本文主要是介绍深度探索C++对象模型(四)Function语意学,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
C++支持三种类型member functions:static、nonstatic和virtual,每一种类型被调用的方式都不相同。
(一)Member的各种调用方式
1、Nonstatic Member Functions(非静态成员函数)
C++的设计准则之一就是:nonstatic member function至少必须和一般的nonmember function有相同的效率。也就是说,如果我们要在以下两个函数之间做选择:
float magnitude3d(const Point3d *_this){...}float Point3d::magnitude3d()const {...}选择member function不应该带来什么额外负担。这是因为编译器内部已将“member 函数实例”转换为对等的“nonmember函数实例”。
乍见之下似乎nonmember function比较没有效率,它间接地经由参数取用坐标成员,而member function确实直接取用成员。然而实际上member function被内化为nonmember的形式。下面就是转化步骤:
a、改写函数的signature(函数原型)以安插一个额外的参数到member function中,用以提供一个存取通道,使class object得以将此函数调用。该额外参数被称为this指针。
b、将每一个“对nonstatic data member的存取操作”改为经由this指针来存取;
c、将member function重新写成一个外部函数。将函数名称经过“mangling”处理,使它在程序中称为独一无二的词汇。
名称的特殊处理(Name Mangling)
一般而言,member的名称前面会被加上class名称,形成独一无二的命名。例如下面的声明:
class Bar{public:int ival;...};其中的ival有可能变成这样:
//member经过name-mangling之后的可能结果之一
ival_3Bar
为什么编译器要这么做?请考虑这样的派生操作:
class Foo:public Bar { public:int ival;…};
记住,Foo对象内部结合了base class 和derived class 两者:
//C++ 伪码
//Foo的内部描述
//C++ 伪码
//Foo的内部描述
class Foo
{public:int ival_3Bar;int ival_3Foo;...
};由于member function可以被重载化,所以需要更广泛的mangling手法,以提供绝对独一无二的名称。
Virtual Member Functions(虚拟成员函数)
如果normalize()是一个virtual member function,那么以下的调用:
ptr->normalize();将会被内部转化为:
(*ptr->vptr[1])(ptr);其中:
a、vptr表示由编译器产生的指针,指向virtual table。它被安插在每一个“声明有(或继承自)一个或多个virtual functions”的class object中。事实上其名称也会被“mangled”,因为在一个复杂的class派生体系中,可能存在多个vptrs。
b、1时virtual table slot的索引值,关联到normalize()函数。
c、第二个ptr表示this指针。
Static Member Functions(静态成员函数)
在引入static member functions之前,C++语言要求所有的member functions都必须经由该class的object来调用。而实际上,只有当一个或多个nonstatic data members在member function中被直接存取时,才需要class object。Class object提供了this指针给这种形式的函数调用使用。这个this指针把“在member function中存取的nonstatic class members”绑定于“object内对应的members”之上。如果没有任何一个members被直接存取,事实上就不需要this指针,因此也就没有必要通过一个class object来调用一个member function。不过C++语言到目前为止并不能辨识这种情况。
这么一来就在存取static data members时产生了一些不规则性。如果class的设计者把static data member声明为nonpublic(这一直被视为是一种好的习惯),那么他就必须提供一个或多个member functions来存取该member。因此,虽然你可以不靠class object来存取一个static member,但其存取函数却得绑定于一个class object之上。
static member functions的主要特性就是它没有this指针。以下的次要特性统统根源于其主要特性:
1)它不能够直接存取其class中的nonstatic members。
2)它不能够被成名为const、volatile或virtual。
3)它不需要经由class object才被调用——虽然大部分时候它是这样被调用的!
