本文主要是介绍python爬取统计局数据第一弹,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、python爬取实战步骤
(一)网站相关信息的查询
(二)分析网页结构
(三)避开陷阱
(四)开始爬虫
(五)数据预处理
(六)总体代码
二、python爬取过程中可能遇到的问题及解决方案
Q:怎样在pycharm中安装所需要的库?
Q:CMD命令行下如何切换路径?
Q:Python 安装beautifulsoup4库步骤?
Q:怎么安装Jupyter Notebook?
三、参考引用
前言:
第一,本博客为本人进行爬虫联系所作,所爬取数据为国家统计局公开数据,仅是个人学习使用。第二,爬虫所爬取的内容受严格限制,可参考我之前的博客,请勿在违法犯罪边缘试探。第三,配备环境说明:jupyter notebook(交互式感觉对爬虫来说更方便)与Chrome浏览器。
一、python爬取实战步骤
(一)网站相关信息的查询
浏览器输入: https://data.stats .gov.cn/easyquery.htm?cn=A01打开如下图所示,红框内容就是我们目标内容:

(二)分析网页结构
① 按F12,或打开开发者工具,出现如下页面:
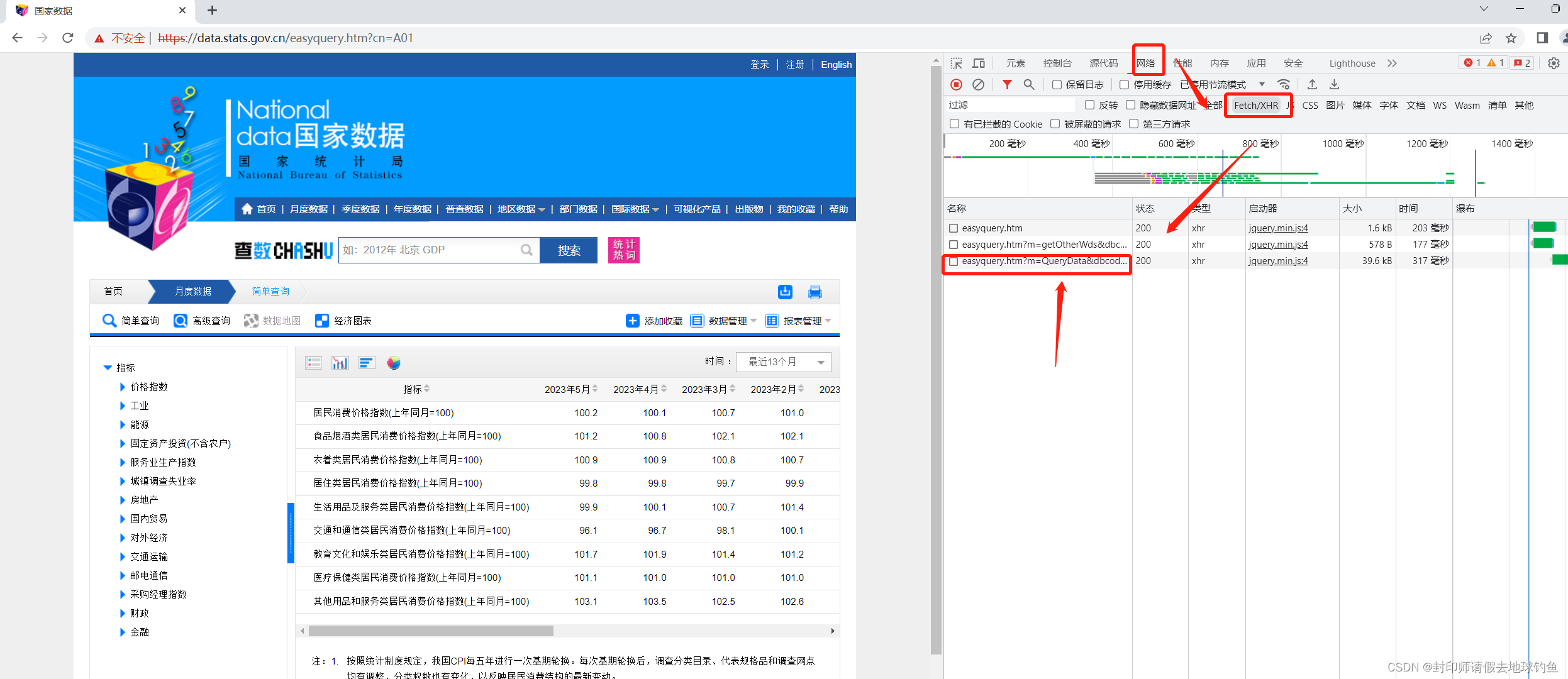
需要点击箭头指向的NetWork,然后在下面找到XHR,之后的页面才如上图所示。
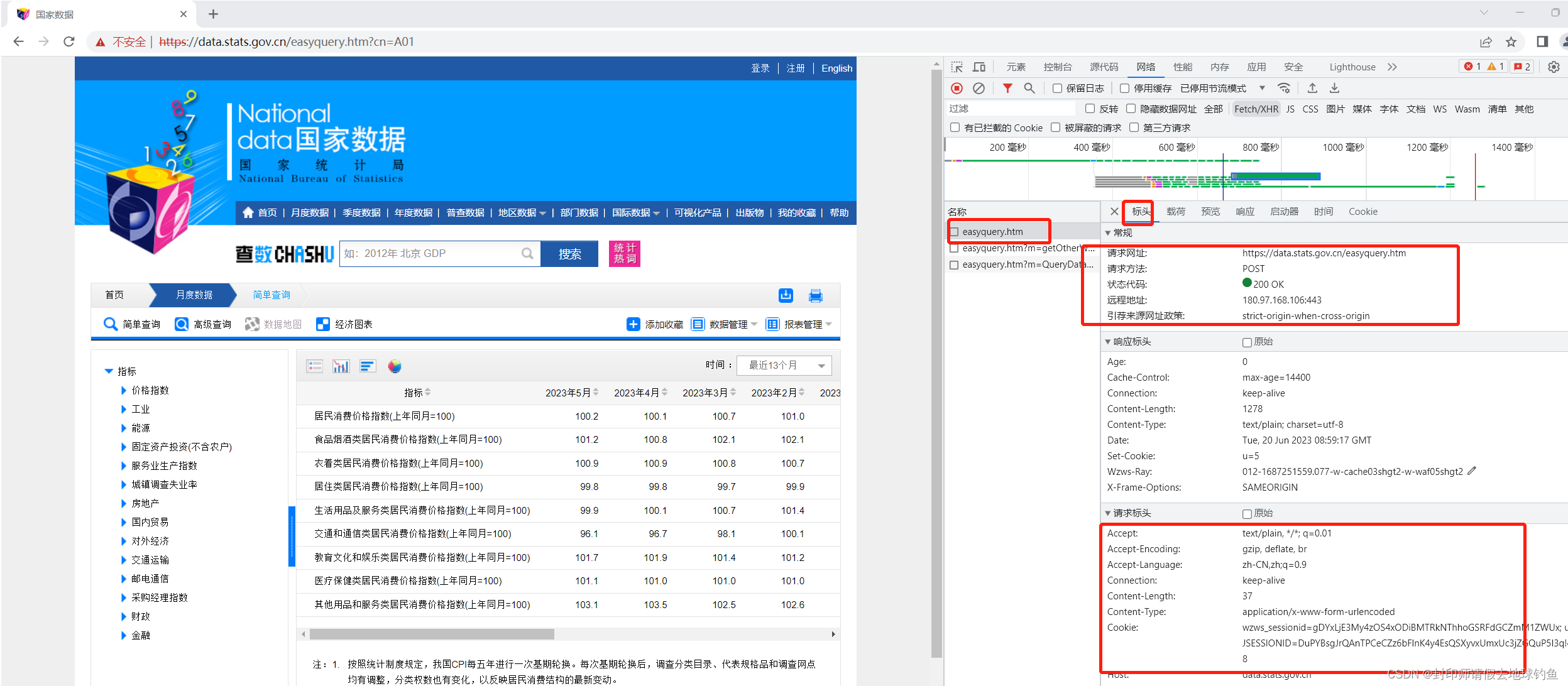
②点开第一个可以发现诸如URL、状态码之类的,的Query String Parameters,则在第二个页面:
③依次点开剩下的两个
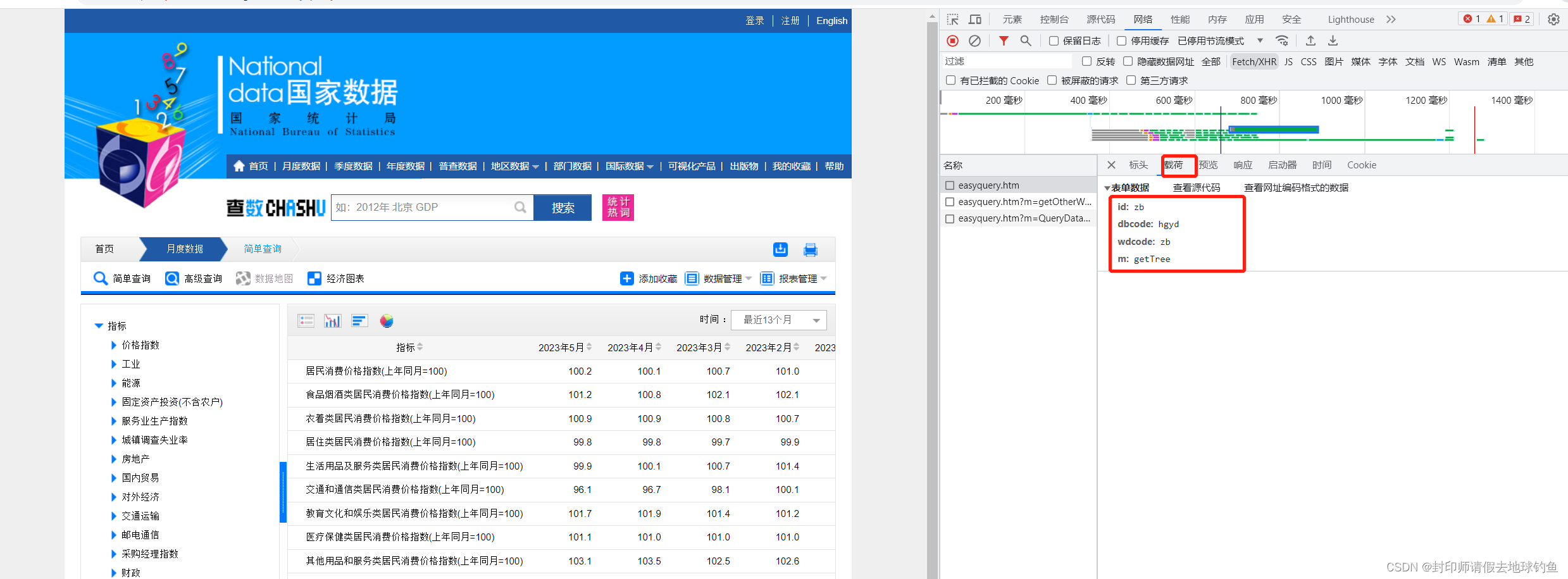
第二个的URL和Query String Parameters分别是:
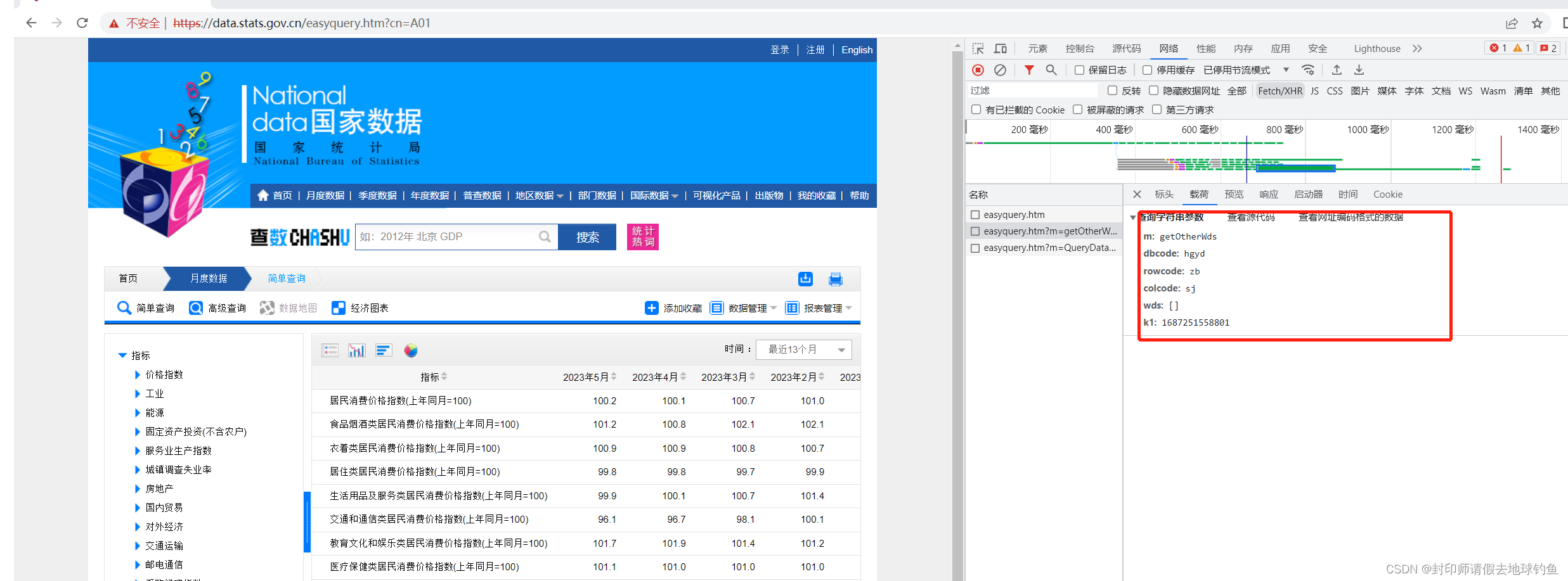
第三个URL和Query String Parameters分别是:
