本文主要是介绍拓端tecdat|R语言基于递归神经网络RNN的温度时间序列预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近我们被客户要求撰写关于神经网络的研究报告,包括一些图形和统计输出。
在本文中,我们将介绍三种提高循环神经网络性能和泛化能力的高级技术。我们演示有关温度预测问题的三个概念,我们使用建筑物屋顶上的传感器的时间数据序列。
相关视频:LSTM神经网络架构和工作原理及其在Python中的预测应用
LSTM神经网络架构和原理及其在Python中的预测应用
概述
在本文中,我们将介绍三种提高循环神经网络性能和泛化能力的高级技术。在最后,您将了解有关将循环网络与Keras一起使用的大部分知识。您可以访问来自建筑物屋顶上的传感器的时间数据序列,例如温度,气压和湿度,这些数据点可用于预测最后一个数据点之后24小时的温度。这是一个相当具有挑战性的问题,它说明了使用时间序列时遇到的许多常见困难。
我们将介绍以下技术:
- 删除层/每层的单位数(模型) 如L1或L2正则化所述,过度复杂的模型更有可能过度拟合,可以使用删除来抵抗重复图层的过拟合。
- 堆叠循环层 —这增加了网络的表示能力(以更高的计算负荷为代价)。
- 双向循环层 —这些层以不同的方式向循环网络提供相同的信息,从而提高准确性。
温度预测问题
在本节的所有示例中,您将使用生物地球化学研究所的气象站记录的 天气时间序列数据集。
在此数据集中,几年中每10分钟记录14个不同的量(例如空气温度,大气压力,湿度,风向等)。原始数据可追溯到2003年,但此示例仅限于2009-2016年的数据。该数据集非常适合学习使用数字时间序列。您将使用它来构建一个模型,该模型将最近的一些数据(几天的数据点)作为输入,并预测未来24小时的气温。
下载并解压缩数据,如下所示:
unzip("climate.csv.zip",exdir = "~/Downloads/climate"
)我们看一下数据。
library(tibble)
library(readr)glimpse(data)
这是温度(摄氏度)随时间变化的曲线图。在此图上,您可以清楚地看到温度的年度周期。
ggplot(data, aes(x = 1:nrow(data), y = `degC`)) + geom_line()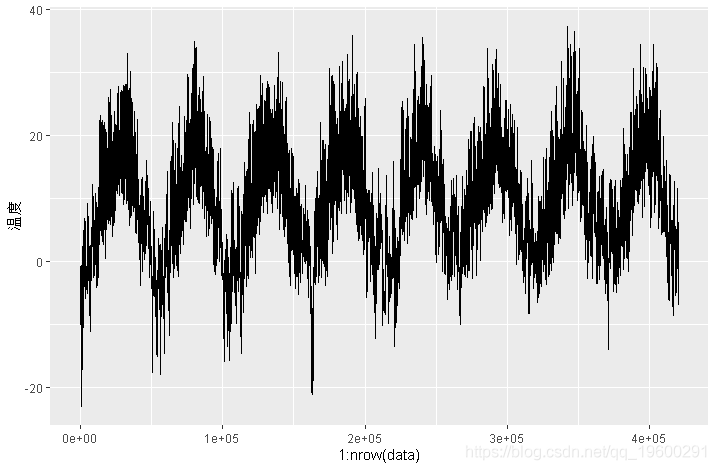
这是温度数据的前10天变化图。由于数据每10分钟记录一次,因此您每天可获得144个数据点。
ggplot(data[1:1440,], aes(y = `degC`)) + geom_line()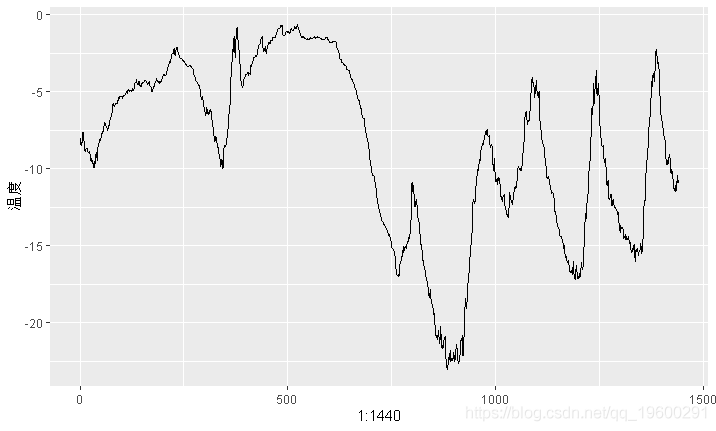
如果您根据过去几个月的数据来尝试预测下个月的平均温度,由于数据的年度周期性可靠,因此问题很容易解决。但是从几天的数据来看,温度更加混乱。这个时间序列每天都可以预测吗?