如果取一个static member function的地址,获得的将是其在内存中的位置,也就是其地址。由于static member function没有this指针,所以其地址的类型并不是一个“指向class member function的指针”,而是一个“nonmember函数指针”。
(二)Virtual Member Functions(虚拟成员函数)
每一个class有一个virtual table,内含该class之中有作用的virtual function的地址,然后每个object有一个vptr,指向virtual table的所在。
在C++中,多态表示“以一个public base class的指针(或reference),寻址出一个derived class object”的意思。
识别一个class是否支持多态,唯一适当的方法就是看看它是否有任何virtual function。只要class拥有一个virtual function,它就需要这份额外的执行期信息。
在实现上,首先我们可以在每一个多态的class object身上增加两个members:
a、一个字符串或数字,表示class的类型;
b、一个指针,指向某表格,表格中持有程序的virtual functions的执行期地址。
表格中的virtual functions地址如何被建构起来?在C++中,virtual functions(可经由其class object被调用)可以在编译时期获知。此外,这一组地址是固定不变的,执行期不可能新增或替换之。由于程序执行时,表格的大小和内容都不会改变,所以其建构和存取皆可以由编译器完全掌控,不需要执行期的任何介入。
然而,执行期备妥那些函数地址,只是解答的一半而已。另一半解答是找到那些地址。两个步骤可以完成这项任务:
a.为了找到表格,每一个class object被安插了一个由编译器内部产生的指针,指向该表格。
b、为了找到函数指针,每一个virtual function被指派一个表格索引值。
这些工作都由编译器完成。执行期要做的,只是在特定的virtual table slot(记录着virtual function的地址)中激活virtual function。
一个class只会有一个virtual table。每一个table内含其对应之class object中所有active virtual functions函数实例的地址。这些active virtual functions包括:
a、这一class所定义的函数实例。它会改写(overriding)一个可能存在的base class virtual function函数实例。
b、继承自base class的函数实例。这是在derived class决定不改写virtual function时才会出现的情况。
c、一个pure_virtual_called()函数实例,它既可以扮演pure virtual function的空间保卫者角色,也可以当做执行期异常处理函数(有时候会用到)。
每一个virtual function都被指派一个固定的索引值,这个索引在整个继承体系中保持与特定的virtual function的关系。
当一个class派生自Point时,会发生什么事?例如class point2d:
一共有三种可能性:
a、它可以继承base class所声明的virtual functions的函数实例。正确地说是,该函数实例的地址会被拷贝到derived class的virtual table的相对应slot之中。
b、它可以使用自己的函数实例。这表示它自己的函数实例地址必须放在对应的slot之中。
c、它可以加入一个新的virtual function。这时候virtual table的尺寸会增大一个slot,而新的函数实例地址会被放进该slot之中。
我如何有足够的知识在编译时期设定virtual function的调用呢?
a、一般而言,在每次调用z()时,我并不知道ptr所指对象的真正类型。然而我知道,经由ptr可以存取到该对象的virtual table。
b、虽然我不知道哪一个z()函数实例会被调用,但我知道每一个z()函数地址都被放在slot 4中。
在一个单一继承体系中,virtual function机制的行为十分良好,不但有效率而且很容易塑造出模型来。但是在多重继承和虚拟继承之中,对virtual functions的支持就没有那么美好了。
多重继承下的Virtual Functions
在多种继承中支持virtual functions,其复杂度围绕在第二个及后继的base classes身上,以及“必须在执行期调整this指针”这一点。以下面的class体系为例:
//class 体系,用来描述多重继承(MI)情况下支持virtual function时的复杂度
class Base1{
