本文主要是介绍诺奖模型下的开源代码溢出,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!


| 作者:狄安
| 转载自:OpenTEKr开源星系
| 编辑:钱睿
| 设计:张千禧
最伟大的见解是最朴实的。
The greatest ideas are the simplest.
—— 威廉·戈尔丁《蝇王》
作者 | 狄安
Mar. 5, 2022
4,905 字 | 大约需要 10 min
导言:本文基于 2018年诺贝尔经济学奖获得者罗墨提出的经济增长理论,尝试探讨开源软件代码溢出后产生的经济学模型及其相关分析。
这几天由于俄乌战争影响,网络上有消息传 GitHub 要制裁俄罗斯,以至于有人惊呼开源也政治化了。这里,不得不和大家普及一下 GitHub 不代表开源,它只代表着托管开源软件的一个商业平台,GitHub 的拥有者是微软公司,不是开源组织。
所以,即使哪一天 GitHub 真宣布对俄罗斯程序员禁用,大家需要清楚的一点是,那不是开源对俄罗斯程序员的禁用,是微软公司的决定而已。

1
开源溢出的是一种公共知识
开源软件作为一种从开源社区溢出的代码知识,其属性随着开源的那一刻,就在与它一起发布的开源许可协议内都定义清楚了。事实上,开源软件作为公共知识的一种,是很难去禁止谁的。除非,开源软件所属的开源社区或者基金会组织采取一些极端的行动。
在SAP、Apple、Google 等科技巨头公司宣布停止对俄罗斯的服务后,网络媒体上甚至冒出了“技术还有国界吗?”的言论。当然,这也可以理解,作为一家科技公司,肯定是有国界的,也完全可以选择自己的政治立场。但,科技公司并不简单等价于科技知识。
至于技术和知识有没有国界,也是要区分清楚的,因为知识也可分为公共知识和私有知识。“科学没有国界,科学家是有祖国的” 这句话里对于科学没有国界的表达,指的是人类所共有的那些公共的科学知识,而科学家在公共知识下通过自身所掌握的一些专有和私有化知识,确实会产生国界区分。

所以,现在那些宣称暂停服务所代表的技术,充其量就是一些科技公司所拥有的私有技术和知识罢了。而作为人类所共同拥有的公共知识,不仅是科学家或技术专家们用于形成私有知识的基础,更是推动社会经济增长的驱动力。
我们今天要聊的开源话题,就是软件因为代码的开源开放后,在开源社区产生了知识的显性化,然后形成知识溢出,于是成为了一种人类的公共知识。鉴于开源的知识表现为代码形式,我也把这种现象称作「开源代码溢出」。
2
开源代码溢出为何物?
先说说,知识溢出是什么?
经济学家保罗·罗默(Paul M. Romer),新增长理论的创建者,首先系统性提出了知识溢出的观点。他把知识完整纳入到经济和技术体系之内,建立了两个著名的内生经济增长模型,并得出了一个重要的观点:知识溢出所形成的公共知识是推动技术进步的一个重要基础,而技术进步是推动经济增长的驱动力。他也因为这些理论成就和威廉·诺德豪斯(William D. Nordhaus)共同获得了2018年度的诺贝尔经济学奖。