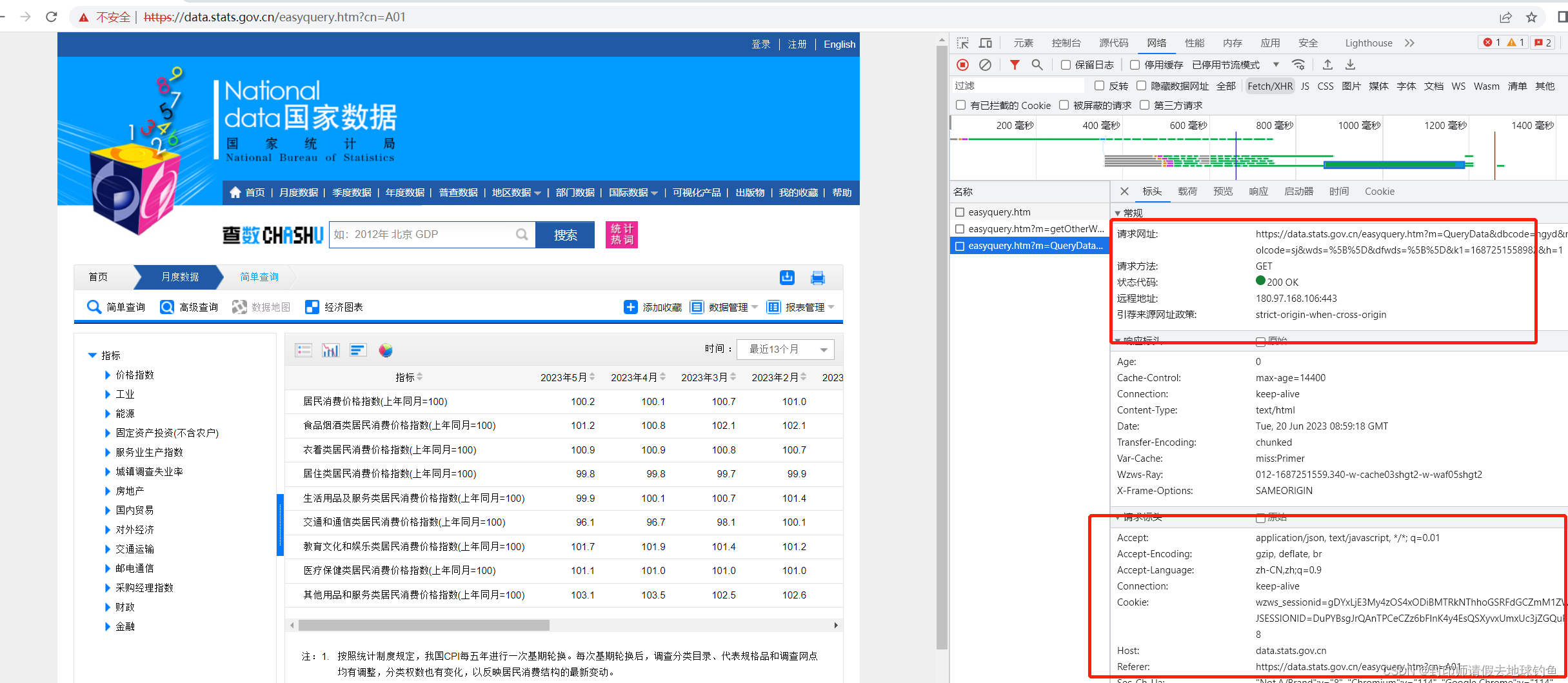
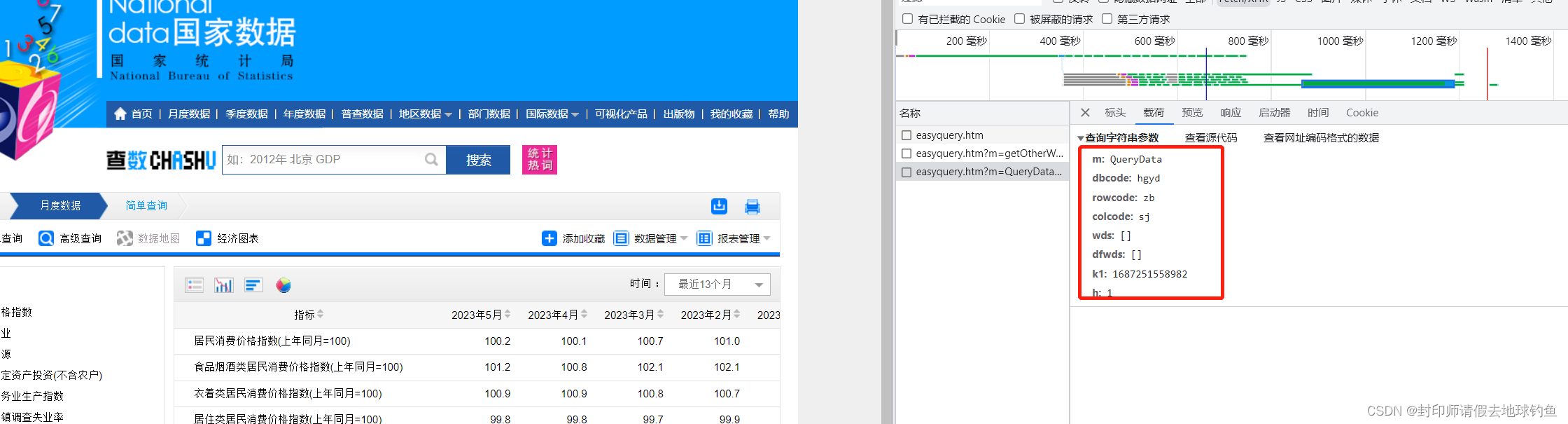
通过分析第二个和第三个我们发现,它们的前面部分是一样的,即http://data.stats.gov.cn/easyquery.htm,问号后面的内容虽然不一样,但是和自己Query String Parameters里面的内容一样。问号后面是传给服务器的参数。
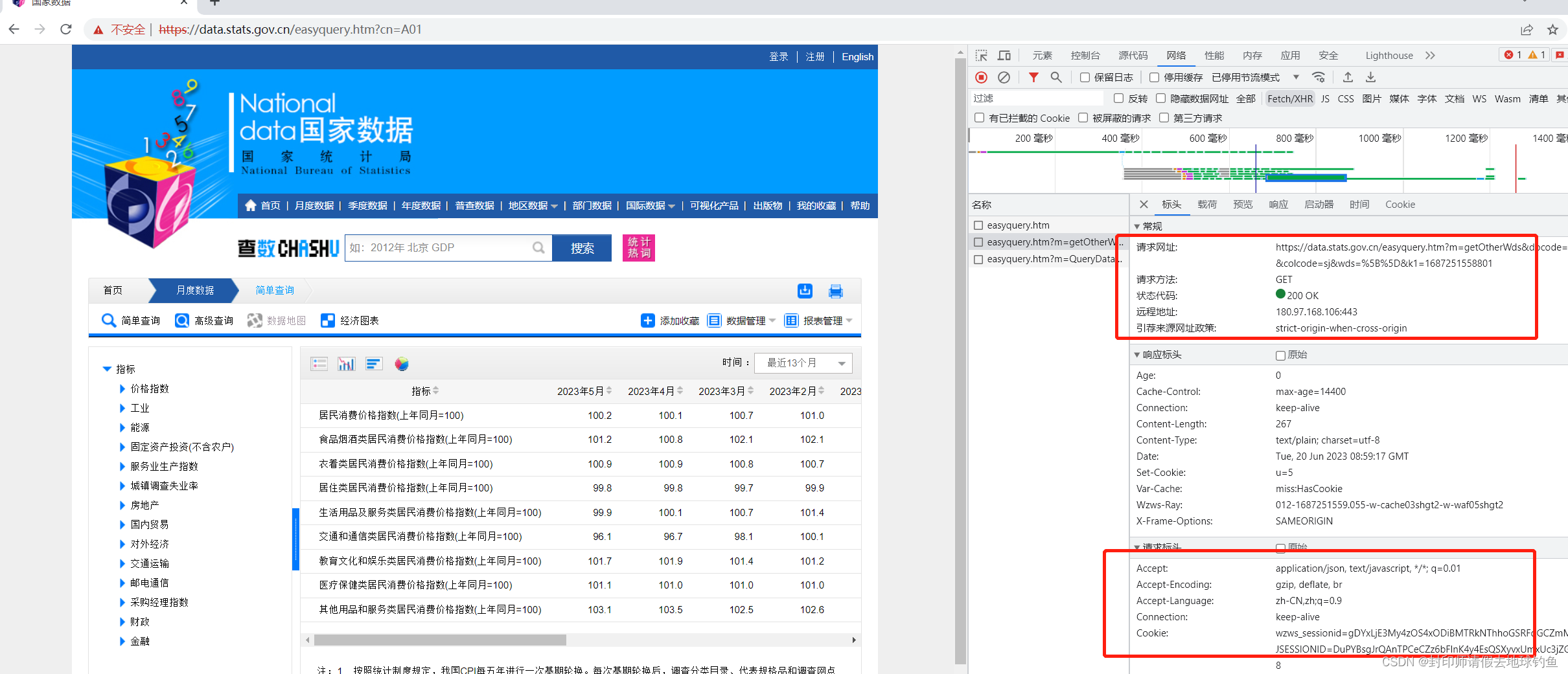
④第三个URL中有个m=QueryData,URL就是返回数据的。可以点开Response简单验证下:
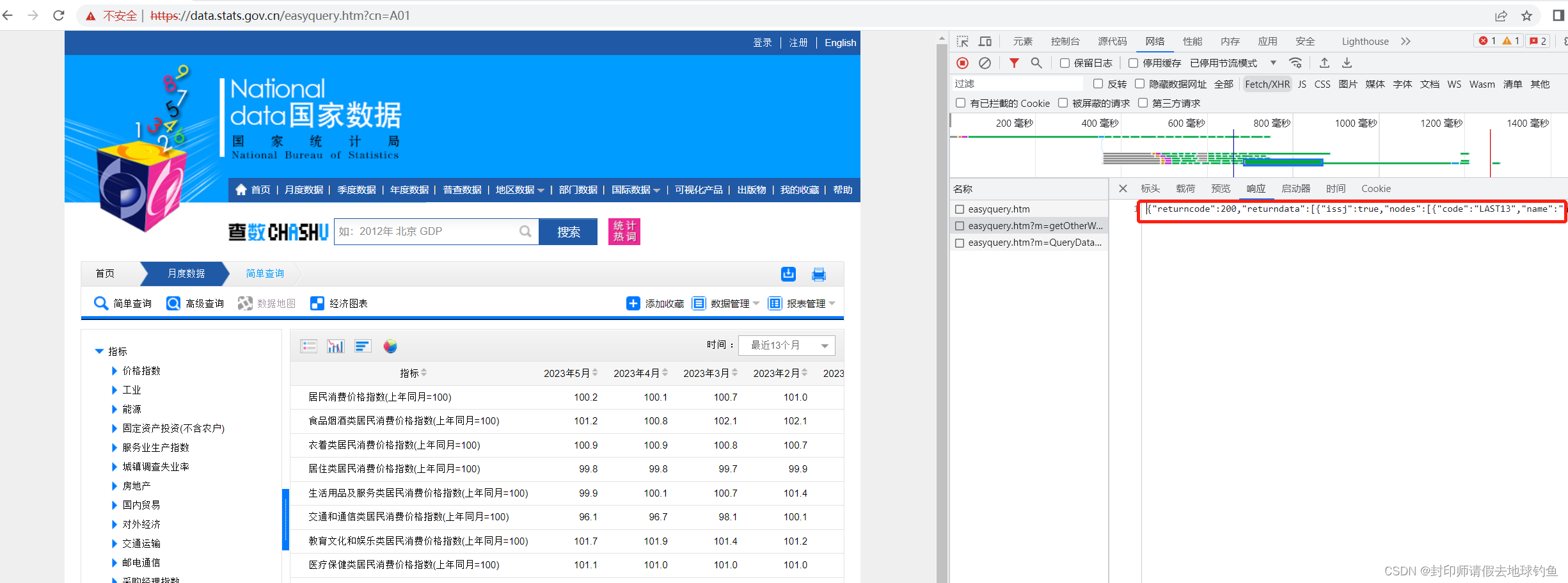
与页面展示的数据进行比对,发现数据吻合,那说明我们猜想的线路没错,因此我们已经初步可以根据Query String Parameters构造键值对了,但是并没有完。
(三)避开陷阱
问题:如果我们直接使用Request URL,爬取的数据与页面并不一样?