准备数据
问题的确切表达如下:给定的数据可以追溯到 lookback 时间步长(一个时间步长为10分钟)并在每个steps 时间步长处进行采样 ,您可以预测该delay 时间步长中的温度 吗?使用以下参数值:
lookback = 1440—观察将追溯到10天。steps = 6—观测将在每小时一个数据点进行采样。delay = 144—目标将是未来的24小时。
首先,您需要做两件事:
- 将数据预处理为神经网络可以使用格式。数据已经是数字了,因此您无需进行任何向量化。但是数据中的每个时间序列的度量尺度都不同(例如,温度通常在-20至+30之间,但以毫巴为单位的大气压约为1,000)。您将独立地标准化每个时间序列。
- 编写一个生成器函数,该函数将获取当前的浮点数据数组,并生成来自最近的过去以及将来的目标温度的成批数据。由于数据集中的样本是高度冗余的(样本 N 和样本 N + 1将具有大多数相同的时间步长),因此显式分配每个样本会很浪费。相反,您将使用原始数据即时生成样本。
生成器函数是一种特殊类型的函数,可以反复调用该函数以获得一系列值。
例如,sequence_generator() 下面的函数返回一个生成器函数,该 函数产生无限的数字序列:
gen <- sequence_generator(10)
gen()[1] 10gen()[1] 11生成器的当前状态value 是在函数外部定义的 变量。superassignment(<<-)用于从函数内部更新此状态。
生成器函数可以通过返回值NULL来指示完成 。
首先,将先前读取的R数据帧转换为浮点值矩阵(我们丢弃包含文本时间戳记的第一列):
data <- data.matrix(data[,-1])然后,您可以通过减去每个时间序列的平均值并除以标准差来预处理数据。您将使用前200,000个时间步作为训练数据,因此仅在这部分数据上计算均值和标准差以进行标准化。
train_data <- data[1:200000,]
data <- scale(data, center = mean, scale = std)您将使用的数据生成器的代码如下。它产生一个list (samples, targets),其中 samples 是一批输入数据,并且 targets 是目标温度的对应数组。它采用以下参数:
data—原始的浮点数据数组。lookback—是输入数据应该包括多少个时间步。delay—目标应该在未来多少步。min_index和max_index—data数组中的索引, 用于定义从中提取时间步长。保留一部分数据用于验证和另一部分用于测试。shuffle—随机整理样本还是按时间顺序绘制样本。batch_size—每批样品数。step—采样数据的时间段(以时间为单位)。您将其设置为6,以便每小时绘制一个数据点。