开源软件通过开源使得软件代码公开,所有人只要遵循开源软件发布的开源许可协议就可以公开免费可得,同时这部分代码在“拥有上的非排他性”和“使用上的非竞争性”,几乎可以让人人使用。于是,软件开源的直接结果,就是开源代码对应的那部分技术知识成为了一项社会公共物品和公共知识。
这样一来,开源软件实际上是完美地符合了罗墨的新增长理论下的「知识溢出效应」。关于知识溢出,涉及到两个主体:知识溢出的供给者和知识溢出的接受者。在「开源的知识溢出」这事上,对应的则是「开源使用方」和「开源贡献方」。
那么,什么又是「开源代码溢出」呢?我试着这样来进行定义:
开源的使用方通过自觉或者不自觉地吸收来自开源贡献方的代码,并结合现有知识进行创新;而这种代码知识在转移时,由于具有“非竞争性”和“非垄断性”的外部特征,就会产生在开源使用方没有给开源贡献方以经济补偿或者回报情况下的代码使用。
或者说,开源的贡献方没有获得全部的收益,同时开源的使用方也没有承担全部软件代码的创造成本,这就叫做「开源代码溢出」。
3
诺奖模型下代码溢出之经济学函数表达
罗墨的新增长理论有两个模型,一个是假设在完全竞争条件下基于知识溢出的内生增长模型,另一个是假设在非完全竞争和部分知识垄断下的内生增长模型。有兴趣的朋友可以把他的论文找出来仔细学习一下。
在开源生态中,如果严格按照 OSI(Open Source Initiative,即“开放源代码促进会”)制定的开源标准来发布的开源软件,实际上就属于罗墨假设在完全竞争条件下的知识溢出模型。那么,按照罗默给出的第一个数学模型,就让我们试着从「开源使用方」角度来阐述一下「代码溢出后的经济学分析」。
我们可以尝试给出开源使用方的生产函数表达式:
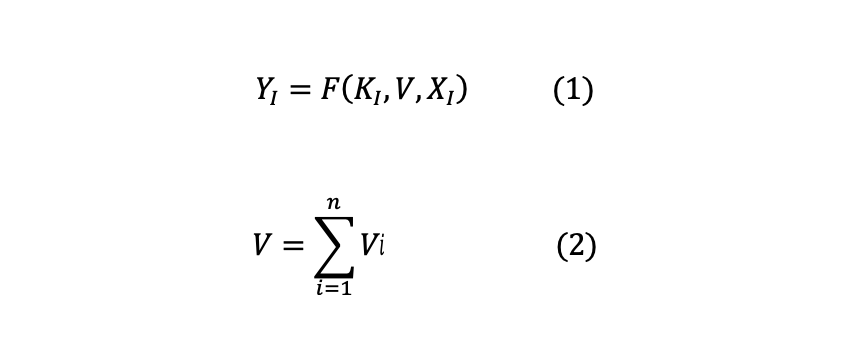
对于表达式 (1),可以这样理解:开源使用方的产品产出水平,由使用方自身拥有的知识水平(Ki)、开源代码溢出的公共知识拥有水平(V),以及传统投入的要素向量水平(Xi)的这三个因素来决定。具体如下
Y 为使用了开源技术的使用方的产出水平;
Ki 为企业为产品拥有的专有知识;
Xi 为厂商的投入要素向量(如资金,设备等);
V 则为企业可以拥有的开源软件的知识总量水平;
对于表达式(2),则可以理解为:开源代码溢出的公共知识水平总量(V),由所有开源社区贡献方的代码贡献水平(Vi)的总和来决定。

4
开源代码溢出生产函数下的经济学分析
对于上述两个函数表达式,如果把它们对应到开源具体场景,并试着用开源人了解的语境来表达,可以做出以下 3 项分析:
第一项分析
假设在开源使用方的「资本投入」和「其私有知识」恒定的前提下,那么更高的「开源代码溢出总量水平」有利于企业产品的产出水平。
开源使用方能否拥有更高的开源代码知识拥有水平,则取决于
其所在生态内可以触达的「开源代码溢出水平的总量大小」;
在所拥有的开源代码溢出总水平量下,所能「实现的转化率大小」。
于是,我们也不难这样推论:在开源发达的国家和区域里的企业,由于可以触达到更多开源知识总量水平高,从而将更有利于提高企业产品的产出水平。同时,具体的企业如果注重开源技术的拥有和使用,并关注其转化率,那么该企业的产品产出水平也将相应获得改善。


实际情况也确实如此,在美国的科技公司似乎更容易产出更高科技水平的产品。而在国内市场上,我们可以毫不夸张地说,在过去二十年成功的互联网和高科技公司中,无论是百度、阿里、腾讯,还是华为、小米、字节跳动等,无一不是充分「享用」了开源代码溢出的红利,它们的成功就正是因为充分关注了开源技术的拥有及使用转化率。
而这样的事实,对于各类在当前开源热浪涌动之下想跑步进入数字原生化的企业而言,谁能更多地拥有可以触达的开源代码溢出下的总知识水平,同时谁又能更专注提高开源知识总水平在企业产品中的使用转化率,那谁就更有可能提高自己产品的产出水平,从而获得更大的竞争力。
进而,我们也可以看到,去年年底被广泛使用的开源软件 Log4j 因为严重的安全漏洞,引发各类对于开源软件使用担忧的言论以及开源软件供应链问责问题,类似这样的困境也就迎刃而解。按照这个表达式来看,实际就是对于一个有效 V 值的求解而已。