解答:我们可以看到一个下拉式菜单
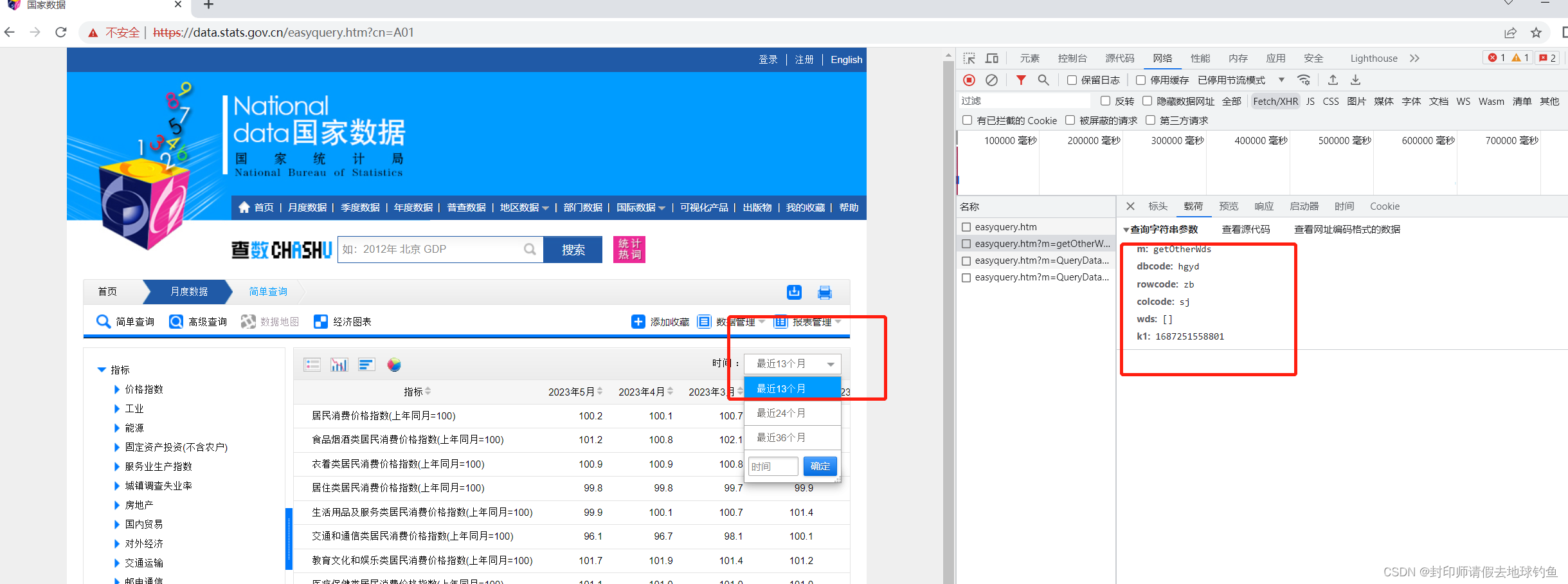
点击“最近13个月”的时候,XHR里面会多出来一项。
可以看到,新的这一条Query String Parameters里面dfwds不再是空了,而之前第三条的dfwds为空。当我们再次查看Response的时候,会发现数据吻合。那么新的这一条URL应该就能真实返回数据了。这里的k1经查证,是时间戳。
(四)开始爬虫
①导入爬虫所需要的库
import requests
import numpy as np
import pandas as pd
from bs4 import BeautifulSoup
import time
import json②生成时间戳
def getTime():return int(round(time.time() * 1000))③爬虫代码,传递url、headers、键值对参数。最终爬取的数据以json的形式展示
url='http://data.stats.gov.cn/easyquery.htm?cn=A01'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'}#浏览器代理
key={}#参数键值对
key['m']='QueryData'
key['dbcode']='hgyd'
key['rowcode']='zb'
key['colcode']='sj'
key['wds']='[]'
key['dfwds']='[{"wdcode":"sj","valuecode":"LAST13"}]'
key['k1']=str(getTime())
r=requests.get(url,headers=headers,params=key,verify=False)
js=json.loads(r.text)
js
爬虫数据json展示如下: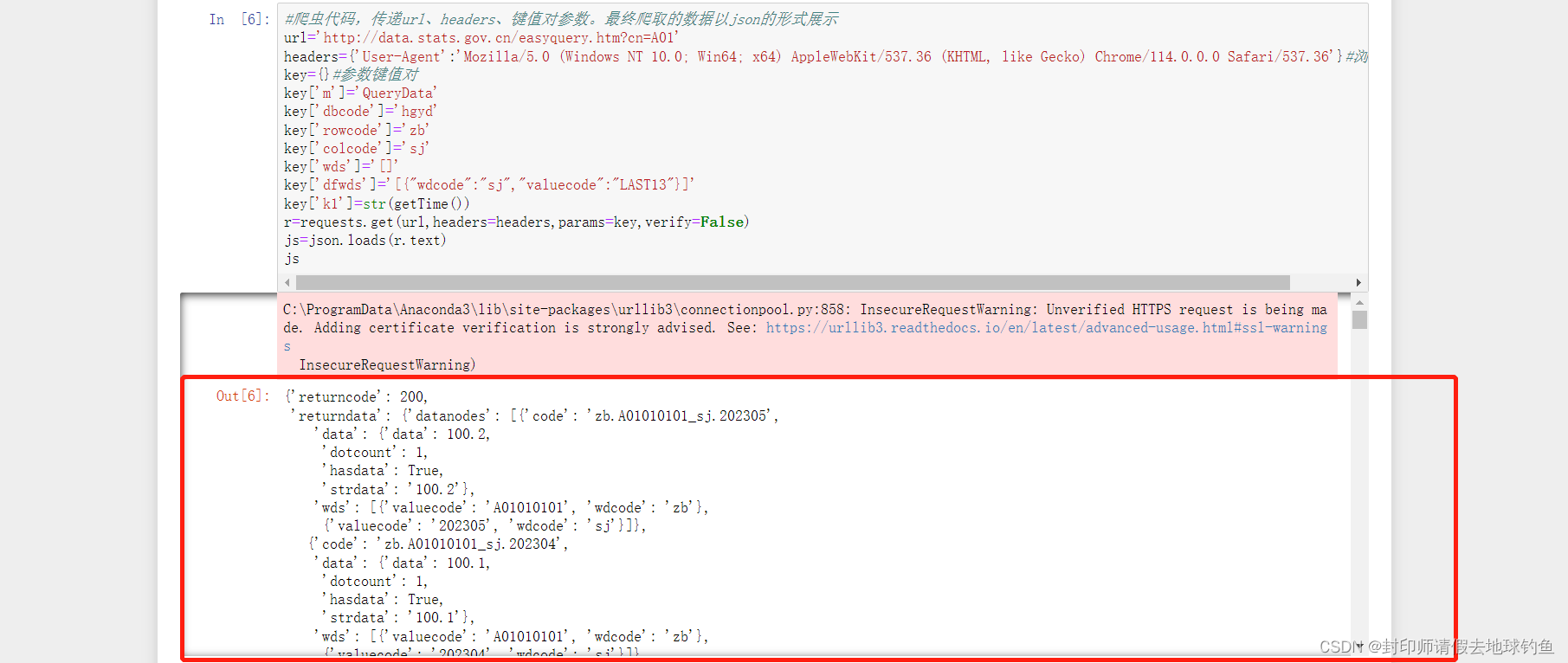
(五)数据预处理
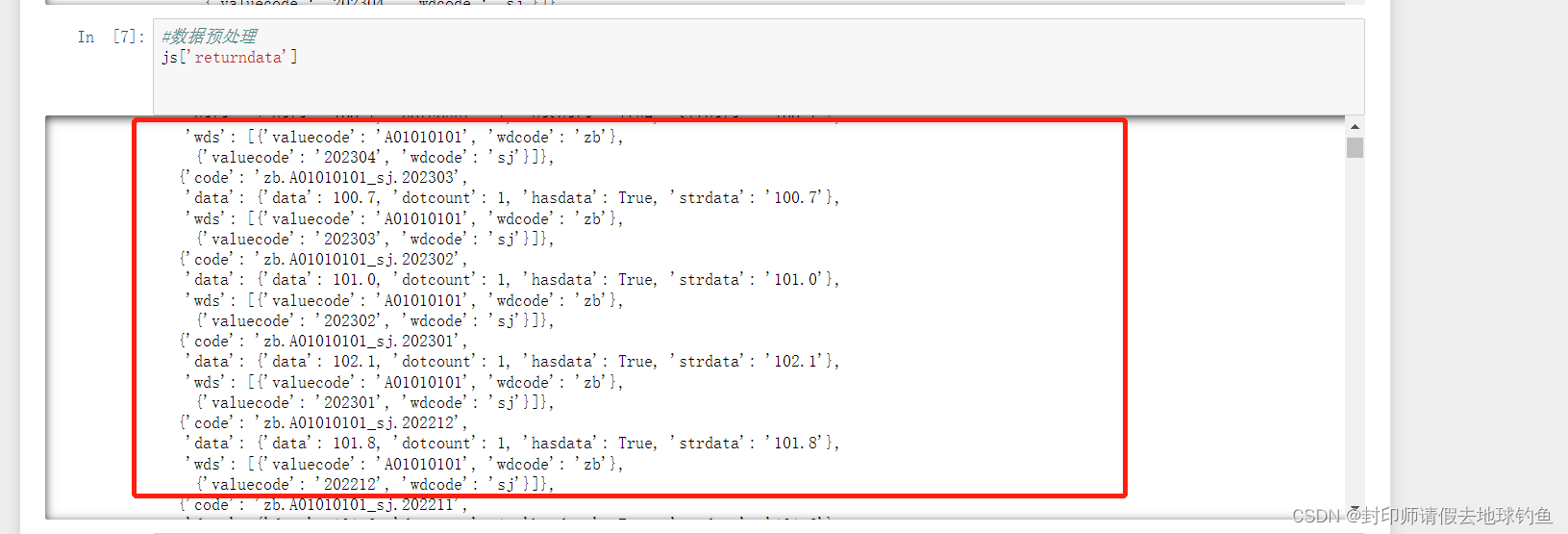