现在,让我们使用abstract generator 函数实例化三个生成器:一个用于训练,一个用于验证以及一个用于测试。每个人都将查看原始数据的不同时间段:训练生成器查看前200,000个时间步,验证生成器查看随后的100,000个时间步,而测试生成器查看其余的时间步。
lookback <- 1440
step <- 6# 为了查看整个验证集,需要从valu gen中提取多少步骤
val_steps <- (300000 - 200001 - lookback) / batch_size# 为了查看整个测试集,需要从test\u gen中提取多少步骤
test_steps <- (nrow(data) - 300001 - lookback) / batch_size常识性的非机器学习基准
在开始使用黑盒深度学习模型解决温度预测问题之前,让我们尝试一种简单的常识性方法。它将用作健全性检查,并将建立一个基线,您必须超过它才能证明机器学习模型的有用性。当您要解决尚无已知解决方案的新问题时,此类常识性基准可能会很有用。一个经典的例子是不平衡的分类任务,其中某些类比其他类更为常见。如果您的数据集包含90%的A类实例和10%的B类实例,则分类任务的常识性方法是在提供新样本时始终预测“ A”。此类分类器的总体准确度为90%,因此,任何基于学习的方法都应超过90%的分数,以证明其有用性。
在这种情况下,可以安全地假定温度时间序列是连续的(明天的温度可能会接近今天的温度)。因此,常识性的方法是始终预测从现在开始24小时的温度将等于现在的温度。我们使用平均绝对误差(MAE)指标评估这种方法:
mean(abs(preds - targets))评估循环。
for (step in 1:val_steps) {preds <- samples[,dim(samples)[[2]],2]mae <- mean(abs(preds - targets))batch_maes <- c(batch_maes, mae)}print(mean(batch_maes))
MAE为0.29。由于温度数据已标准化为以0为中心并且标准偏差为1。它的平均绝对误差为0.29 x temperature_std 摄氏度:2.57˚C。
celsius_mae <- 0.29 * std[[2]]那是一个相当大的平均绝对误差。
基本的机器学习方法
