本文主要是介绍白宫版“潜伏”,数据分析锁定副总统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
中期选举前,特朗普政府上演了一场“潜伏”版“水门事件”,而由于一位程序员及其在GitHub上发布的行文风格相关性分析,这位匿名告密者的身份被迅速锁定在副总统身上。
这次的结果也似乎会与当年的尼克松大有不同。
先来看看事情的经过。
9月5日,《纽约时报》发表了一封匿名来信《我是特朗普政府中的一名抵抗者》,作者自称特朗普总统身边的高管,对特朗普的执政大肆批评并揭露了不少白宫内幕,称政府内部存在针对特朗普的“抵抗力量”。来信中他表示,为了美国的利益,自己一直“潜伏”在总统身边,让总统的很多错误决定无法执行。
《纽约时报》表示已经确认了该高官身份,但是为了保护他,选择了匿名发布这篇文章。

纽约时报报道
纽约时报报道链接:
https://cn.nytimes.com/opinion/20180906/trump-white-house-anonymous-resistance/
尽管自特朗普上台以来,反对之声就一直不绝入耳。但这次曝光者自称来自特朗普身边高层,且自称正百般阻挠各种政策实施。并且特朗普还不知道他是谁。这让特朗普大为光火。
纽约时报报道配图
文章发布后,特朗普迅速在推特上高呼“谋反(TREASON?)”,要求《纽约时报》把这个胆小的匿名者交给政府。

这件事到此或许还是停留在政府层面的一场闹剧。但是很快,事情就发生了新转机。
几天前,一位名叫Michael W. Kearney的程序员在GitHub公布了一个脚本,用神经网络,将这封来信的行文风格和用词与每个白宫高管的推特文本进行了分析对比,并分别求出了相关系数。
Github链接
https://github.com/mkearney/resist_oped/blob/master/README.md
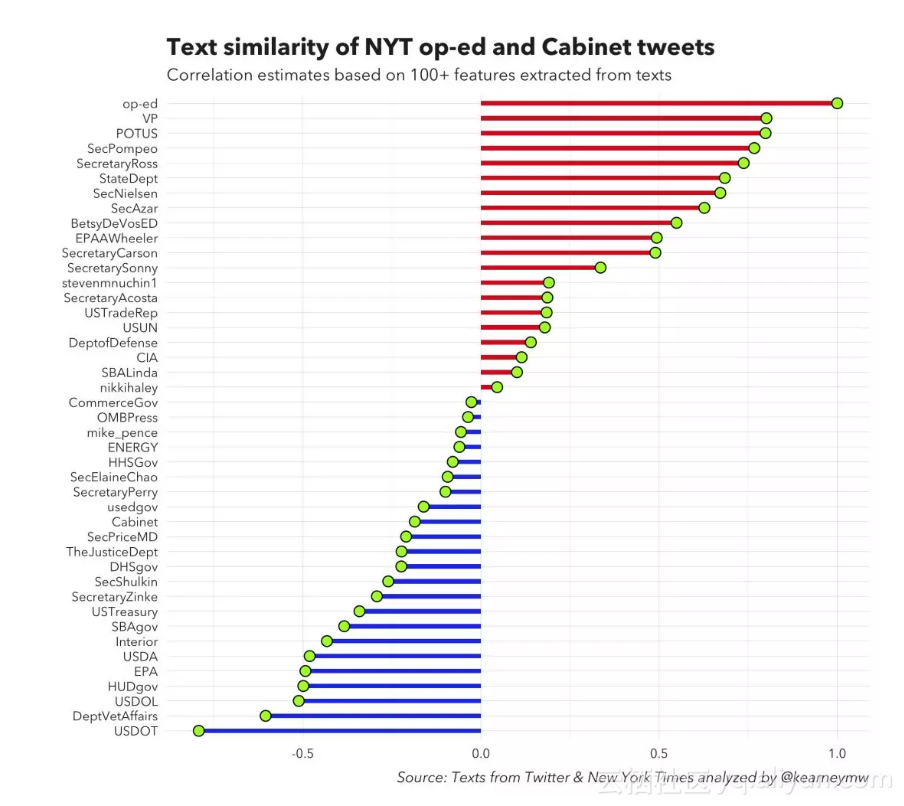
运行结果是副总统(VP, Vice President)的相关系数最高。
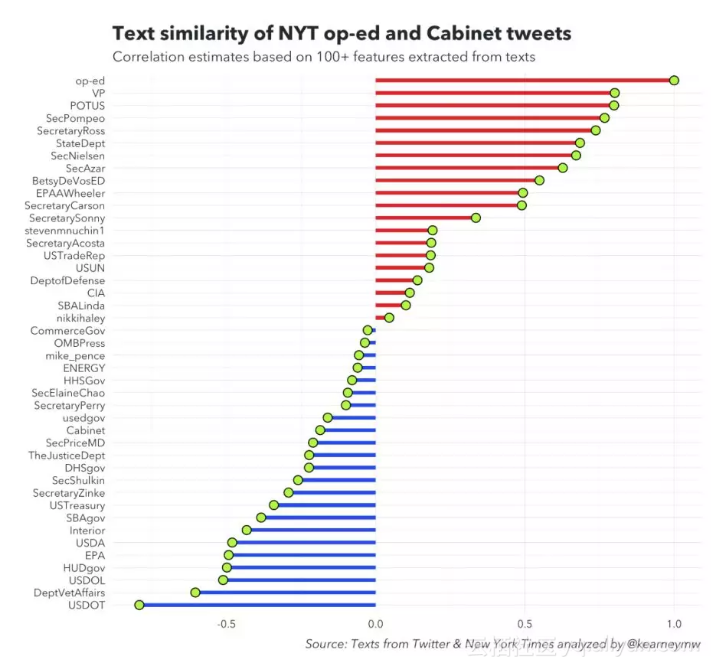
GitHub上的这一分析结果和白宫的某些调查不谋而合。据美联社报道,白宫有分析结果称,评论文章中出现了“lodestar”这一不常见词汇,正是美国副总统经常使用的语言,一些人因而猜测彭斯是匿名作者。
接下来,事件矛头直指美国副总统迈克·彭斯。
为证清白,彭斯在接下来的几日做客两档电视节目,说愿接受测谎仪检测,同时为属下作担保,愿意接受任何政府审核。
当然,也有人称,在GitHub公布的分析结果可以看出,特朗普的系数0.798661比副总统的系数0.801063差距非常小,这是否是中期选举前特朗普自导自演的一出大戏还不得而知。
这位让副总统伤脑筋的程序员也并非等闲之辈。
从GitHub的个人主页可以看出,Michael W. Kearney的真实身份是密苏里大学新闻学院的副教授,同时也在学校信息学院任职,教授大众媒体、政治传播、定量研究方法和数据科学课程。
目前的研究重点正是在新媒体环境中的党派选择性曝光,可以说是一位兼具新闻传播知识和程序技能的大咖。
Michael W. Kearney的research gate的主页介绍