想要的数据其实是在strdata里面,要像剥洋葱一样一层一层剥开找到数据。但是一定要注意,剥开一层之后数据格式的变化!
①初步解析json,首先查看strdata最外层,我们可以看到strdata外面还包裹了一层'datanodes'
②进一步解析json,这次我们应该剥开"datanodes",并查看它数据格式为后面做准备
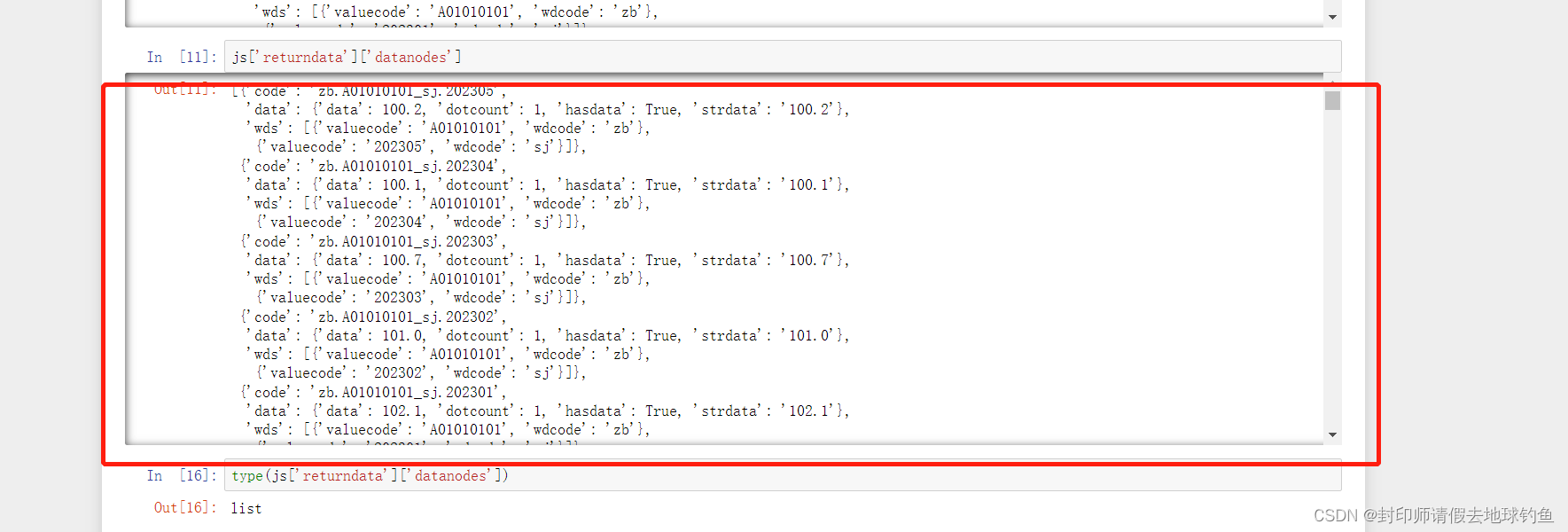
③既然是列表,那我们获取元素就更方便了,但应该注意的是列表里面的元素数据格式是字典类型
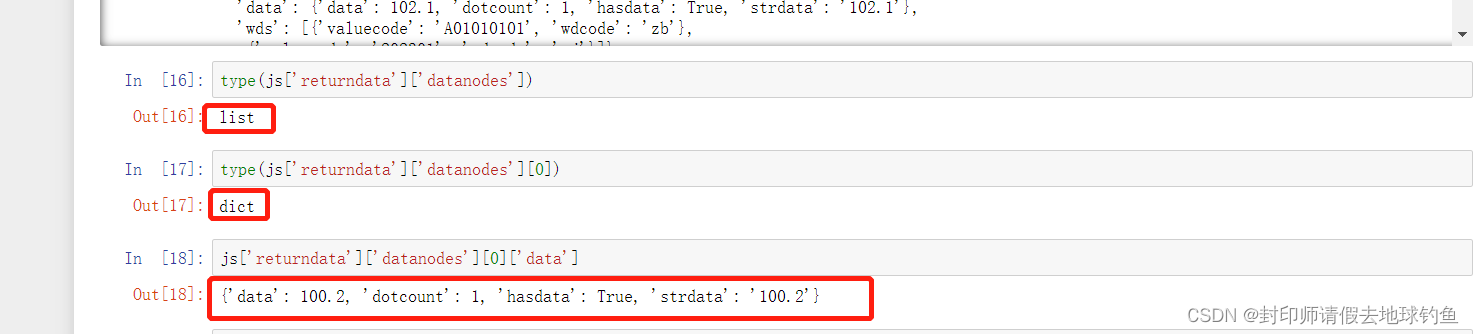
④ 我们可以从上图看到strdata就是键值对的值,同时整个字典类型数据存在于列表里面,那事情就好办啦——遍历列表通过键获取值
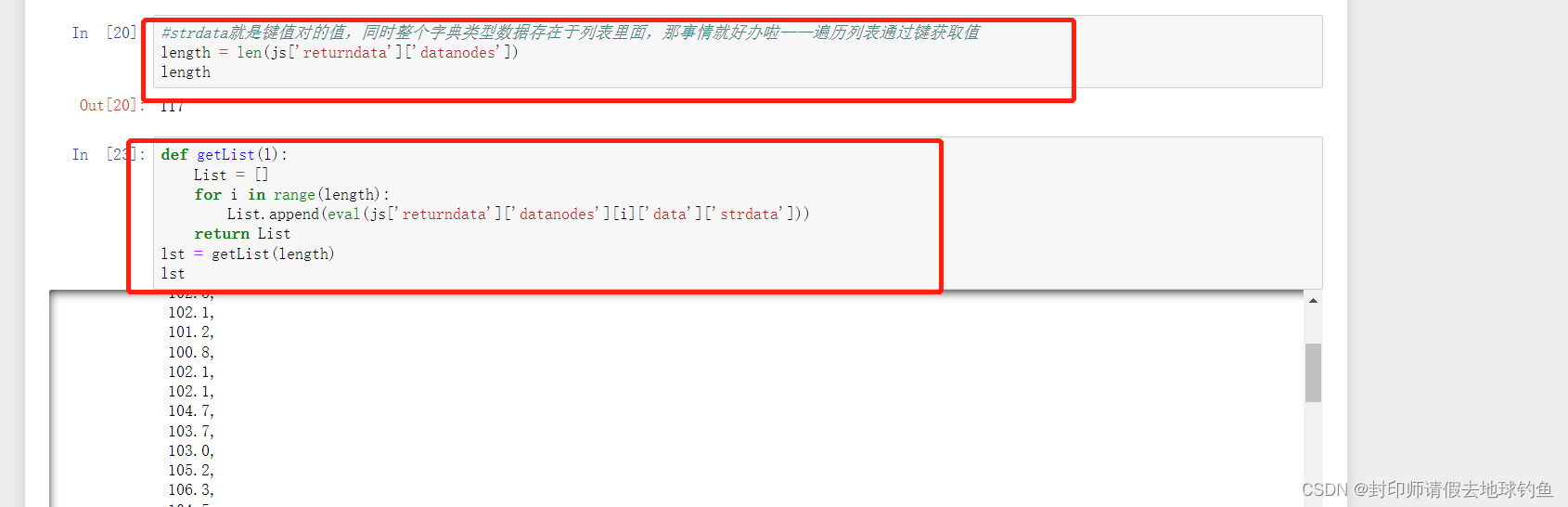
⑤将列表转换成9*13的DataFrame
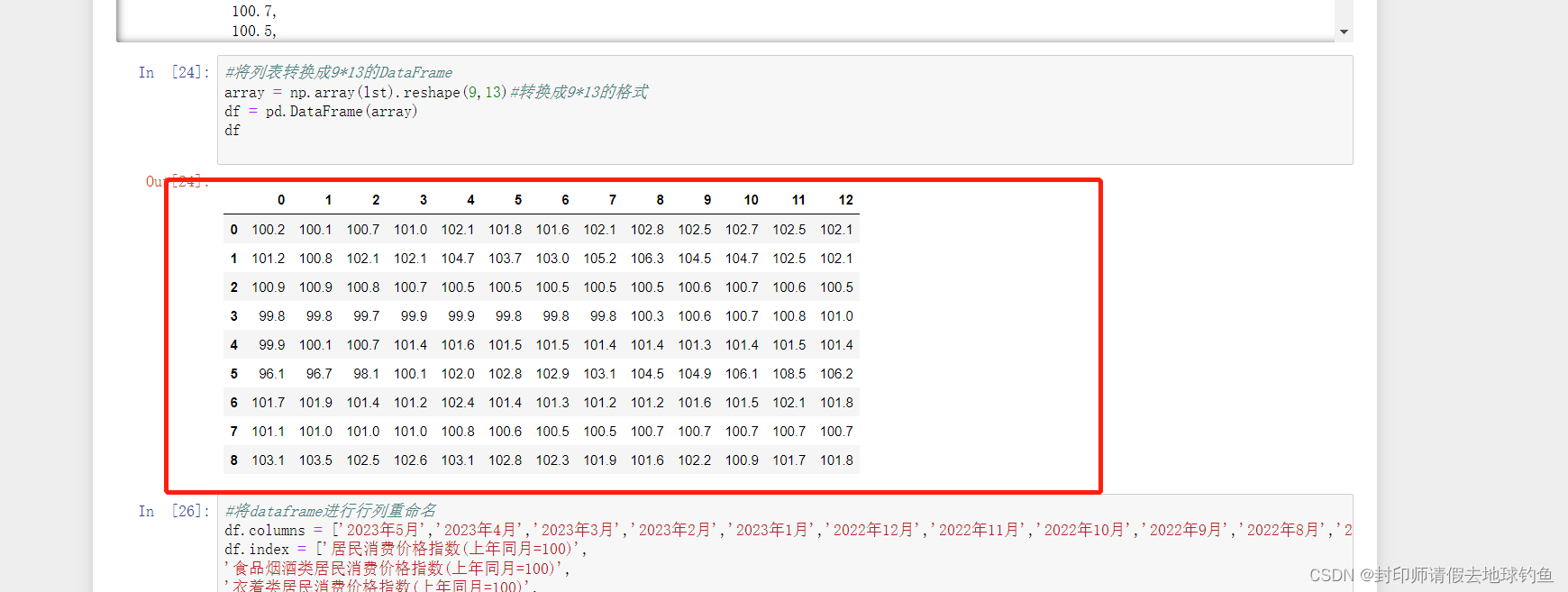
⑥DataFrame行列重命名
#将dataframe进行行列重命名
df.columns = ['2023年5月','2023年4月','2023年3月','2023年2月','2023年1月','2022年12月','2022年11月','2022年10月','2022年9月','2022年8月','2022年7月','2022年6月','2022年5月']
df.index = ['居民消费价格指数(上年同月=100)',
'食品烟酒类居民消费价格指数(上年同月=100)',
'衣着类居民消费价格指数(上年同月=100)',
'居住类居民消费价格指数(上年同月=100)',
'生活用品及服务类居民消费价格指数(上年同月=100)',
'交通和通信类居民消费价格指数(上年同月=100)',
'教育文化和娱乐类居民消费价格指数(上年同月=100)',
'医疗保健类居民消费价格指数(上年同月=100)',
'其他用品和服务类居民消费价格指数(上年同月=100)']
