本文主要是介绍[VSOD] UFO: A Unified Transformer Framework for CoS, CoSD, VSOD,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
A Unified Transformer Framework for Group-based Segmentation: Co-Segmentation, Co-Saliency Detection and Video Salient Object Detection
https://github.com/suyukun666/UFO
https://arxiv.org/abs/2203.04708
Introduction
co-segmentation (CoS) 协同分割:从包含共同对象(往往也称为前景)的图像组中分割出共同对象
co-saliency detection (CoSD) :与CoS类似,但是CoSD旨在模拟人类视觉系统,从而找出视觉上最显著的区域

video salient object detection (VSOD)
传统:
Geodesic saliency using background priors ECCV2012
Saliency-aware video object segmentation 2017
Video salient object detection via robust seeds extraction and multi-graphs manifold propagation 2019
Improving video saliency detection via localized estimation and spatiotemporal refinement 2018
3D卷积:
Learning spatiotemporal features with 3d convolutional networks 2015
Making a case for 3d convolutions for object segmentation in videos 2020
光流:
Full-duplex strategy for video object segmentation 2021
Video salient object detection via robust seeds extraction and multi-graphs manifold propagation 2019
Semisupervised video salient object detection using pseudo-labels 2019
注意力:
Shifting more attention to video salient object detection 2019
Pyramid constrained self-attention network for fast video salient object detection 2020
Method
本文提出了一个联合框架UFO,可以统一上述三种任务

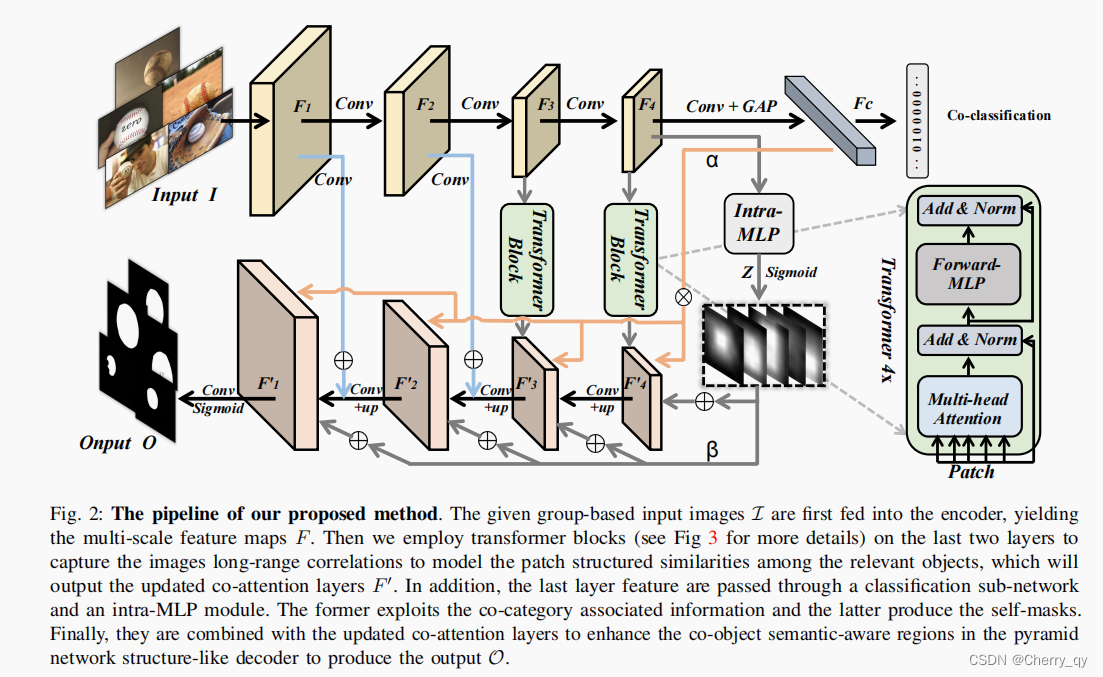
Architecture
encoder:VGG16,得到多尺度特征
最后两层后面接transformer block:
matching the co-objects similarities, producing the enhanced co-attention maps
intra-MLP & co-category semantic guidance:结合decoder中的特征,增强co-object 区域
co-category embedding response α 通过相乘应用到decoder中的特征上
intra self-masks β 则是加到decoder中的特征上
transformer block
以F4后接的transformer block为例,首先将F4(B*N*C*h*w)reshape成一系列tokens(B*C*P),然后是输入到transformer block中。
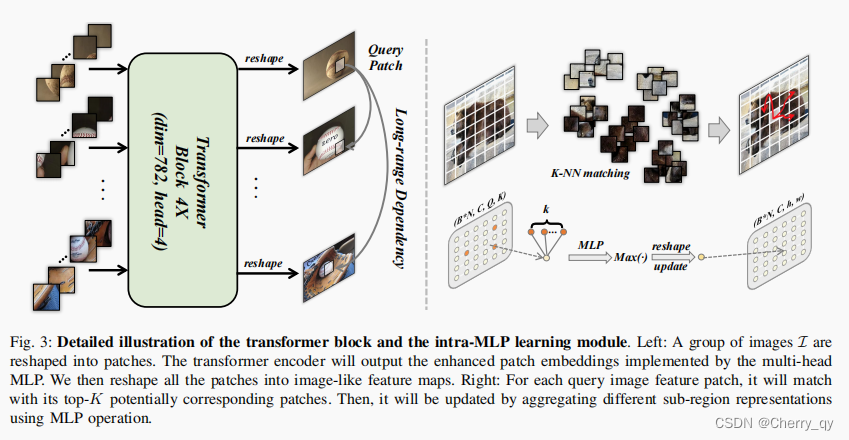
图4展示了transformer block学到的信息,第一行是输入图像,第二行是在输入transformer block之前的特征图,第三行是经过transformer block之后的特征,可以看到经过transformer block之后,目标区域变得更加清晰。
第四行是选中的patch对应的注意力图,包括香蕉的尾端和企鹅的头部。
可以看到transformer block可以在不同的位置像素上进行长期依赖关系的建模。

