本文主要是介绍YARN 集群的 Node 节点都处在 Unhealthy 状态,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
问题描述
在客户的 Yarn UI 可以看到有 local-dirs are bad,log-dirs are bad 报错,node 节点都是 unhealthy 状态,如图:

原因分析
之所以会有 local-dirs are bad,log-dirs are bad 报错,是因为在我们集群的 yarn-site.xml 里参数 yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage 的默认值是 90%,到达到这个值会触发上述报错。之所以会触发 yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage 的默认值是因为:
- 客户的数据是存储在 Storage 里的,在进行计算之前需要将数据先读取到各个节点,客户在读取数据生成 RDD 之后对 RDD 的缓存采用的是
MEMORY_AND_DISK_2,也没有采用序列化的方式,也就是说如果内存存不下会存到本地磁盘,而且会存在不同的节点上存 2 份。 - 在计算的过程中会产生大量的中间数据结果,如果内存中存不下也会将结果写到磁盘上。
- 一个 batch 的数据还没处理完,下一个 batch 就来了,上一个 batch 占用的内存还没释放(batch 任务还没执行完),最后都会堆积到磁盘上。
解决方法
-
首先要先 kill 掉所有的任务,因为当前客户的所有节点已经是 unhealthy 状态了,可以采用如下办法 kill 所有的任务:
shell复制
for app in `yarn application -list | awk '$6 == "ACCEPTED" { print $1 }'`; do yarn application -kill "$app"; done -
重启所有节点。
-
重新提交任务。
【现象】查看到yarn监控页面上有十几个Unhealthy 节点,分别进去Unhealthy Nodes查看各个目录的占用磁盘情况,发现是HDFS的有关目录占用过多了,这是因为有很多临时文件占用了Hdfs。
tmp_users=`hdfs dfs -ls /tmp/ | awk '{print $8}' | cut -d"/" -f3 | xargs `
echo $tmp_users # 查看总共有多少个用户使用hive on yarn
【解决1】批量清理每个用户在hdfs临时目录下产生的文件
for user in $tmp_users; do hdfs dfs -rm -r /tmp/${user}/.staging/*; done需要清理HDFS上的回收站
for user in $tmp_users; do hdfs dfs -rm -r /user/yarn/.Trash/Current/tmp/${user}/.staging/*; echo CLEANED ${user} Trash on HDFS; done
终极恢复方案:
更换目录:
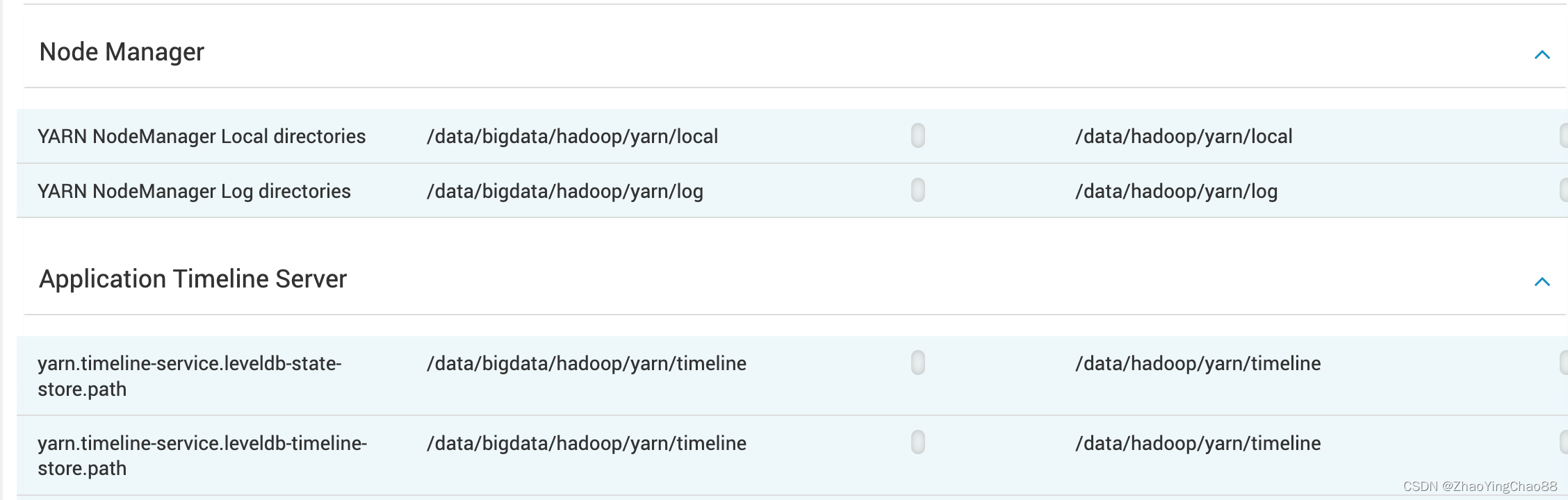
yarn nodemanager format
重启服务
这篇关于YARN 集群的 Node 节点都处在 Unhealthy 状态的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






