本文主要是介绍PortaSpeech CLAPSpeech: 提升TTS的韵律自然度音质,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
会议:2021 NIPS
作者:ren yi,Jinglin Liu
单位:浙大
文章目录
- PortaSpeech
- abstract
- intro
- method
- Linguistic Encoder with Mixture Alignment
- Variational Generator with Enhanced Prior
- Flow-based Post-Net
- Training and Inference
- Experiments
- CLAPSpeech
- abstract
- method
- experiment
PortaSpeech
abstract
- 非自回归TTS——
- 基于VAE:善于建模长时语义特征(比如韵律),但是生成结果模糊、不自然;
- normalizing flow:善于建模freq-bin细节,但是参数量少的时候表现不好。
- motivation:使用少的数据量,生成情感、韵律变化丰富的语音。使用VAE+F
(1)建模韵律和mel谱细节, we adopt a lightweight VAE with an enhanced prior followed by a flow-based post-net with strong conditional inputs as the main architecture.
(2)为了压缩模型参数:introduce the grouped parameter sharing mechanism to the affine coupling layers in the post-net.
(3)为了改善语音的表现力,减少对text和语音精确对齐的依赖:引入linguistic encoder,进行hard word-level和soft phoneme-level的对齐,也精确的提取了字级别的情感; - 结果:相比于FastSpeech2,4x模型压缩,3x运行内存减少,
intro
- VAE可以增强合成语音的表现力,但是生成谱over-smooth
- flow的应用:Flow-TTS 将fastspeech中的decoder用glow替代,并且用一个单独的网络学习对齐;Glow-TTS引入normalize flow+动态规划单向对齐,实现快速、多样、可控的合成。这种方法生成谱的质量比较高,但是实验发现需要的数据量比较大,如果数据量少,生成质量明显下降。
method

total_loss = mel_loss + kl_loss + MLE loss + dur_loss + align_loss
Linguistic Encoder with Mixture Alignment

- FastSpeech使用对齐工具获得 phoneme-level hard alignment,但是由于一些音素边界天然的模糊,因此phn-level的对齐结果会有一定的误差,然后这些误差会影响duration predictor,进而传导到生成语音的韵律。因此本文使用soft alignment in phoneme level 以及hard alignment in word level.
- 音素编码得到隐变量 H p H_p Hp,根据分字边界对同一个字的音素进行average pooling,得到字级别的隐变量 H w H_w Hw,根据duration predictor预测的word duration对word embedding进行扩帧。duration predictor是预测每个phn的时长,然后将属于一个word的phn duration累加。
- H w H_w Hw作为Q, H p H_p Hp作为key,value, 寻找对齐的word-to-phn attention, H p H_p Hp和 H w H_w Hw送入attention之前都加上word的相对位置编码信息;以找到一个单向的、对角对齐。
- 优点:避免phn对齐不准确的失误,同时保留了细粒度,soft,close-to-diagonal text-to-spectrogram alignment。
Variational Generator with Enhanced Prior