Intra-MLP
Transformer block关注的是图像之间的相关性,intra-MLP关注的是单张图像内部的目标区域。
encoder顶层的特征图可以被看成是不同的patches。
考虑到每个patch的信息不仅与相邻的patch相关,距离较远的patch之间可能也有相似的特征,因此我们结合了非局部的语义信息来增强目标特征。
首先将F4 (B*N*C*h*w)reshape成F4-(B*N*C*Q),然后构建一个矩阵M(B*N*Q*Q)来表示单张图像中每个patch之间的相似度。利用L2-distance来衡量任意两个patch之间的关系。
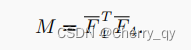
M的对角线元素设置为-∞,避免自己与自己匹配。
对于每一个query patch,我们在矩阵上使用KNN来匹配出对应的目标,然后输出一个tensor(Q*K)表示top-K语义相关的patches,从而得到F4 ~ (B*N*C*Q*K)。
然后利用MLP和MAX( element-wise maximum)操作来得到更新后的特征Z(B*N*C*Q)。
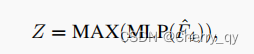
这一步的目的是将目标特征与其top-K特征的特征信息相结合,并通过感知机进行学习。
最后reshape Z并进行sigmoid来得到self-masks β。

co-category semantic guidance
将F4输入进一个卷积层和一个GAP层,生成一个向量α。
FC层对embedding α进行分类,来得到co-category labels y~。
然后将co-category embedding response α 和 self-masks β 作为 learned scale modulation parameters(通过使用丰富的语义感知线索来排除co-object区域中的干扰物)和 bias parameters(通过赋予空间感知信息来补充和突出目标目标)作用到decoder上。
解码器利用跳跃连接结构来融合来自编码器的低分辨率层特征。
损失函数
类别损失(语义信息):交叉熵
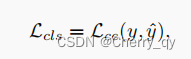
Weighted Binary Cross-Entropy (WBCE) loss(像素级别的分割):

IoU loss(评估分割的精度):
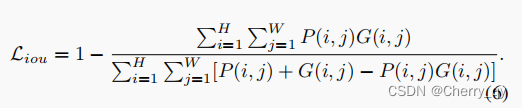
损失函数:

