metrics import classification_report,precision_score,recall_score,f1_score #分类报告
from sklearn.metrics import confusion_matrix #混淆矩阵
from sklearn.metrics import silhouette_score #轮廓系数
from sklearn.model_selection import GridSearchCV #交叉验证
from sklearn.metrics import make_scorer
from sklearn.ensemble import VotingClassifier #投票五、数据清洗
1、数据导入
#导入两年的动销数据
data_buyrecord=pd.read_csv(r'E:\dataset\huangshixinshiji\buyrecord_20171201_20191130.csv')
#增加“avgprice”——平均单价字段
data_buyrecord['avgprice']=(data_buyrecord['paidMoney']/data_buyrecord['quantity']).fillna(0)2、数据探索
#查看各数据的缺失条数,最大值,最大值
data_describe=data_buyrecord.describe(include='all').T
data_describe['count']=len(data_buyrecord)-data_describe['count']
data_describe.loc[:,['count','min','max']].round(2)输出:

根据以上的信息,以及对业务逻辑的理解,我们认为需要从以下几点做规避数据异常:
-
uid(会员编号):不能为空
-
phone(会员电话):不能为空(电话字段是否需要,可最后营销时期再匹配)
-
cardDate(开卡日期):不能为空(总共52643个会员,共14583个cardDate存在空值)
-
cardDate(开卡日期):不能大于同条记录的date(销售日期)。
-
cardDate(开卡日期):应该符合实际情况,将小于2010年的删除。
-
查看销售金额超过1000的都是卖了什么?是高价格还是存在异常数据。
3、数据处理
3.1、删除carddate为空值且同一个会员多个carddate
#同一个uid,是否存在多个cardDate
data_groupby_uid=data_buyrecord.groupby(by='uid')
data_groupby_uid_cardDate_count=data_groupby_uid['cardDate'].nunique().sort_values(ascending=False).reset_index()
data_groupby_uid_cardDate_count输出:

数据集存在carddate空值和多个carddate值,需要进行删除。
data_buyrecord_1=data_buyrecord[data_buyrecord['uid'].isin(data_groupby_uid_cardDate_count[data_groupby_uid_cardDate_count['cardDate']==1]['uid'])]
data_buyrecord_1.shape输出:
(474630, 27)删除之后的数据剩下474630条。
3.2、查看销售额超过1000的都卖了什么商品
data_buyrecord_1[data_buyrecord_1['paidMoney']>1000].loc[:,['username','generalName','specification','companyName','paidMoney','quantity']].sort_values(by='paidMoney',ascending=False).head(20)输出:
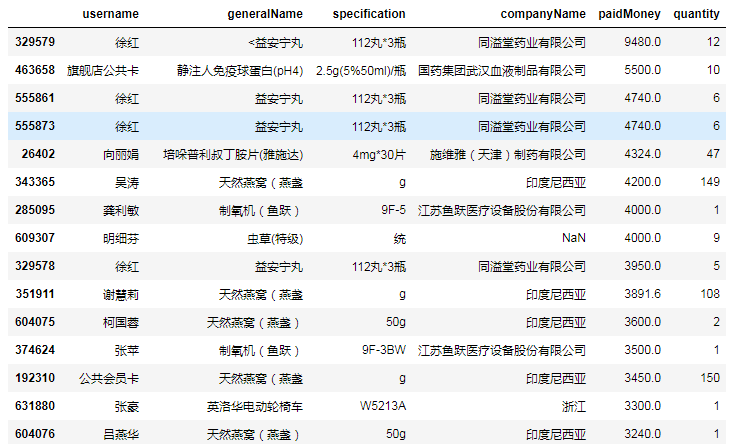
通过销售额的排序我们发现,超过1000元的购药明细记录当中,有部分是门店自己的“会员公共卡”,对于公共卡我们建议删除。
data_buyrecord_1.drop(data_buyrecord_1[data_buyrecord_1['username'].str.contains('公共')].index,inplace=True)
data_buyrecord_1.shape输出:
(462992, 27)
剩余462992条销售记录数据。
另外,我们可以查看quantity和avgprice字段,因为后面的模型我们未涉及到quantity和avgprice字段,这边我们不输出结果了。
#查看销售盒数超过100盒的都卖了什么东西
data_buyrecord[data_buyrecord['quantity']>100].loc[:,['username','generalName','specification','companyName','paidMoney','quantity']].sort_values(by='quantity',ascending=False)
#查看单价排行
data_buyrecord.sort_values(by='avgprice')
#查看销售量为0的数据
data_buyrecord[data_buyrecord['quantity']==0]3.3、删除carddate>date以及开卡时间(carddate)小于2010年的数据
和门店咨询得到门店是从2010年开始引入会员管理,故我们设定开卡时间必须小于2010年。
#数据类型转换
data_buyrecord_1['cardDate']=pd.to_datetime(data_buyrecord_1['cardDate'])
data_buyrecord_1['date']=pd.to_datetime(data_buyrecord_1['date'])
#删除carddate>date以及开卡时间(carddate)小于2010年的数据
data_buyrecord_1=data_buyrecord_1.drop(data_buyrecord_1.index[(data_buyrecord_1['cardDate']>data_buyrecord_1['date'])|(data_buyrecord_1['cardDate']<'2010-01-01')])
data_buyrecord_1.shape输出:
(431156, 27)
剩余431156条销售记录数据。
4、特征指标数据整合
根据前面的总结,我们删除和消费金额(M)、最近消费时间间隔(R)、消费频率(F):两年内购买订单数、办卡至今时间间隔(L)、疾病价值(D)这五个指标不相关的字段。
#删除不相关的字段:id,cid,erpsid,sid,did,gtn,generalname,specification,companyname,sex,wechart,salesname,quantity,salesid,id,creatime,avgprice,date_count
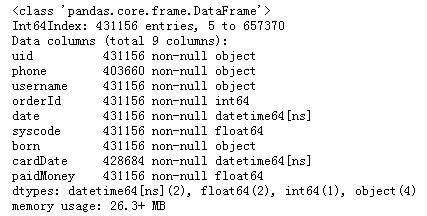
data_buyrecord_2=data_buyrecord_1.loc[:,['uid','phone','username','orderId','date','syscode','born','cardDate','paidMoney']]
data_buyrecord_2.info()输出:
接下来我们按照会员uid,对数据进行整合,算出消费金额(M)、最近消费时间间隔(R)、消费频率(F)、办卡至今时间间隔(L)、疾病价值(D)这五个指标:
4.1、办卡至今时间间隔(L)
#办卡至今时间间隔L(2019-11-30)-月数
data_buyrecord_2_groupby=data_buyrecord_2.groupby(by='uid')
data_carddate=data_buyrecord_2_groupby['cardDate'].first().reset_index()
data_carddate['curent_time']=pd.to_datetime('2019-11-30') #指定现今时间
data_carddate['L_month']=data_carddate['curent_time']-data_carddate['cardDate'] #计算办卡距今时间,单位:天
data_carddate['L_month']=data_carddate['L_month'].apply(lambda x:x/np.timedelta64(30,'D')) #按天,计算月
data_carddate输出:

4.2、最近消费时间间隔(R)
#最近消费时间间隔R(2019-11-30)-月数
data_lastbuytime=data_buyrecord_2_groupby['date'].max().reset_index()
data_lastbuytime['curent_time']=pd.to_datetime('2019-11-30')
data_lastbuytime['R_month']=data_lastbuytime['curent_time']-data_lastbuytime['date']
data_lastbuytime['R_month']=data_lastbuytime['R_month'].apply(lambda x:x/np.timedelta64(30,'D'))
data_lastbuytime输出:
4.3、消费频率(F)
#消费频率F(orderid)
data_sumorderid=data_buyrecord_2_groupby['orderId'].nunique().reset_index().rename(columns={'orderId':'F_orderid'})
data_sumorderid输出:
4.4、消费金额(M)
#销售金额M(paidmoney)
data_sumpaidmoney=data_buyrecord_2_groupby['paidMoney'].sum().reset_index().rename(columns={'paidMoney':'M_paidmoney'})
data_sumpaidmoney输出:
4.5、疾病价值(D)
算该指标我们需要以下两个辅助表:
- 药品分类标签(corpdrugtype):唯一标识为药店的药品编号,用于保存药品的分类标签。
- 药品信息表(druginfo):唯一标识为药品的商品条码(gtn),用于保存药品的说明数据等。
#4,5,9药品的购药金额占比D(百分比)
data_corpdrugtype=pd.read_csv(r'E:\dataset\huangshixinshiji\corpdrugtype.csv')
data_druginfo459=pd.read_csv(r'E:\dataset\huangshixinshiji\druginfo_459.csv')data_paidmoney459=pd.merge(pd.merge(data_buyrecord_2.loc[:,['syscode','uid','paidMoney']],data_corpdrugtype.loc[:,['syscode','gtn']].drop_duplicates(),how='inner',on='syscode'),data_druginfo459.loc[:,['gtn','rebuyLevel']],how='inner',on='gtn')#统计每个会员购买459药品的金额
data_paidmoney459=data_paidmoney459.groupby(by='uid')['paidMoney'].sum().reset_index().rename(columns={'paidMoney':'D_paidMoney459'})#算459药品占总销售额的比重
data_paidmoney459_percent=pd.merge(data_sumpaidmoney,data_paidmoney459,how='left',on='uid')
data_paidmoney459_percent['D_percent']=data_paidmoney459_percent['D_paidMoney459']/data_paidmoney459_percent['M_paidmoney']
data_paidmoney459_percent=data_paidmoney459_percent.fillna(0)
data_paidmoney459_percent输出:
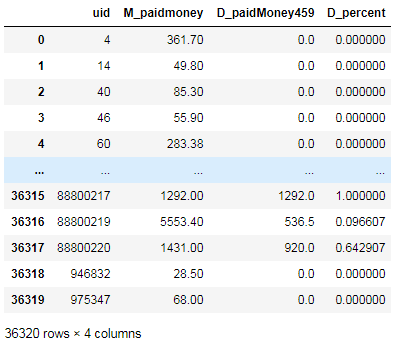
4.6、整合所有特征指标
data_attr=pd.merge(pd.merge(pd.merge(
pd.merge(data_carddate.loc[:,['uid','L_month']],data_lastbuytime.loc[:,['uid','R_month']],how='inner',on='uid')
,data_sumorderid,how='inner',on='uid')
,data_sumpaidmoney,how='inner',on='uid')
,data_paidmoney459_percent.loc[:,['uid','D_percent']],how='inner',on='uid')
data_attr.head()输出:

4.7、数据再清洗
删除订单数大于100单的会员记录。
data_attr=data_attr.drop(data_attr[(data_attr['F_orderid']>100)].index)
data_attr.describe().T输出:

删除会员459的销售占比大于1和小于0的记录
data_attr=data_attr.drop(data_attr[(data_attr['D_percent']>1) |(data_attr['D_percent']<0)].index)
data_attr.describe().T输出:
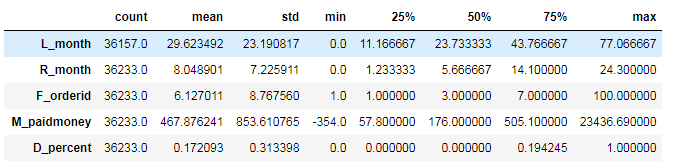
删除会员销售额小于0 的记录
data_attr=data_attr.drop(data_attr[data_attr['M_paidmoney']<0].index)
data_attr.describe().T输出:
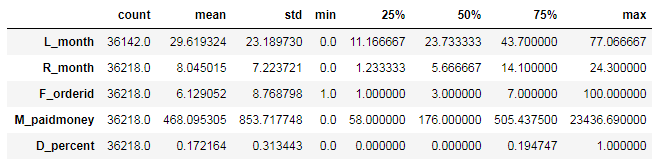
删除办卡时间间隔为空值的记录
data_attr=data_attr.drop(data_attr[data_attr['L_month'].isnull()].index)
data_attr.describe().T输出:

六、模型构建
1、量纲差异的处理
从处理完的数据我们可以看到,5个指标的取值范围差异较大,需进行标准化(Z-score)处理,消除数量级的影响;
data_attr=(data_attr.iloc[:,1:]-data_attr.mean())/data_attr.std()
data_attr=data_attr.rename(columns={'L_month':'L','R_month':'R','F_orderid':'F','M_paidmoney':'M','D_percent':'D'})
data_attr.describe().T输出:

