本文主要是介绍文本分类(5)-TextCNN实现文本分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
利用TextCNN对IMDB Reviwe文本进行分类,数据集地址:https://pan.baidu.com/s/1EYoqAcW238saKy3uQCfC3w
提取码:ilze
import numpy as np
import loggingfrom keras import Input
from keras.layers import Conv1D, MaxPool1D, Dense, Flatten, concatenate, Embedding
from keras.models import Model
# from keras.utils import plot_model
from keras.utils.vis_utils import plot_model
import pandas as pd
import warnings
import keras
import re
import matplotlib.pyplot as plt
from nltk.stem import WordNetLemmatizer
from nltk.corpus import stopwords
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.layers import Dense, LSTM, Embedding, Dropout, Conv1D, MaxPooling1D, Bidirectional
from keras.models import Sequential
from keras.utils import np_utilswarnings.filterwarnings('ignore')# get data
df1 = pd.read_csv('word2vec-nlp-tutorial/labeledTrainData.tsv', sep='\t', error_bad_lines=False)
df2 = pd.read_csv('word2vec-nlp-tutorial/imdb_master.csv', encoding="latin-1")
df3 = pd.read_csv('word2vec-nlp-tutorial/testData.tsv', sep='\t', error_bad_lines=False)df2 = df2.drop(['Unnamed: 0','type','file'],axis=1)
df2.columns = ["review","sentiment"]
df2 = df2[df2.sentiment != 'unsup']
df2['sentiment'] = df2['sentiment'].map({'pos': 1, 'neg': 0})df = pd.concat([df1, df2]).reset_index(drop=True)train_texts = df.review
train_labels = df.sentimenttest_texts = df3.reviewdef replace_abbreviations(text):texts = []for item in text:item = item.lower().replace("it's", "it is").replace("i'm", "i am").replace("he's", "he is").replace("she's", "she is")\.replace("we're", "we are").replace("they're", "they are").replace("you're", "you are").replace("that's", "that is")\.replace("this's", "this is").replace("can't", "can not").replace("don't", "do not").replace("doesn't", "does not")\.replace("we've", "we have").replace("i've", " i have").replace("isn't", "is not").replace("won't", "will not")\.replace("hasn't", "has not").replace("wasn't", "was not").replace("weren't", "were not").replace("let's", "let us")\.replace("didn't", "did not").replace("hadn't", "had not").replace("waht's", "what is").replace("couldn't", "could not")\.replace("you'll", "you will").replace("you've", "you have")item = item.replace("'s", "")texts.append(item)return textsdef clear_review(text):texts = []for item in text:item = item.replace("<br /><br />", "")item = re.sub("[^a-zA-Z]", " ", item.lower())texts.append(" ".join(item.split()))return textsdef stemed_words(text):stop_words = stopwords.words("english")lemma = WordNetLemmatizer()texts = []for item in text:words = [lemma.lemmatize(w, pos='v') for w in item.split() if w not in stop_words]texts.append(" ".join(words))return textsdef preprocess(text):text = replace_abbreviations(text)text = clear_review(text)text = stemed_words(text)return texttrain_texts = preprocess(train_texts)
test_texts = preprocess(test_texts)max_features = 6000
texts = train_texts + test_texts
tok = Tokenizer(num_words=max_features)
tok.fit_on_texts(texts)
list_tok = tok.texts_to_sequences(texts)maxlen = 130seq_tok = pad_sequences(list_tok, maxlen=maxlen)x_train = seq_tok[:len(train_texts)]
y_train = train_labels
y_train = np_utils.to_categorical(y_train, num_classes=2)# 绘图
def show_history(trian_model):plt.figure(figsize=(10, 5))plt.subplot(121)plt.plot(trian_model.history['acc'], c='b', label='train')plt.plot(trian_model.history['val_acc'], c='g', label='validation')plt.legend()plt.xlabel('epoch')plt.ylabel('accuracy')plt.title('Model accuracy')plt.subplot(122)plt.plot(trian_model.history['loss'], c='b', label='train')plt.plot(trian_model.history['val_loss'], c='g', label='validation')plt.legend()plt.xlabel('epoch')plt.ylabel('loss')plt.title('Model loss')plt.show()def test_cnn(y,maxlen,max_features,embedding_dims,filters = 250):#Inputsseq = Input(shape=[maxlen],name='x_seq')#Embedding layersemb = Embedding(max_features,embedding_dims)(seq)# conv layersconvs = []filter_sizes = [2,3,4]for fsz in filter_sizes:conv1 = Conv1D(filters,kernel_size=fsz,activation='tanh')(emb)pool1 = MaxPool1D(maxlen-fsz+1)(conv1)pool1 = Flatten()(pool1)convs.append(pool1)merge = concatenate(convs,axis=1)out = Dropout(0.5)(merge)output = Dense(32,activation='relu')(out)output = Dense(units=y.shape[1],activation='sigmoid')(output)model = Model([seq],output)
# model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])return modeldef model_train(model, x_train, y_train):keras.callbacks.EarlyStopping(monitor='val_loss', patience=0, verbose=0, mode='auto')history = model.fit(x_train, y_train, validation_split=0.2, batch_size=100, epochs=20)return historymodel = test_cnn(y_train, maxlen, max_features, embedding_dims=128, filters=250)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])history = model_train(model, x_train, y_train)
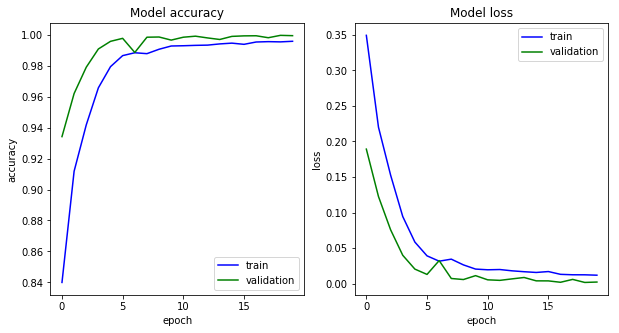
这篇关于文本分类(5)-TextCNN实现文本分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