数据集:
four CoS benchmarks (PASCAL, iCoseg, Internet and MSRC)
three CoSD benchmarks (Cosal2015, CoSOD3k, and CocA)
four VSOD benchmarks (DAVIS16, FBMS, ViSal and SegV2)
评估指标:
object co-segmentation:Precision (P) and Jaccard index (J )
co-saliency detection and video salient object detection:
mean absolute error MAE, F-measure Fβ, E-measure Em, and S-measure Sm
消融实验
CoS (PASCAL-VOC and iCoseg) datasets
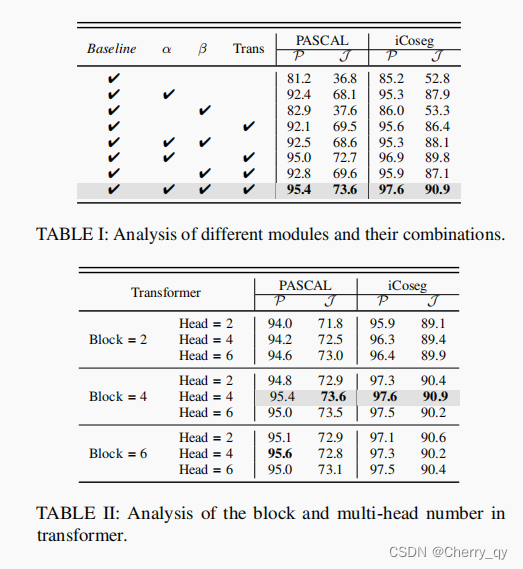
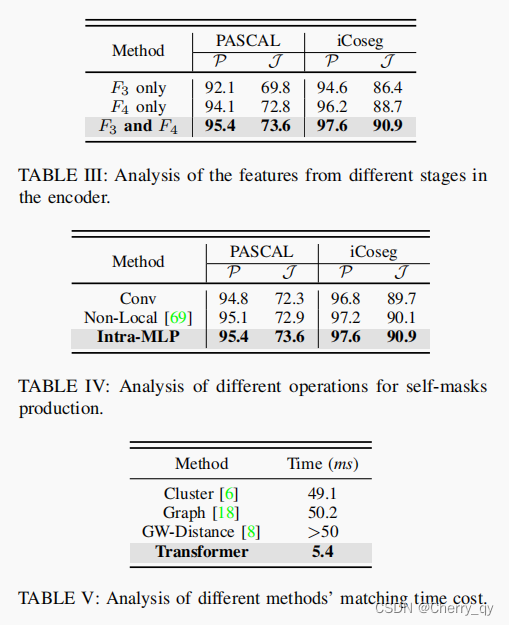
表5:
transformer不仅能够更好地建模长距离依赖性,而且在速度上取得了最好的性能。
实验
co-segmentation
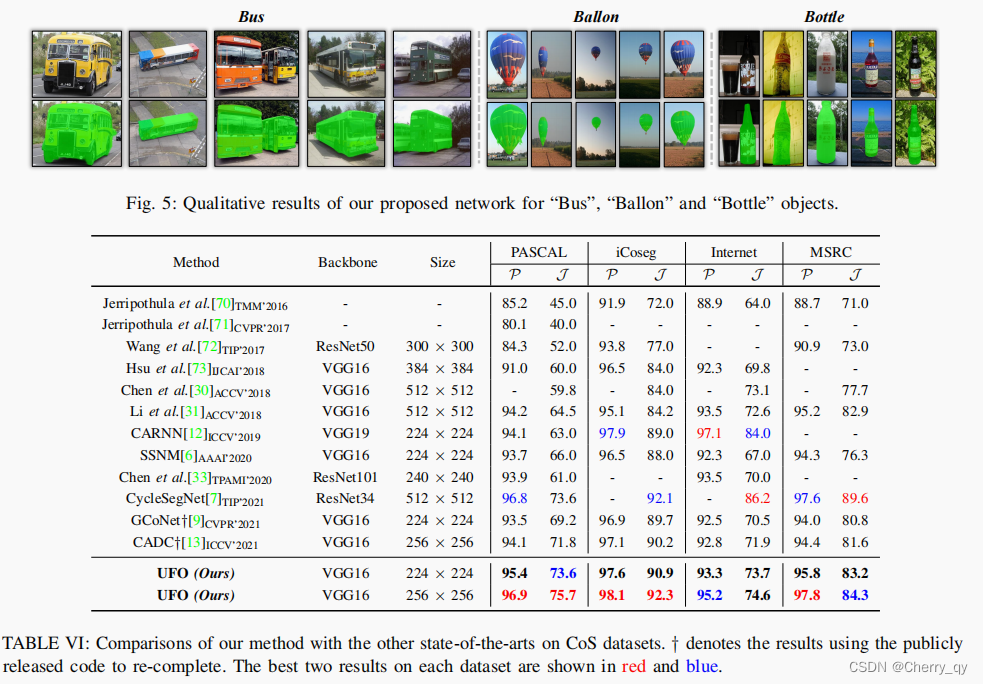
co-saliency detection