2、模型构建
K-Means聚类分析的核心是选择合适的k,即选择分类成几个组合适,我们先将k从1到10遍历,输出其族群内方差总和(WGSS),使其足够小,但是也不能太小,我们通过绘制碎石图,进行k的选择。
from sklearn.cluster import KMeans
import matplotlib.pyplot as pltwgss=[]
for i in range(10):cluster = KMeans(n_clusters=i+1, random_state=0).fit(data_attr)wgss.append(cluster.inertia_) #inertia_:每个点到其簇的质心的距离之和。即WGSS#绘制WGSS的碎石图
plt.plot([i+1 for i in range(10)],wgss,marker='o')输出:
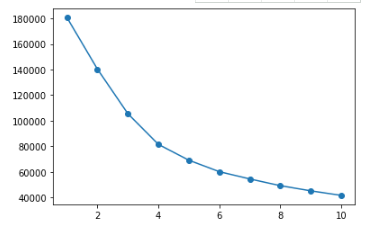
从以上碎石图看,我们建议分成5类,较为合适,我们以k=5作为分类标准进行会员划分。
from sklearn.cluster import KMeans
model=KMeans(n_clusters=5) #模型实例化
model.fit(data_attr) #模型训练#统计各个类别的数目
r1=pd.Series(model.labels_).value_counts()
#找出聚类中心(质心)
r2=pd.DataFrame(model.cluster_centers_)
#横向连接(0为纵向),得到各聚类中心对应的类别的数目
r=pd.concat([r2,r1],axis=1)
#重命名表头
r.columns=list(data_attr.columns)+['类别数目']
r输出:
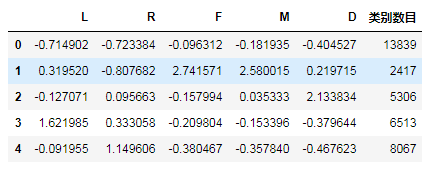
输出了每个指标的质心(平均值)即分类后每个类别的数量。
七、分类描述
1、绘制雷达图
我们以质心作为各类的代表画雷达图:
from matplotlib import pyplot as plt
plt.style.use('ggplot') #使用ggplot绘图风格
plt.rcParams['font.sans-serif']=['SimHei'] #用来显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
#标签
labels=np.array(["L(办卡至今时间间隔)","R(最近消费时间间隔)","F(消费频率)","M(消费金额)","D(459药品销售)占比"])
#数据个数
N=r2.shape[1]
#设置雷达图的角度,用于平分切开一个圆面。
angles=np.linspace(0,2*np.pi,N,endpoint=False) #endpoint默认为True,False表示不包含结束点
data=pd.concat([r2,r2.ix[:,0]],axis=1) #使雷达图一圈封闭起来
angles=np.concatenate((angles,[angles[0]])) #使雷达图一圈封闭起来fig=plt.figure(figsize=(8,8))
ax=fig.add_subplot(111,polar=True) #打开极坐标for i in range(r2.shape[0]):j=i+1ax.plot(angles,data.ix[i,:],'o-',linewidth=2, #线的粗细#label='user%s' %jlabel="user%s(%s人)"%(j,r['类别数目'][i]))#添加各个特征的标签
ax.set_thetagrids(angles*180/np.pi,labels) #第一个参数为度数,圆的总度数为360度。
ax.set_title('会员特征分布图',va='bottom',fontproperties='SimHei')
ax.set_rlim(-1,3) #
ax.grid(True) #调节网格线
plt.legend()
plt.show()输出:

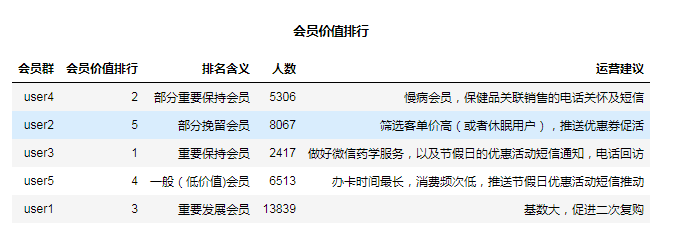
2、类别描述:
针对“会员特征分析图”所示的聚类结果,结合业务进行特征分析。在五个指标:L(办卡至今时间间隔)、R(最近消费时间间隔)、F(消费频率)、M(消费金额)、D(459药品销售占比);我们重点关注的是R(最近消费时间间隔)、F(消费频率)、M(消费金额)三个指标:
-
会员群1(user1)L属性上最小,可定义为新会员;
-
会员群2(user2)在R属性上最大,可定义为流失会员(最近消费时间间隔在7.5个月以上);
-
会员群3(user3)在F、M属性上最大,可定义为高价值会员;
-
会员群4(user4)在D属性上最大,可定义为潜在慢病高价值会员,可在细分出高价值的慢病会员(慢病销售金额大的)。
-
会员群5(user5)在L属性上最大,R较大,M、F适中、可定义为一般会员。
每种会员类别的特征如下:
-
重要保持会员:user3(F(消费频率)、M(消费金额)最高、D(459药品占比)较高,R(最近消费时间间隔)低)和部分users4(D(459药品占比)最高,筛选部分慢病销售额大的客户)。应将资源优先投放到这类客户身上,进行差异化管理,提高客户的忠诚度和满意度。
-
重要发展会员:user1:F(消费频率)、M(消费金额)、D(459药品占比)、R(最近消费时间间隔)较低。这类客户L(办卡至今时间间隔)较短、当前价值低、发展潜力大,应促使客户增加二次复购消费的优惠力度。
-
一般挽留会员:user2:R(最近消费时间间隔)最大,可在其中挑选出客单价高的客户。
-
一般和低价值会员:user5:L(办卡至今时间间隔)最大,R(最近消费时间间隔)较大,M(消费金额)、F(消费频率)适中。这类客户可能在打折促销时才会选择消费。
会员分类群体基数及运营建议可见下表:
这篇关于数据挖掘案例——基于RFM模型的药店会员价值分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