⑦最终结果展示
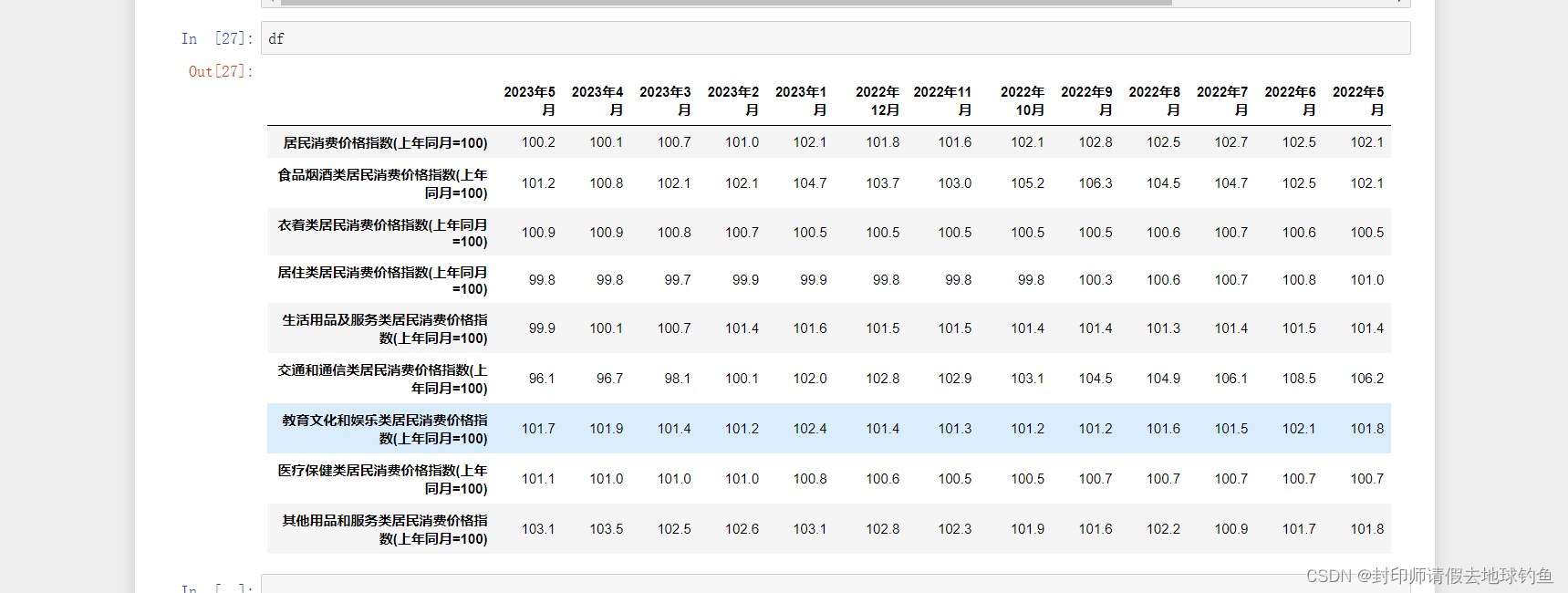
(六)总体代码
#导入爬虫所需要的库
import requests
import numpy as np
import pandas as pd
from bs4 import BeautifulSoup
import time
import json#生成时间戳
def getTime():return int(round(time.time() * 1000))#爬虫代码,传递url、headers、键值对参数。最终爬取的数据以json的形式展示
url='http://data.stats.gov.cn/easyquery.htm?cn=A01'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'}#浏览器代理
key={}#参数键值对
key['m']='QueryData'
key['dbcode']='hgyd'
key['rowcode']='zb'
key['colcode']='sj'
key['wds']='[]'
key['dfwds']='[{"wdcode":"sj","valuecode":"LAST13"}]'
key['k1']=str(getTime())
r=requests.get(url,headers=headers,params=key,verify=False)
js=json.loads(r.text)#数据预处理
#strdata就是键值对的值,同时整个字典类型数据存在于列表里面,那事情就好办啦——遍历列表通过键获取值
length = len(js['returndata']['datanodes'])def getList(l):List = []for i in range(length):List.append(eval(js['returndata']['datanodes'][i]['data']['strdata']))return List
