本文主要是介绍2022年30m全国逐年土地覆被数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.研究背景
2023年8月,武汉大学杨杰和黄昕教授团队向公众更新发布了CLCD 2022年全国土地覆数据(V1.0.2)。而CLCD 2021年全国土地覆数据(V1.0.1)也是在去年8月向公众更新发布。
中国在过去几十年中经济和人口迅速发展,土地覆盖随之发生巨大变化,因此迫切需要对其进行连续和精细的监测。然而,由于缺乏足够的训练样本和计算能力,基于卫星遥感观测数据的中国年度土地覆盖数据集还比较匮乏。
武汉大学的杨杰和黄昕教授团队基于Google Earth Engine上335,709景Landsat影像制作了中国逐年土地覆盖数据集(annual China Land Cover Dataset, CLCD),包含1985—2019中国逐年土地覆盖信息。为此,研究团队基于GEE上所有可获得的Landsat数据,构建时空特征,结合随机森林分类器得到分类结果,并提出一种包含时空滤波和逻辑推理的后处理方法进一步提高CLCD的时空一致性。最后,基于5,463个目视解译样本,CLCD的总体精度达80%。此外将CLCD与现有的土地覆被专题产品相互比较,发现CLCD与全球森林变化、全球地表水和不透水面时序数据集表现出良好的一致性。
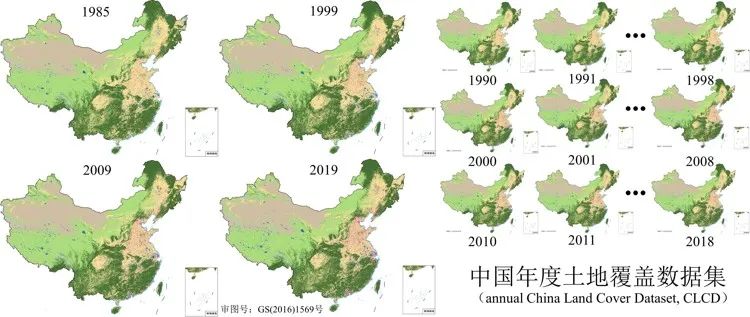
2021年6月,研究团队发布CLCD 1985-2019年逐年土地覆被数据;同年8月,发布CLCD 2020年全国土地覆被数据。2022年8月,杨杰和黄昕教授团队向公众发布了C
这篇关于2022年30m全国逐年土地覆被数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