第二项分析
假设在「开源代码溢出的总量水平」和「资本投入」恒定的前提下,开源使用方的企业如果提高自身私有知识的水平,则可以显著提高自身产品的产出水平。
关于这个结论,我们可以看到,如果一个开源技术的贡献方同时又是一个开源技术的企业使用方,那它的产品产出水平由「其自身所有的私有知识 Ki」决定。如果它同时是个开源技术贡献者,因为它的贡献而导致了它自身 Ki 的减小,事实上就减弱了它自身产品的产出水品。
那么,如果它要和其他同类企业进行产品竞争的话,似乎一个可行的办法是去减少对于开源社区的代码贡献,或者提高它的资本投入来提升它的产出水平。
了解到这个事实,我们也就明白了开源创业公司如 MongoDB 和 Elastic 等企业,当发现来自亚马逊等公有云公司这些有着更大资本投入的公司竞争时,由于意识到自己根本无法在资本投入水平上与其抗衡,只能想办法“提高自己的Ki值”和“降低竞争对手的 V 值”这两项策略。如此一来,就出现了它们所采取的:
不以 OSI 开源许可的标准来发布代码,并开发更多自身专属的私有技术知识来提升 Ki 值;
通过增加开源许可协议的条款限制,来设法降低公有云厂商对开源代码溢出总量的使用和转化。


第三项分析
开源代码溢出的总量水平 V,对于任何一个使用方而言,其实在开源知识溢出的那一刻,已经是个给定的值。
按照上述第二个表达式,V 就是所有开源贡献者的代码贡献总水平。开源社的庄表伟老师前段时间发表了一篇《试论开源生态的经济模型》,文章基于传统的劳动价值理论,初步假设了一个以劳动时间为变量的开源生态经济学模型,并建议以贡献者在开源社区投入的必要劳动时间来定义开源软件的经济学价值,以开源社区的总劳动时间来定义开源社区的活跃度。这的确给出了一个来分析开源生态经济学价值很好的思路。
但,开源软件作为过去三十年发展起来的在知识经济和数字经济新时代下的技术现象,它的产出物不仅和必要的劳动时间相关,更和无法用时间去度量的人类智力(人力资本)和累积的知识水平相关。这样使得开源软件和开源社区又和工业时代的商品生产拥有了一些完全不一样的特征。事实上,开源社区的产出水平也同样可以罗墨的生产函数加些变形后,以递归的形式来表示。
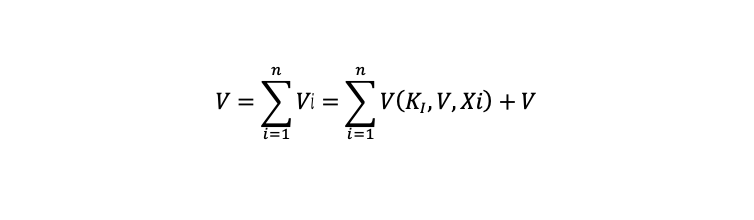
即,开源代码溢出的总量水平,一方面是所有开源贡献者的代码贡献总和,另外一方面也是存量的开源社区溢出代码总量水平 ,再加上当下各个开源贡献者的代码贡献量水平的总和。而当下的每个开源贡献者的开源贡献量,又由其「自身在开源贡献上的资本投入」、「对于原有的开源知识水平的使用」及「自身私有知识」的三个要素决定。