Michael W. Kearney在密苏里大学的个人主页https://mikewk.com/
或许这次,程序员真的要拯救世界了。
最后,附上Michael W. Kearney在GitHub上发布的这篇手稿。
原文链接
https://github.com/mkearney/resist_oped/blob/master/resist-oped-text-similarity.md
题目:使用数据科学识,推测谁撰写了《纽约时报》关于特朗普政府内部抵抗的专栏文章
昨天,“纽约时报”发表了一篇关于白宫内部抵抗的评论文章。它是由一位匿名作者撰写的,这名作者被称为“特朗普政府的一名高级官员”。
很多人都在猜测撰写这篇专栏文章的作者,早期猜测的线索是“lodestar”这个词的使用。据悉,副总统迈克·彭斯经常使用这个词。其他人则认为,匿名作者故意往彭斯身上泼脏水。
我们可能永远不知道是谁真正撰写了这篇文章。但是,就目前而言,我想指出的是,虽然分析白宫高级官员的沟通模式是有据可循的,但这样做却忽视了数据科学的最新进展。
那么,可以通过过去的通信记录来帮助识别匿名作者吗?
其实数字媒体和数据科学现有技术,使我们可以在相对较短的时间内获得(无论是否准确)见解。而且由于我做的很多工作都涉及到分析Twitter上所展示的政治沟通,我想我会试着用它来展示一些数据科学培训案例,这仅仅需要大量数据和一点时间。
分析过程
首先,我从纽约时报专栏中获取了文本。
1、我收集了专栏文本
接下来,因为我需要一些样本来与专栏的文本进行比较,所以我转向Twitter。由于时间的缘故,我决定将我的分析范围锁定在总统内阁成员身上。
2、我从使用推特的特朗普“内阁”那里收集了最新的3,200条推文
通过参考文本和Twitter推文样本,之后我逐段拆分专栏文本,大致匹配推文的长度。
3、我将专栏文本分成段落
使用与名称或“op-ed”的作者进行匹配,然后为每个文本字符串提取了超过100个特征。这些特征包括大写、标点符号(逗号、句号、感叹号等)、空格的使用、单词长度、句子长度、'待成'动词的使用、以及词维度的大量词库表示,这类似于将常用单词划分为八十个不同的主题,然后测量每个文本使用相关主题的单词程度。
4、我将每个文本转换为107个数字要素
最后,为了对op-ed和名称之间的相似性进行实际测量,我平均了作者所特有的数字,然后使用这些值来估计专栏文本和Twitter用户文本(关联度量范围从-1到1)之间的相关性。
5、我估计了专栏文本和每个内阁成员帐户发布的推文之间的相关性
你可以找到我在Github上使用的代码。这是相关系数的直观表示:
分析局限性
本实践有助于说明,如何使用数据科学来估计多个文本之间的相似性,但它没有提供任何确凿的证据来回答谁是撰写“纽约时报”专栏文章的作者。
事实上,有很多理由说明为什么人们应该对这种分析所做的推论持怀疑态度。我将在接下来的几段中描述其中的一些限制。
首先,比较文本是有限的。因为它们是为Twitter而不是纽约时报设计的。他们也是由用户撰写的,他们的身份可能与他们的推文相关联。
其次,比较文本库但没有考虑所有的可能选择。例如,这没有考虑“不使用Twitter的内阁成员”。它也省略了任何在特朗普政府工作但不是内阁正式成员的人。
第三,文本相似性分析假设:匿名专栏作者没有尝试伪装自己的沟通模式。即使他们确实试图伪装自己,一些沟通模式可能不予考虑。一些误导的线索,例如“lodestar”词的使用,可能导致许多算法错误推测。
第四,假设撰写推文的人是他们声称代表的实际人。例如,我们有理由相信特朗普并没有操作@POTUS帐户,但情况具体如何,我们不得而知。一些内部通信人员也完全有可能影响推文消息的发送。或者,主管部门可能会有重叠的沟通模式。因此,在白宫工作的人员都会有一些近似的匹配。
原文发布时间为:2018-09-15
本文作者:文摘菌
本文来自云栖社区合作伙伴“大数据文摘”,了解相关信息可以关注“大数据文摘”。
这篇关于白宫版“潜伏”,数据分析锁定副总统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!