就像在尝试机器学习方法之前建立常识性基准很有用一样,在研究复杂且计算量大的模型之前,尝试简单的机器学习模型也很有用。
下面的清单显示了一个全连接的模型,该模型首先将数据展平,然后在两个密集层中运行它。请注意,最后一个致密层上缺少激活函数,这对于回归问题是很典型的。您将MAE用作损失函数。由于您评估的数据与通常方法完全相同,而且度量标准完全相同,因此结果可以直接比较。
model_sequential() %>% layer_flatten(input_shape = c(lookback / step, dim(data)[-1])) %>% history <- model %>% fit_generator(train_gen,steps_per_epoch = 500,epochs = 20,validation_data = val_gen,validation_steps = val_steps
)让我们显示验证和训练的损失曲线。
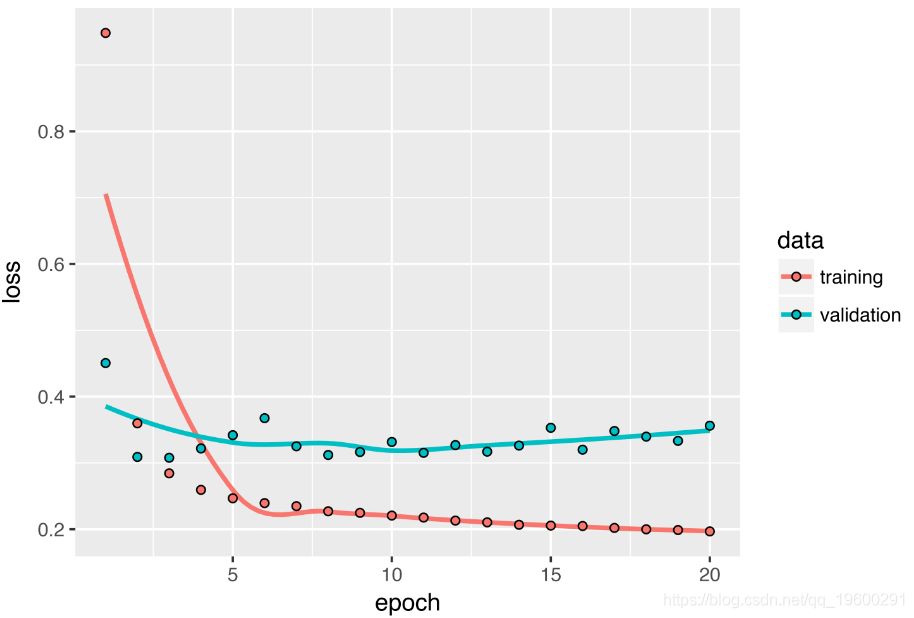
某些验证损失接近无学习基准,但不可靠。这首先显示了具有此基准的优点:事实证明,要实现这一目标并不容易。您的常识包含很多机器学习模型无法访问的有价值的信息。
您可能想知道,如果存在一个简单的,性能良好的模型,为什么您正在训练的模型找不到并对其进行改进?因为这种简单的解决方案不是您的训练设置所需要的。您要在其中寻找解决方案的模型的空间已经相当复杂。当您正在寻找具有两层网络空间的复杂模型解决方案时,即使在技术上是假设简单,性能良好的基准模型也可能无法学习。通常,这是机器学习的一个相当大的局限性:除非对学习算法进行硬编码来寻找特定类型的简单模型,
基准模型
第一种全连接的方法效果不好,但这并不意味着机器学习不适用于此问题。先前的方法首先使时间序列平坦化,从而从输入数据中删除了时间概念。我们将尝试一个递归序列处理模型-它应该非常适合此类序列数据,因为与第一种方法不同,正是因为它利用了数据点的时间顺序。
您将使用Chung等人开发的 GRU层。在2014年。GRU层使用与LSTM相同的原理工作,但是它们有所简化,因此运行起来更高效。在机器学习中到处都可以看到计算复杂度和效率之间的折衷。
model_sequential() %>% layer_gru(units = 32, input_shape = list(NULL, dim(data)[[-1]])) %>% layer_dense(units = 1)model %>% fit_generator(train_gen,steps_per_epoch = 500,epochs = 20,