public:Base1();virtual ~Base1();virtual void speakClearly();virtual Base1 *clone() const;
protected:float data_Base1;
};
class Base2{
public:Base2();virtual ~Base2();virtual void mumble();virtual Base2 *clone() const;
protected:float data_Base2;
};
class Derived :public Base1,public Base2{
public:Derived();virtual ~Derived();virtual Derived *clone() const;
protected:float data_Derived;
};“Derived支持virtual functions”的困难度,统统落在Base2 subobject身上。有三个问题需要解决,以比例而言分别是(1)virtual destructor,(2)被继承下来的Base2::mumble(),(3)一组clone()函数实例。
一条规则是,经由指向“第二或后继之base class”的指针(或reference)来调用derived class virtual function。
所谓thunk是一小段assembly代码,用来(1)以适当的offset值调整this指针,(2)跳转virtual function去。
Thunk技术允许virtual table slot继续内含一个简单的指针,因此多重继承不需要任何空间上的额外负担。Slots中的地址可以直接指向virtual function,也可以指向一个相关的thunk(如果需要调整this指针的话)。于是,对于那些不需要调整this指针的virtual function而言,也就不需要承载效率上的额外负担。
调整this指针的第二个额外负担就是,由于两种不同的可能:(1)经由derived class(或第一个base class)调用,(2)经由第二个(或其后继)base class调用,同一函数在virtual table中可能需要多笔对应的slots。例如:
Base1 *pbase1=new Derived;
Base2 *pbase2=new Derived;delete pbase1;
delete pbase2;虽然两个delete操作导致相同的Derived destructor,但它们需要两个不同的virtual table slots:
1、pbase1不需要调整this指针(因为Base1是最左端base class之故,它已经指向Derived对象的起始处)。其virtual table slot需放置真正的destructor地址。
2、pbase2需要调整this指针。其virtual table slot需要相关的thunk地址。
在多重继承之下,一个derived class内含n-1个额外的virtual tables,n表示其上一层base classes的个数(因此,单一继承讲不会有额外的virtual tables)。对于本例的Derived而言,会有两个virtual tables被编译器产生出来:
1、一个主要实例,与Base1(最左端base class)共享。
2、一个次要实例,与Base2(第二个base class)有关。
针对每一个virtual tables,Derived对象中对应的vptr。vptrs在constructor(s)中被设立初值(经由编译器所产生出来的代码)。
用以支持“一个class拥有多个virtual tables”的传统方法是,将每一个tables以外部对象的形式产生出来,并给予独一无二的名称。例如,Derived所关联的两个tables可能有这样的名称:
vtbl_Derived; //主要表格
vtbl_Base2_Derived; //次要表格于是当你将一个Derived对象地址指定给一个Base1指针或Derived指针时,被处理的virtual table是主要表格vtbl_Derived。而当你将一个Derived对象地址指向给一个Base2指针时,被处理的virtual table是次要表格vtbl_Base2_Derived。
虚拟继承下的Virtual Functions
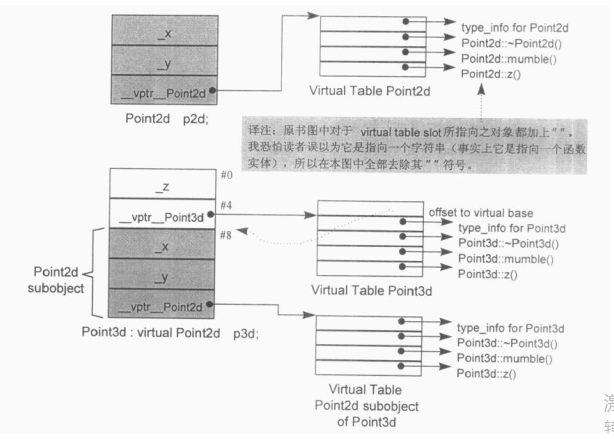
考虑下面的virtual base class派生体系,从Point2d派生出Point3d:
class Point2d{
public:Point2d(float=0.0,float=0.0);virtual ~Point2d();virtual void mumble();virtual float z();// ...
