本文主要是介绍关于Ceiling Analysis(上限分析)的思考,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
废话多说,先上原图。这张图出自吴恩达机器学习课程。这节课讲到了Ceiling Analysis: What Part of the Pipeline to Work on Next。我们姑且翻译为上限分析。
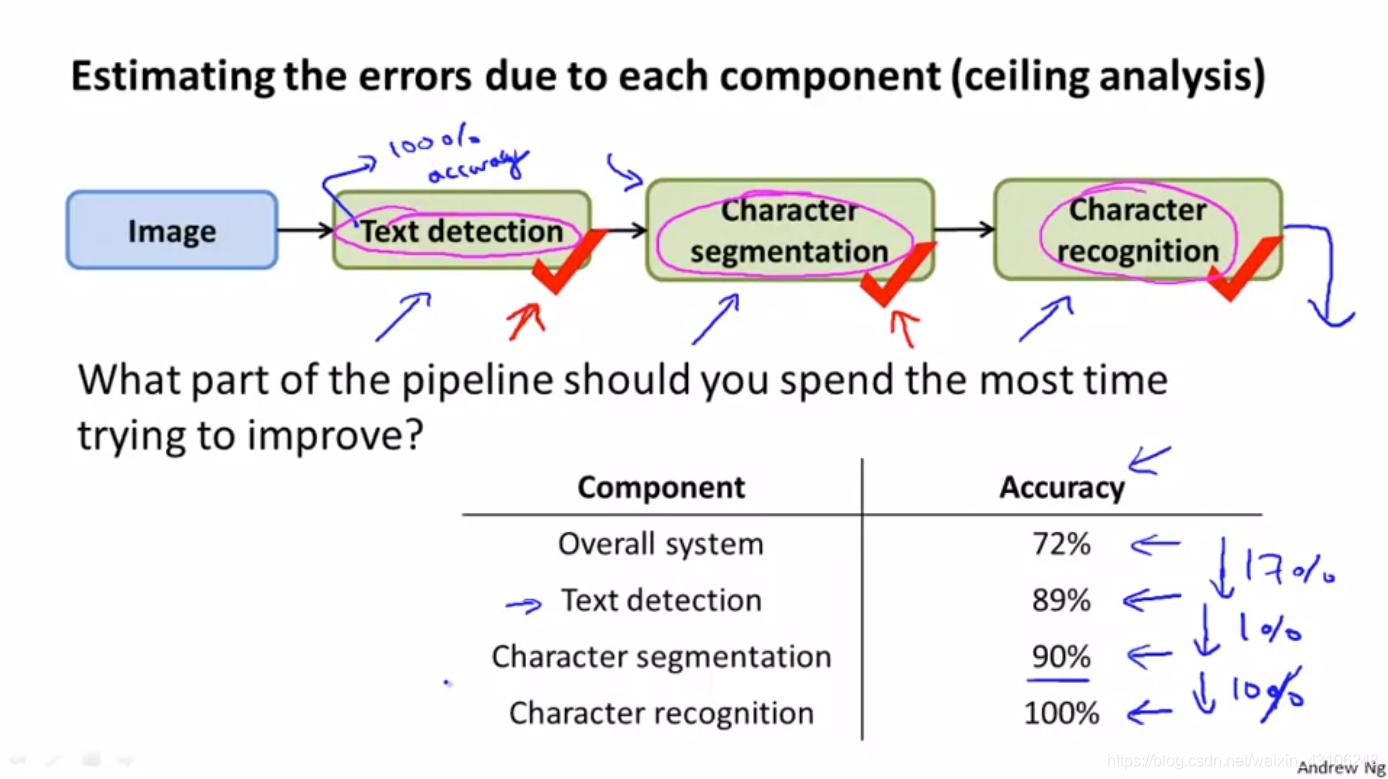
我们可以用Ceiling Analysis这种方法分析Photo OCR pipeline里的各个模块,发现系统的短板,以决定接下来做什么。
当前整个系统的输出准确率是72%
1、首先,确保text detection模块100%的准确率,即该模块的输出就是ground truth。这时测试系统的准确率,即在最优的text detection模型的前提下,系统可以达到的准确率上限,为89%,上涨17%。说明当前的text detection模块性能还有较大的提升空间。
2、然后,确保character segmentation模块100%的准确率,同上。在最优的text detection模型和character segmentation模型的前提下,系统可以达到的准确率上限,为90%,仅上涨1%。说明当前的character segmentation模型就算优化到100%的准确率,也只对系统准确率造成1%的影响,可见系统短板并不在这里。
3、最后,确保character recognition模块100%的准确率,同上。当所有模块都输出ground truth时,系统输出准确率自然达到100%,上涨10%. 这说明当前的character recognition模型的性能也有着一定的提升空间。
分析完毕,那么接下来的工作,在text detection和character recognition这两个模块上下工夫就好了。
这大概是Ceiling Analysis的思路,但我听完之后有一个很大的疑惑:最后的上限分析我认为是不科学的,没有进行控制变量。通常情况下准确率越接近100%越难提高。所以直接在之前的优化基础上进行下一步优化而后将其变化进行对比是欠妥当的。我认为应该分别对初始数据进行单一的优化,在观察那种优化效果更好,这样的对比才能让能人信服,你们说呢?
这篇关于关于Ceiling Analysis(上限分析)的思考的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