结果如下图所示。您可以超越基线模型,证明了机器学习的价值以及循环网络的优越性。
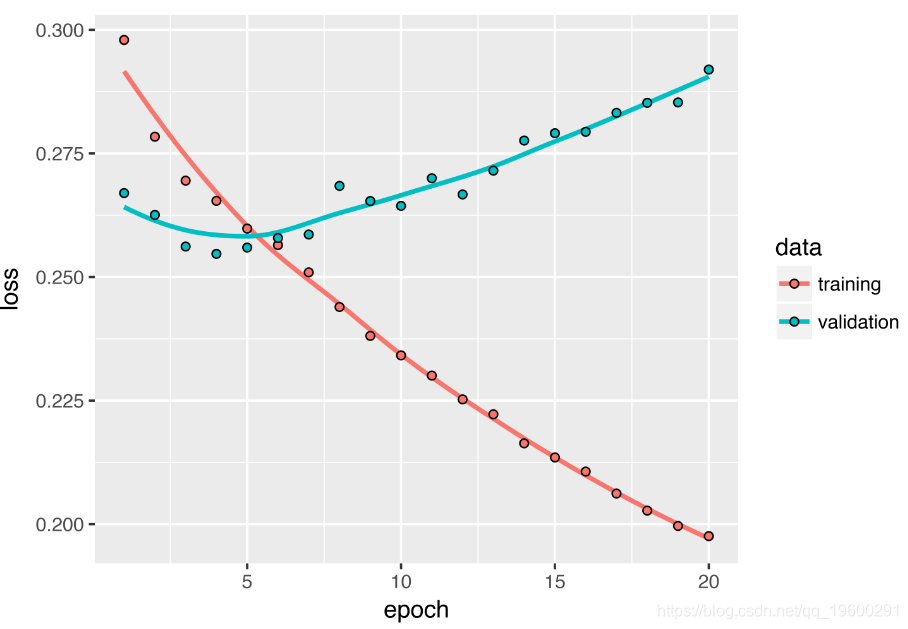
验证MAE转化为非标准化后的平均绝对误差为2.35˚C。
丢弃(dropout)对抗过度拟合
从训练和验证曲线可以明显看出该模型是过拟合的:训练和验证损失在经过几个时期后开始出现较大差异。您已经熟悉了应对这种现象的经典技术:丢弃(dropout),它随机将图层的输入单元清零,以便打破该图层所暴露的训练数据中的偶然相关性。但是,如何在循环网络中正确应用dropout并不是一个简单的问题。道在递归层之前应用dropout会阻碍学习,而不是帮助进行正则化。2015年,Yarin Gal作为其博士学位论文的一部分 在贝叶斯深度学习中,确定了使用递归网络进行dropout的正确方法:应在每个时间步上应用相同的dropout模式,而不是随时间步长随机变化的dropout模式。
Yarin Gal使用Keras进行了研究,并帮助将这种模型直接构建到Keras循环层中。Keras中的每个循环图层都有两个与dropout相关的参数: dropout,一个浮点数,用于指定图层输入单元的dropout率;以及 recurrent_dropout,用于指定循环单元的dropout率。由于使用丢失dropout进行正则化的网络始终需要更长的时间才能完全收敛,因此您需要两倍的时间训练网络。
model_sequential() %>% layer_gru(units = 32, dropout = 0.2, recurrent_dropout = 0.2,
下图显示了结果。在前20个时期中,您不再过度拟合。但是,尽管您的评估分数较为稳定,但您的最佳分数并没有比以前低很多。

堆叠循环图层
因为您不再需要考虑过度拟合的问题,而是似乎遇到了性能瓶颈,所以您应该考虑增加网络的容量。回想一下通用机器学习工作流程的描述:在过拟合成为主要障碍之前,最好增加网络容量,这通常是个好主意(假设您已经采取了基本步骤来减轻过拟合的情况,例如使用丢弃)。只要您的拟合度不会太差,就很可能会出现容量不足的情况。
通常,通过增加层中的单元数或添加更多层来增加网络容量。递归层堆叠是构建功能更强大的递归网络的经典方法:例如,当前为Google Translate算法提供动力的是七个大型LSTM层的堆叠。
为了在Keras中将递归层堆叠在一起,所有中间层都应返回其完整的输出序列(3D张量),而不是最后一个时间步的输出。
