本文主要是介绍一堆Deep 生成模型:starGAN, UNIT, MUNIT,PWCT,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
更多内容可关注我的知乎专栏:https://zhuanlan.zhihu.com/ikerpeng
下面要介绍的这几种生成模型,主要集中在两种任务当中。一种是风格转换,另一种是跨域数据之间的转换(Cross-Domain Image-to-image)。使用的网络结构主要是自动编码器以及GAN。
StarGAN : yunjey/StarGAN
StarGAN将一个数据集上面学习到的知识转移到另一个数据集上面。如图所示:

输入单张图像,同时输入你想要得到的表情类别。于是该算法就给你生成这样的图片。值得注意的是在输入数据的域(domain)当中不存在这些表情的数据,而这些表情完全是从另一个数据域当中学习到的。
这篇文章最大的特点是使用单个的生成器实现了多个数据域当中的转换。并且生成的图片的质量相当的高。具体来说明该网络的优势。假设你有来至于4个不同的域的数据集,想要实现他们相互之间的转换,那么需要至少的训练12个生成器。然后,这篇文章巧妙的将 域的标签也作为输入,于是只需要单个的生成器就可以实现不同数据之间的转换:
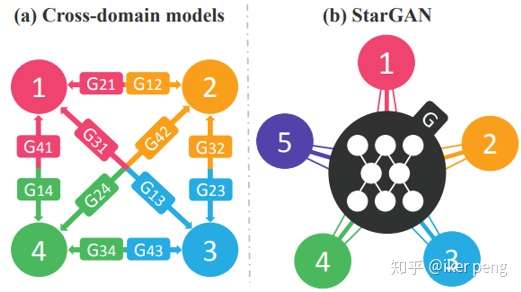
如图所示,其中的G表示的生成器,其中的不同数字表示的是数据集的域的标号。图的左边是传统的方法,需要12个生成器,而右边表示的就是是StarGAN的算法,这里将域的编号也输入要网络当中,实现各个数据集之间的转换只需要一个生成器。
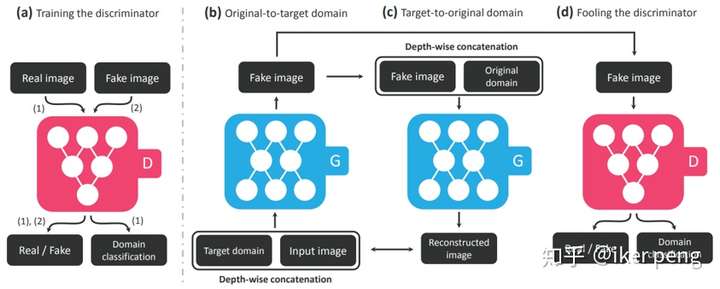
具体来看一下网络的结构。如上图所示, StarGAN当中还是包括了一个判别器(G)和一个生成器(D)。如图中的(b)所示,这个G的输入是一张图片和一个目标域的编号(实际训练当中使用的是一个掩码),由此生成一张图片Fake image A。那么图片A可以从两个方面来优化调整网络:一方面,把这张图片加上输入图片的域(original domain)作为G的输入,生成另一张图片B,这个过程可以看作是一个重构的过程,那么重构的误差要最小;另一个方面,生成的骗倒判别器。也是两个方面要骗倒才好:一方面是真伪,另一方面是域的标签。这样损失函数也就很清楚了。1. 对抗误差L_adv,也就是一般性的GAN的损失函数;2. 重构误差L_rec,只和G相关,为了增加重构图像的质量;3. 域的分类损失,L_cls。因此,我们可以得到如下的损失函数分别对分类器以及判别器进行训练更新。
这篇关于一堆Deep 生成模型:starGAN, UNIT, MUNIT,PWCT的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