lst = getList(length)#将列表转换成9*13的DataFrame
array = np.array(lst).reshape(9,13)#转换成9*13的格式
df = pd.DataFrame(array)#将dataframe进行行列重命名
df.columns = ['2023年5月','2023年4月','2023年3月','2023年2月','2023年1月','2022年12月','2022年11月','2022年10月','2022年9月','2022年8月','2022年7月','2022年6月','2022年5月']
df.index = ['居民消费价格指数(上年同月=100)',
'食品烟酒类居民消费价格指数(上年同月=100)',
'衣着类居民消费价格指数(上年同月=100)',
'居住类居民消费价格指数(上年同月=100)',
'生活用品及服务类居民消费价格指数(上年同月=100)',
'交通和通信类居民消费价格指数(上年同月=100)',
'教育文化和娱乐类居民消费价格指数(上年同月=100)',
'医疗保健类居民消费价格指数(上年同月=100)',
'其他用品和服务类居民消费价格指数(上年同月=100)']print(df)二、python爬取过程中可能遇到的问题及解决方案
Q:怎样在pycharm中安装所需要的库?
A.Pycharm安装第三方库的三种方法:内部安装、终端安装及下载wheel文件安装三种,我这里只介绍最简单的内部安装哈,详细安装步骤如下:
点击页面中的终端,随后输入“pip install +(库名)”,按回车就可以了。
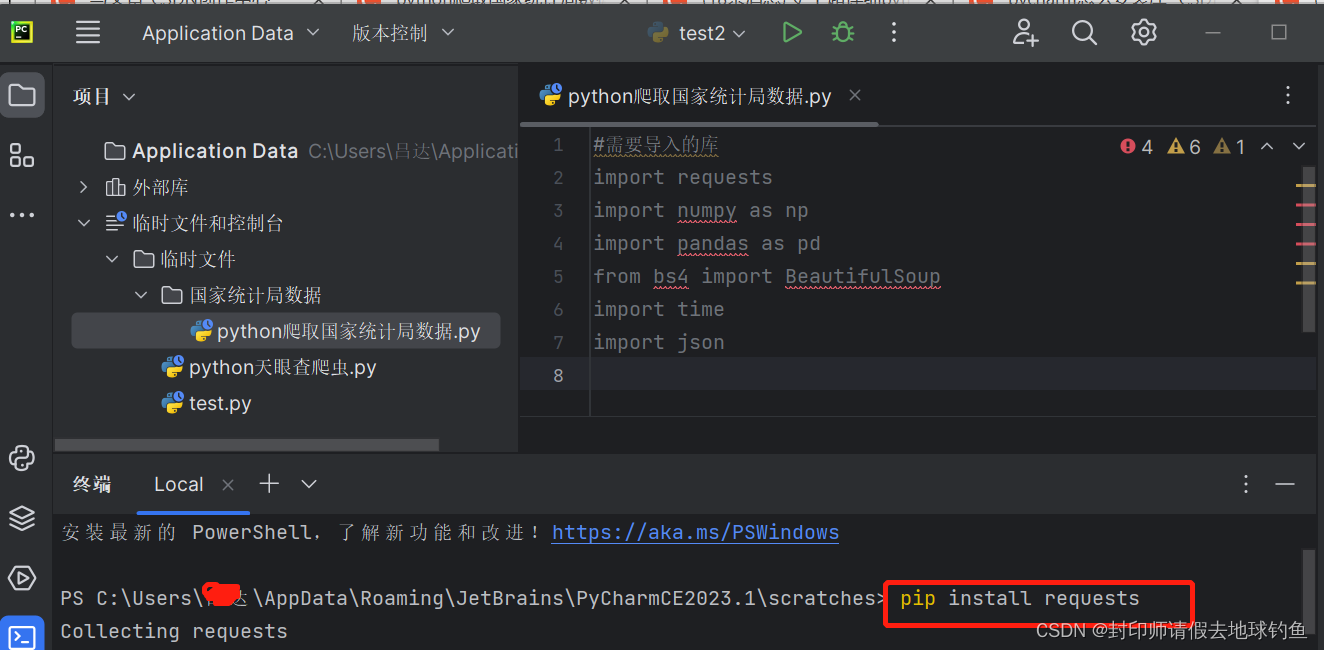
Q:CMD命令行下如何切换路径?
A:在cmd命令符中,如果要切换到相应的路径文件,可参照下述文件:
案例介绍:当前在c盘,要切换到D盘 的一个文件夹下的文件夹下的文件夹....
粗略步骤:1复制当前路径。2打开cmd命令符。 3 cd 后边接上之前复制的路径 回车,然后再写 d: 之后回车,如图所示:

Q:Python 安装beautifulsoup4库步骤?