protected:float _x,_y;
};class Point3d:public virtual Point2d{
public:Point3d(float=0.0,float=0.0,float=0.0);~Point3d();float z();
protected:float _z;
};虽然Point3d有唯一一个(同时也是最左边的)base class,也就是Point2d,但Point3d和Point2d的起始部分并不像“非虚拟的单一继承”情况那样一致。这种情况显示于下图。由于Point2d和Point3d的对象不再相符,两者之间的转换也就需要调整this指针。至于在虚拟继承的情况下要消除thunks,一般而言已经被证明是一项高难度技术。
(三)函数的效能
多重继承中的virtual function的调用,似乎用掉了较多的成本,这令人感到困惑。当有人期望编译器实现出thunk模型以调用第二个或后继的base class的virtual function,而用来测试的这两个编译器却不支持thunk技术时,就会得到这种结果。由于this指针的调整已经施行于单一继承和多重继承中,其额外负担不能用来解释这项成本。
在单一继承情况下执行测试时,每多一层继承,virtual function的执行时间就有明显的增加。不管单一继承的深度如何,主循环中用以调用函数的代码事实上是完全相同的;同样的道理,对于数据的处理也是完全相同的。其间的不同,就是cross_product()中出现的局部性Point3d class object pC 。增加继承深度,就多增加执行成本,这一事实上反应出PC身上的constructor的复杂度。这也能够解释为什么多重继承的调用另有一些额外负担。
导入virtual function之后,class constructor将获得参数以设定virtual table指针。CC和NCC都不能够把这个设定操作在“无任何virtual function的base class”建构时优化,所以每多一层继承,就会多增加一个额外的vptr设定。
在这些编译器中,每一个额外的base class或额外的单一继承层次,其constructor内会被加入另一个对this指针的测试。若执行这些constructor 1000万次,效率就会因此下降至可以测试的程度。这种效率表现明显反映出一个编译器的反常,而不是对象模型的不正常。
(四)指向Member Function的指针
取一个nonstatic data member的地址,得到的结果是该member在class布局中的bytes位置(再加1)。它是一个不完整的值,它需要被绑定于某个class object的地址上,才能够被存取。
取一个nonstatic member function的地址,如果该函数是nonvirtual,得到的结果是它在内存中真正的地址。然而这个值也是不完全的。它也需要被绑定于某个class object的地址上,才能够通过它调用该函数。所有的nonstaic member functions都需要对象的地址(以参数this指出)。
指向member function的指针的声明语法,以及指向“member function运算符”的指针,其作用是作为this指针的空间保留者。这也就是为什么static member functions(没有this指针)的指针是“函数指针”,而不是“指向member function的指针”之故。
使用一个“member function指针”,如果并不用于virtual function、多重继承、virtual base class等情况的话,并不会比使用一个“nonmember function指针”的成本更高。上述三种情况对于“member function指针”的类型以及调用都太过复杂。事实上,对于那些没有virtual functions、virtual base class或multiple baseclasses的classes而言,编译器可以为它们提供相同的效率。
支持“指向Virtual Member Functions”的指针
考虑下面的程序片段:
float (Point::*pmf)()=&Point::z;
Point *ptr= new Point3d;pmf,一个指向member function的指针,被设值为Point::z()(一个virtual function)的地址。ptr则被指定以一个Point3d对象。如果我们直接经由ptr调用在z():
ptr->z();被调用的是Point3d::z()。但如果我们从pmf间接调用z()呢?
(ptr->*pmf)();仍然是Point3d::z()被调用?也就是说,虚拟机制仍然能够在使用“指向member function之指针”的情况下运行吗?答案是yes,问题是如何实现呢?
例如,假设我们有以下的Point声明:
class Point
{
public:virtual ~Point();float x();float y();virtual float z();//...
