本文主要是介绍(Python学习)爬虫——爬取虎牙直播网站主播名字和人气,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
获得不同类型游戏直播间的主播名字和人气,只需要修改url的最后面地址,下面加粗黑色字体。
https://www.huya.com/g/wzry
"""
爬取虎牙直播不同游戏类型的主播及人气(仅学习使用)
"""
import re
from urllib import requestclass Spider:#对应虎牙游戏直播间ip地址url = 'https://www.huya.com/g/wzry'#正则表达式root_pattern = '<span class="avatar fl">([\s\S]*?)</span><span class="num">([\s\S]*?)</span>'name_pattern = '<i class="nick" title="([\s\S]*?)">([\s\S]*?)</i>'number_pattern = '<i class="js-num">([\s\S]*?)</i>'#爬取整个HTMLdef __fetch_content(self):r = request.urlopen(Spider.url)htmls = r.read()htmls = str(htmls, encoding='utf-8')return htmls#提取html中的信息def __analysis(self, htmls):htmls = re.findall(Spider.root_pattern, htmls)anchors = []for x in htmls:name = re.findall(Spider.name_pattern, str(x))number = re.findall(Spider.number_pattern, str(x))anchors.append({'name':name[0], 'number':number})return anchors#对提取的html信息进行过滤def __refine(self, htmls):l = lambda x : {'name':x['name'][0].strip(), 'number':x['number'][0].strip()}r = map(l, htmls)return list(r)#排序def __sort(self, htmls):htmls = sorted(htmls, key=self.__sort_seed, reverse=True)return htmls#排序的key设定def __sort_seed(self, htmls):r = re.findall('\d*',htmls['number'])number = float(r[0])*10000 + float(r[2])*1000return number#展示信息def __show(self, htmls):for rank in range(0, len(htmls)):print("rank:"+str(rank)+" name:"+htmls[rank]['name']+"------"+htmls[rank]['number'])#main函数def go(self):htmls = self.__fetch_content()htmls = self.__analysis(htmls)htmls = self.__refine(htmls)htmls = self.__sort(htmls)self.__show(htmls)spider = Spider()
spider.go()
效果如下:
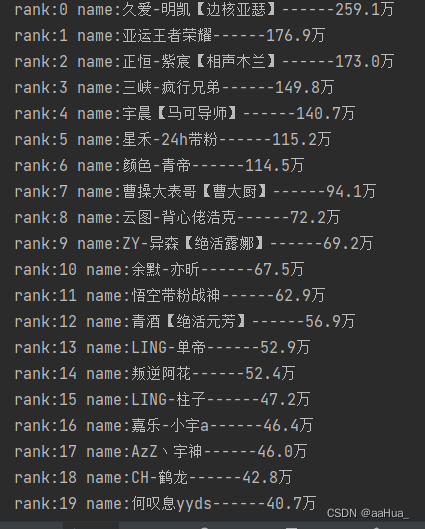
这篇关于(Python学习)爬虫——爬取虎牙直播网站主播名字和人气的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