- 本模块本质是利用文本作为条件监督,从mel中提取出韵律相关的表征
-使用轻量级的结构实现有表现力、多样的语音生成,因此采用VAE结构作为mel-spec generator。传统的VAE使用高斯作为先验,给后验分布很强的约束,从而限制了decoder的多样性和生成能力。为了增强先验分布,引入small volume-preserving normalizing flow,用一系列K可逆映射将简单的高斯分布转换为复杂的分布,此变换后的复杂分布作为VAE先验。 - 训练阶段:
- mel+txt condition输入encoder,得到 μ , σ \mu,\sigma μ,σ分布,重采样得到 z z z,送入decoder(此处起名不太合适),应该就是几层非线性变换。
- 同时为了训练VP-Flow, μ q \mu_q μq, σ q \sigma_q σq 通过VP-Flow变成标准正态分布,并求KL loss;
- inference阶段,没有ref-mel,VP-Flow把一个标准正态分布的样本重采样为 z p z_p zp,然后送给decoder。
- 说明:送给decoder的 z p z_p zp不再是标准高斯的重采样,训练阶段是encoder输出重采样,inference阶段是标准高斯经过flow变换成复杂分布之后的采样。
Flow-based Post-Net
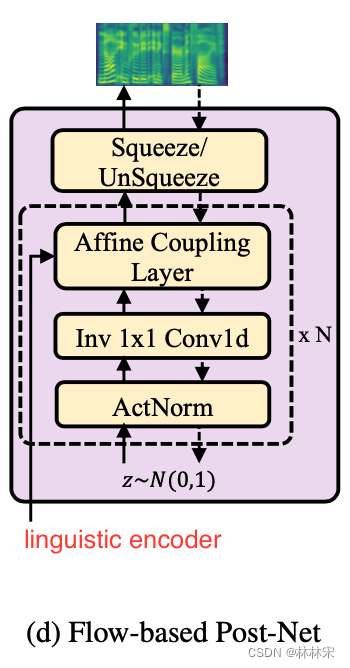
- Flow可以生成更真实的mel-spec,但是模型参数量很大。本文的flow作为postnet,不需要关注文本和韵律信息,只需要关注mel-spec的细节。并且引入参数共享的想法,降低对flow建模的参数要求。
- 训练阶段:postnet将真实的mel-spec映射到latent prior distribution (isotropic multivariate Gaussian,各向同性多元高斯),并计算对数似然估计;
- 预测阶段:从latent prior distribution中采样,反向送入postnet,得到高保真的mel-spec
- postnet的条件输入有文本&韵律的信息,所以网络只关注在mel-spec细节的建模;降低了模型建模难度(参数量不需要那么大);为了进一步减少参数量,在affine coupling layers中引入grouped parameter sharing mechanism
- 参数共享的想法借鉴了Nanoflow的文章,做出改进:
- 移除flow indication embedding以简化模型:不同flow step的unshared conditional projection layer可以帮助模型确定当前step的位置;
- 一个group中flow steps的参数共享,而不是所有flow step的参数共享:不需要改变模型结构就可以更好的调整可训练的参数。
Training and Inference
training stage
- duration loss L d u r = M S E 【 l o g ( g t − w o r d − d u r ) , l o g ( p r e d − w o r d − d u r ) 】 L_{dur} = MSE【log(gt-word-dur), log(pred-word-dur)】 Ldur=MSE【log(gt−word−dur),log(pred−word−dur)】
- VAE的重建loss L V G = L 【 g t − m e l , p r e d − m e l 】 L_{VG}=L【gt-mel, pred-mel】 LVG=L【gt−mel,pred−mel】
- VAE的kl loss L K L L_{KL} LKL
- postnet的 L P N L_{PN} LPN negative log-likelihood
inference stage
- text seq(phn+word 边界)——【linguistic encoder】预测word duration + 使用mix align做hidden state扩帧—— linguistic emb H L H_L HL——【VAE】 根据vae-encoder输出采样+ H L H_L HL,送给vae-decoder生成粗粒度的mel-spec M c M_c Mc——【postnet】根据 H L H_L HL和重采样的分布,生成细粒度的mel-spec M f M_f Mf
Experiments
- LJSpeech作为训练&测试数据集
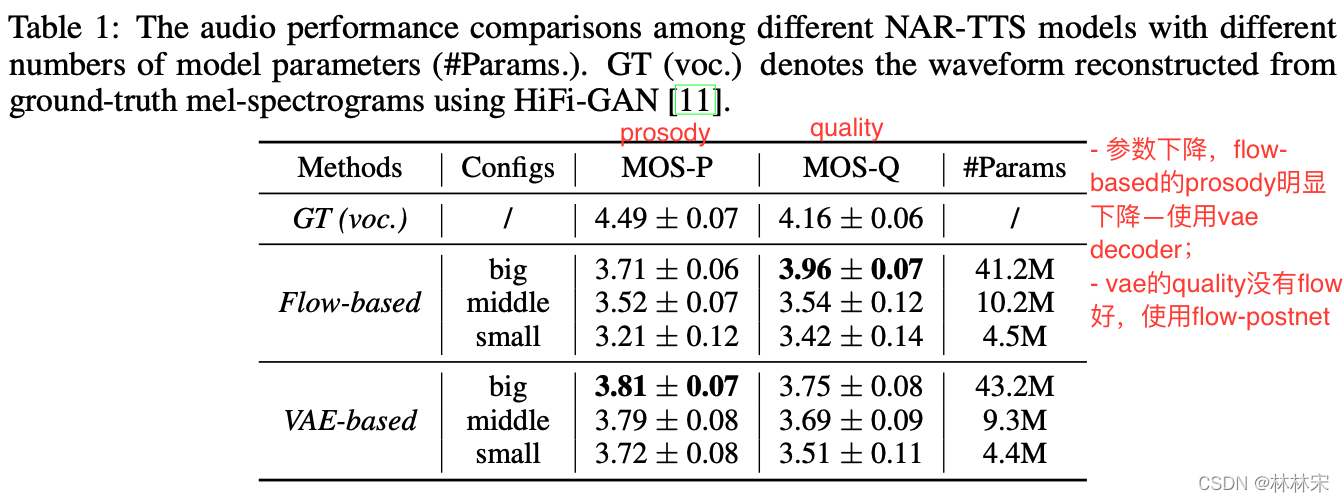
- NAR-TTS基础验证实验


CLAPSpeech
abstract

- 作者认为韵律和上下文文本有关系,传统的基于BERT的改进,只停留在文本层面的上下文建模;VAE主要在speech空间。因此仿照CLIP,使用对比学习,训练text-prosody的映射,建立一个共享空间,提取的embedding可以直接plugin的方式,加入到PortaSpeech中,作为输入端的韵律补充。
method



experiment
- 基于ASR数据训练CLAP,得到的CLAP加入TTS模型测试;

这篇关于PortaSpeech CLAPSpeech: 提升TTS的韵律自然度音质的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