};对一个nonstatic member function取其地址,将获得该函数在内存中的地址。然而面对一个virtual function,其地址在编译时期是未知的,所能知道的仅是virtual function在其相关之virtual table中的索引值。也就是说,对一个virtual member function取其地址,所能获得的只是一个索引值。
对一个“指向member function的指针”评估求值,会因为该值有两种意义而复杂化;其调用操作也将有别于常规调用操作。pmf的内部定义,也就是:float (Point::*pmf)();
必须允许此函数能够寻址出nonvirtual x()和virtual z()两个member functions,而那两个函数有着相同的原型:
//两者都可以被指定给pmf
float Point::x(){return _x;}
float Point::z(){return 0;}只不过其中一个代表内存地址(一长串),另一个代表virtual table中的索引值(一小段)。因此,编译器必须定义pmf,使它能够(1)持有两种数值,(2)更重要的是其数值可以被区别代表内存地址还是virtual table中的索引值。
在多重继承之下,指向Member Functions的指针
为了让指向member functions的指针也能够支持多重继承和虚拟继承,Stroustrup设计了下面一个结构体:
//一般结构,用以支持在多重继承之下指向member functions的指针
struct _mptr{int delta;int index;union{ptrtofunc faddr;int V_offset;};
};index和faddr分别(不同时)持有virtual table索引和nonvirtual member function地址(为了方便,当index不指向virtual table时,会被设为-1)。在此模型之下,像这样的调用操作:(ptr->*pmf)();
会变成:
(pmf.index<0)
?//non-virtual invocation
(*pmf.faddr)(ptr)
://virtual invocation
(*ptr->vptr[pmf.index](ptr));此法所受到的批评是,每一个调用操作都得付出上述成本,检查其是否为virtual或nonvirtual。Microsoft把这项检查拿掉,导入一个它所谓的vcall thunk。在此策略之下,faddr被指定的要不就是真正的member function地址(如果函数是nonvirtual的话),要不就是vcall thunk的地址。于是virtual或nonvirtual函数的调用操作透明化,vcall thunk会选出并调用相关virtual table中的适当slot。
这个结构体的另一个副作用就是,当传递一个不变值的指针给member function时,它需要产生一个临时性对象。
(五)Inline Functions
实际上我们并不能够强迫将任何函数都编程inline。关键字inline(或者class declaration中的member function或friend function的定义)只是一项请求。如果这项请求被接受,编译器就必须认为它可以用一个表达式合理地将这个函数扩展开来。
当我说“编译器相信它可以合理地扩展一个inline函数”时,我的意思是在某个层次上,其执行成本比一般的函数调用及返回机制所带来的负荷低。
一般而言,处理一个inline函数,有两个阶段:
1、分析函数定义,以决定函数的“intrinsic inline ability”(本质的inline能力)。“intrinsic”(本质的、固有的)一词在这里意指“与编译器相关”。
如果一个函数因其复杂度,或因其构建问题,被判断不可成为inline,它会被转为一个static函数,并在“被编译模块”内产生对应的函数定义。在一个支持“模块个别编译”的环境中,编译器几乎没有什么权宜之计。理想情况下,链接器会被产生出来的重复东西清理掉。然而一般来说,目前市面上的链接器并不会讲“随此调用而被产生出来的重复调试信息”清理掉。
2、真正的inline函数扩展操作是在调用的那一点上。这会带来参数的求值操作以及临时性对象的管理。
形式参数(Formal Arguments)
在inline扩展期间,每一个形式参数都会被对应的实际参数取代。如果说副作用,那就是不可以只是简单地一一封塞程序中出现的每一个形式参数,因为这将导致对于实际参数的多次求值操作。一般而言,面对“会带来副作用的实际参数”,通常都需要引入临时性对象。换句话说,如果实际参数是一个常量表达式,我们可以在替换之前先完成其求值操作;后继的inline替换,就可以吧常量直接“绑”上去。如果既不是常量表达式,也不是个带有副作用的表达式,那么就直接代换之。
局部变量(Local Variables)
一般而言,inline函数中的每一个局部变量都必须被放在函数调用的一个封闭区段中,拥有一个独一无二的名称。如果inline函数以单一表达式扩展多次,则每次扩展都需要自己的一组局部变量。如果inline函数以分离的多个式子被扩展多次,那么只需一组局部变量,就可以重复使用。
inline函数中的局部变量,再加上有副作用的参数,可能会导致大量临时性对象的产生。特别是如果它以单一表达式被扩展多次的话。
Inline函数对于封装提供了一种必要的支持,可以有效存取封装于class中的nonpublic数据。它同时也是C程序中大量使用的#define(前置处理宏)的一个安全代替品——特别是如果宏中的参数有副作用的话。然而一个inline函数如果被调用太多次的话,会产生大量的扩展码,使程序大小暴涨。
参考资料:《深度探索C++对象模型》
这篇关于深度探索C++对象模型(四)Function语意学的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