video salient object detection
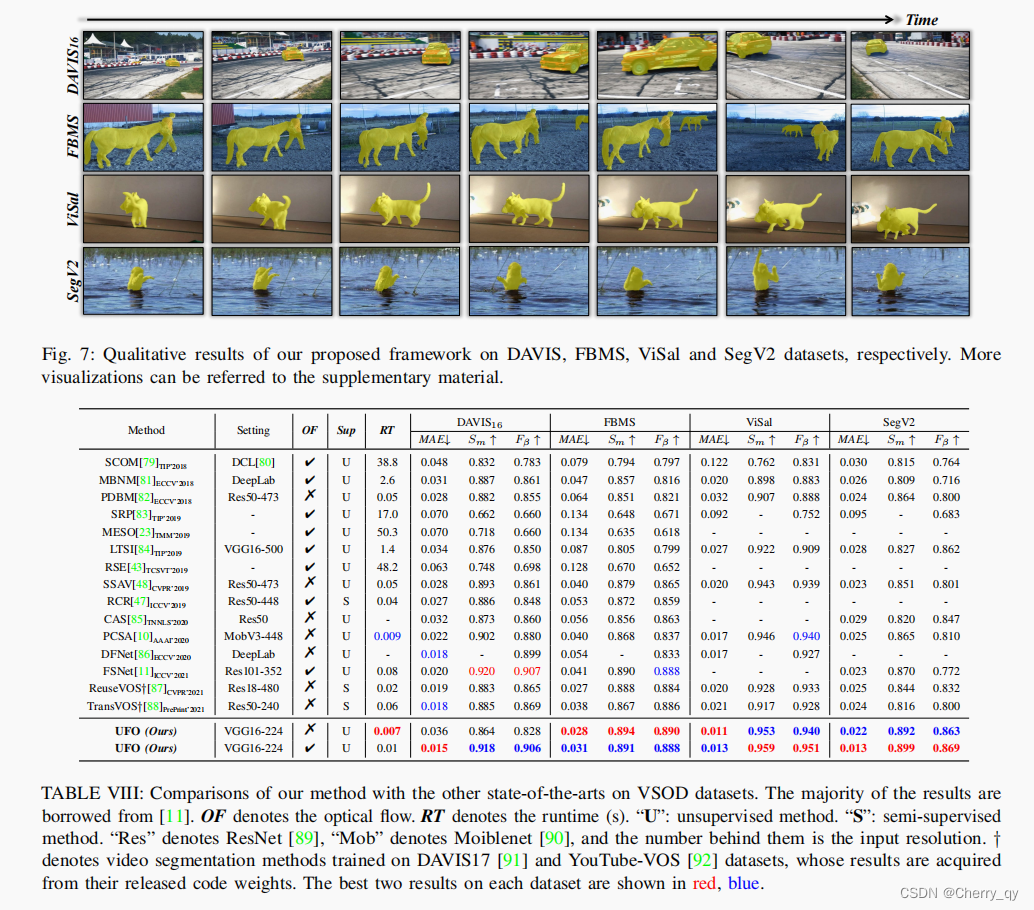
这篇关于[VSOD] UFO: A Unified Transformer Framework for CoS, CoSD, VSOD的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