我们可以看出,要将开源溢出代码总量水平即V值提高,那就是要提升 Vi 的贡献量。而从每个开源贡献方的角度而言,无论代码贡献,还是对于开源社区的资本投入,都将有利于开源代码溢出总水平量 V 的提高。
这样,我们从罗墨的理论可以预见,开源溢出的知识总量水平,从全社会的角度而言,将影响整个社会的数字经济发展。对于任一一个国家、地区和行业领域,其所具有的开源知识总量水平将决定了它的数字经济增长水平。
5
代码溢出模型下的开源建议
对于开源的使用方而言,在开源软件的公共知识属性下尽快建立自己在这部分公共知识之上的竞争力将是一个不二之选。通过拥有更多对于开源溢代码总量水平的使用,可以提高自己产品的产出水平。
但,同时作为开源的使用方,必须意识到一点:以各种形式的投入开源,或者为开源付费,都将有助于提升开源代码溢出的总量水平。
对于某一类开源技术的贡献方同时又是自身贡献的使用方而言,的确面临着一项挑战,即一方面因为自身的贡献有力的提升了开源溢出知识的总量水平,另一方面却因为自己的贡献无可避免的降低了自身专有知识水平,从而产生了自身产品产生水平竞争力下降。这似乎是一个不可调和的矛盾。

不过,也不用太担心,因为事实上罗墨在他的第一个模型之后,随后又专门研究了在非完全竞争下的第二个知识溢出模型,并引入了人力资本和新思想的概念。
人力资本理论的提出者是威廉·诺德豪斯(William D. Nordhaus),他在2018年和罗墨一同获得了诺奖。以他们的观点对应到开源现象,我们可以这样解读:
虽然贡献方因为既有开源的代码贡献形成了公共知识后,不再对这部分知识具有垄断性和排他性,但贡献方本身作为人力资本的拥有方,却是具有天生的排他性和垄断性的,而这些有价值的人力资本的新思想却是不断涌现的,从而将有效保持贡献方的竞争力。
所以,贡献方可能会因为自己的开源贡献,失去局部或者阶段性的竞争力,但他们所拥有的人力资本的“排他性”和“垄断性”最终将决定他们的竞争力,除非失去了这部分人力资本。
这个理论模型可能是理想化的,却确凿无疑的给我们指明了一个方向:对于人力资本的拥有,有时将比私有知识的拥有,来得更加重要且更具有垄断性竞争力。

开源的远眺
对于个体贡献者而言,除了基于兴趣爱好或个人利益驱动参与开源贡献之外,完全可以站在更高的立意上,去看待自己对开源社区的代码贡献 —— 这是在推动人类社会的经济增长的有价值工作。将自己的代码开源置于全社会的公共知识体系之内,可能会因为自己的代码开源丧失局部的或者阶段性的经济利益,但却绝不会丧失自己作为人力资本本身的竞争力和垄断性。
而对于政策制定者而言,如果能够不断加大对开源社区的扶持和资助,如通过向开源社区的资金扶持、向开源软件的服务提供方付费购买,或向开源贡献的企业予以政策补贴,都将有助于提升开源技术公共知识的总量水平,而这部分公共知识总量水平最终提高将推动经济的长期增长。
相关阅读 | Related Reading

程序员匠性的唤醒和维护

Nginx不接受俄罗斯的贡献,违背开源协议和定义吗?我们冤枉F5了吗?
 开源先锋启示|有爱的开源
开源先锋启示|有爱的开源
开源社简介
开源社成立于 2014 年,是由志愿贡献于开源事业的个人成员,依 “贡献、共识、共治” 原则所组成,始终维持厂商中立、公益、非营利的特点,是最早以 “开源治理、国际接轨、社区发展、开源项目” 为使命的开源社区联合体。开源社积极与支持开源的社区、企业以及政府相关单位紧密合作,以 “立足中国、贡献全球” 为愿景,旨在共创健康可持续发展的开源生态,推动中国开源社区成为全球开源体系的积极参与及贡献者。
2017 年,开源社转型为完全由个人成员组成,参照 ASF 等国际顶级开源基金会的治理模式运作。近七年来,链接了数万名开源人,集聚了上千名社区成员及志愿者、海内外数百位讲师,合作了近百家赞助、媒体、社区伙伴。

这篇关于诺奖模型下的开源代码溢出的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