A:①首先下载官网BeautifulSoup4软件包里面的beautifulsoup4库
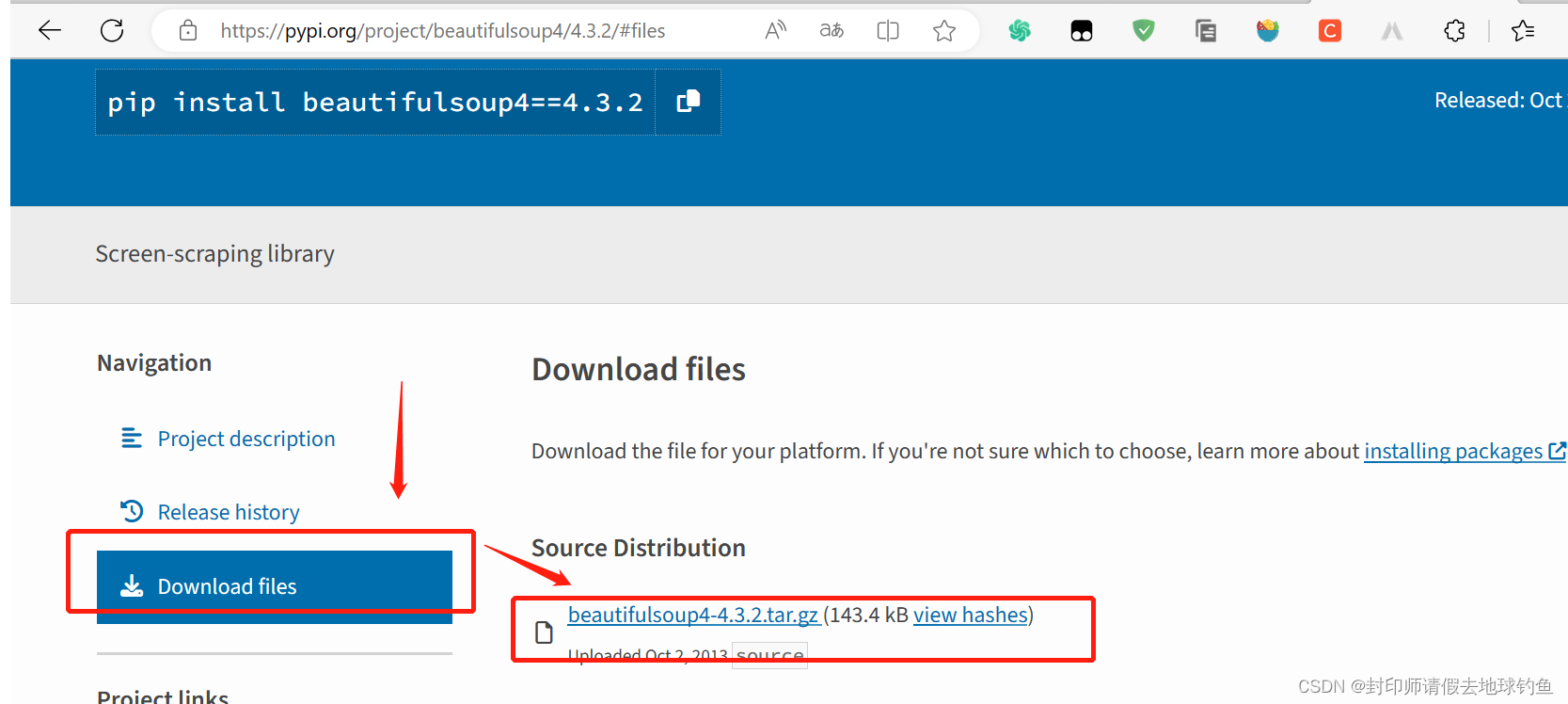
②然后解压缩到G:\python\Lib\site-packages\bs4目录下,打开cmd窗口,进入到解压目录下,进入 G:\python\Lib\site-packages\bs4\beautifulsoup4-4.3.2\beautifulsoup4-4.3.2
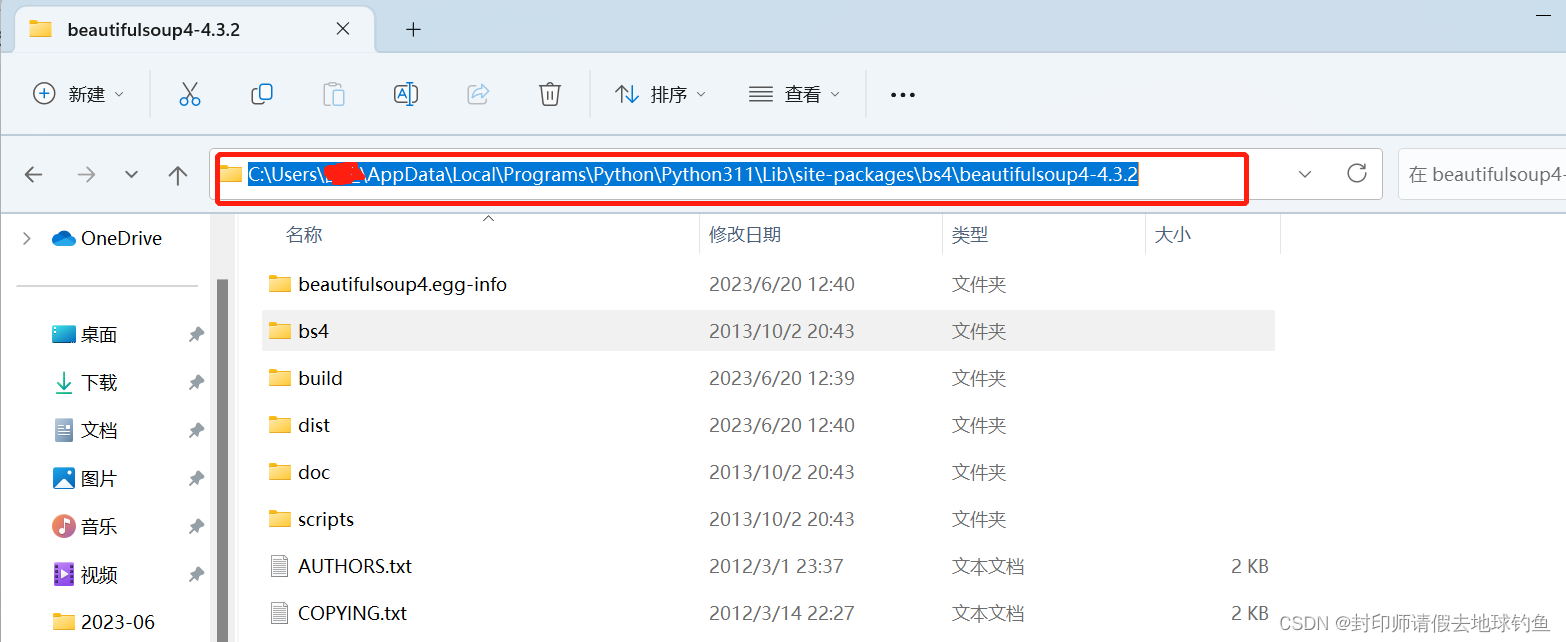
③在该目录下运行cmd
python setup.py build
python setup.py install④可能会遇到的报错 :error in pymmseg setup command: use_2to3 is invalid.
报错的解决方案:需要把版本降低,小于58的最后一个版本是57.5.0,pip降一下就可以了:
pip install setuptools==57.5.0
就可以重新安装库了
没遇到报错,直接到这步骤即可。
Q:怎么安装Jupyter Notebook?
A:cmd命令行,键入pip3 install jupyter,等待安装即可。

Q:XHR是什么?包含哪些?
A:可参考我之前的回答爬虫基础知识入门第一弹!_封印师请假去地球钓鱼的博客-CSDN博客。
xhr,全称为XMLHttpRequest,用于与服务器交互数据,是ajax功能实现所依赖的对象,jquery中的ajax就是对 xhr的封装。
XMLHttpRequest 对象提供了对 HTTP 协议的完全的访问,包括做出 POST 和 HEAD 请求以及普通的 GET 请求的能力。XMLHttpRequest 可以同步或异步地返回 Web 服务器的响应,并且能够以文本或者一个 DOM 文档的形式返回内容。
xhr 接口强制要求每个请求都具备严格的HTTP语义–应用提供数据和URL,浏览器格式化请求并管理每个连接的完整生命周期,所以XHR仅仅允许应用自定义一些HTTP首部,但更多的首部是不能自己设定的。
浏览器会拒绝绝对不安全的首部重写,以保证应用不能假扮用户代理、用户或请求来源,如Origin由浏览器自动设置,Access-Control-Allow-Origin由服务器设置,如果接受该请求,不包含该字段即可,浏览器发出的请求将作废。
如果想要启用cookie和HTTP认证,客户端必须在发送请求时通过XHR对象发送额外的属性(withCredentials),而服务器也需要以Access-Control-Allow-Credentials响应,表示允许应用发送隐私数据。同样,如果客户需要写入或读取自定义HTTP标头或想要使用“非简单的方法”的请求,那么它必须首先通过发出一个预备请求,以获取第三方服务器的许可!
三、参考引用
[1]Pycharm安装第三方库的三种方法_specify version_nufe_wwt的博客-CSDN博客
[2]CMD命令行下如何切换路径_cmd切换路径_传言中的火鲤.的博客-CSDN博客
[3]Python 安装beautifulsoup4库失败或引用错误的解决办法_Nuyoah的博客-CSDN博客
[4]史上最全最详细的Anaconda安装教程_OSurer的博客-CSDN博客
[5]史上超详细python爬取国家统计局数据_王小明爱吃大菠萝的博客-CSDN博客
[6]什么是xhr?_风中梦铃s的博客-CSDN博客
这篇关于python爬取统计局数据第一弹的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