model_sequential() %>% layer_gru(units = 32, dropout = 0.1, recurrent_dropout = 0.5,return_sequences = TRUE,input_shape = list(NULL, dim(data)[[-1]])) %>% layer_gru(units = 64, activation = "relu",dropout = 0.1,recurrent_dropout = 0.5) %>%
下图显示了结果。您可以看到,添加的图层确实改善了结果,尽管效果不明显。您可以得出两个结论:
- 因为不需要过度拟合的问题,所以可以安全地增加图层大小以寻求验证损失的改善。但是,这具有不可忽略的计算成本。
- 添加层并没有很大的帮助,因此此时您可能会看到网络容量增加带来的收益递减。
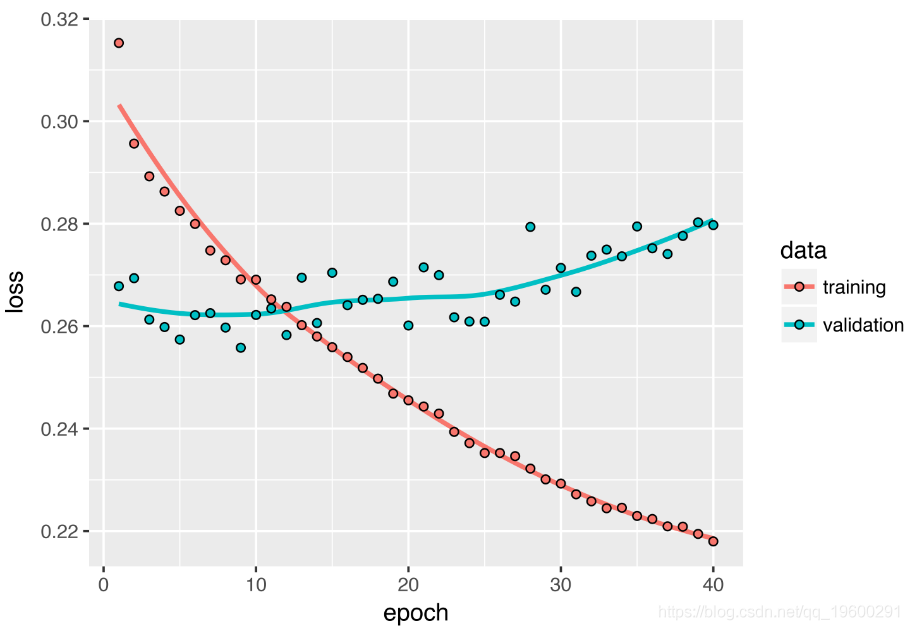
使用双向RNN
本节介绍的最后一种技术称为 双向RNN。双向RNN是常见的RNN变体,在某些任务上可以提供比常规RNN更高的性能。它在自然语言处理中经常使用-您可以将其称为用于深度语言处理的深度学习“瑞士军刀”。
RNN特别依赖于顺序或时间的:它们按顺序处理输入序列的时间步长,重新排列时间步长可以完全改变RNN从序列中提取的表示形式。这正是它们在序列问题(例如温度预测问题)上表现良好的原因。双向RNN利用RNN的序列敏感性:它包含使用两个常规RNN(例如 layer_gru 和 layer_lstm ),每个RNN都沿一个方向(按时间顺序)处理输入序列,然后合并它们的表示形式。通过双向处理序列,双向RNN可以捕获被单向RNN忽略的模式。
值得注意的是,本节中的RNN层已按时间顺序处理了序列。训练与本节第一个实验中使用相同的单GRU层网络,您将获得如下所示的结果。
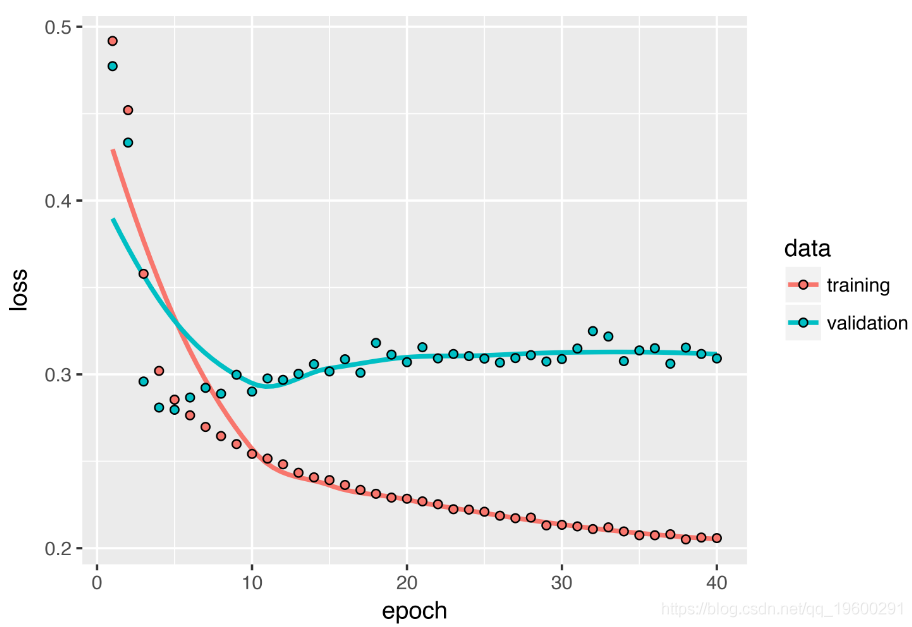
结果表明在这种情况下,按时间顺序进行的处理至关重要。因为:底层的GRU层通常更容易记住最近的过去,自然地,较新的天气数据点比旧数据点对问题的预测能力强。因此,该层的时间顺序版本必将胜过逆序版本。对于包括自然语言在内的许多其他问题,情况并非如此:从直觉上讲,单词在理解句子中的重要性通常并不取决于其在句子中的位置。让我们在LSTM IMDB示例中尝试相同的技巧。
# 作为特征考虑的单词数量
max_features <- 10000 c(c(x_train, y_train), c(x_test, y_test)) %<-% imdb# 反转序列
x_train <- lapply(x_train, rev)
x_test <- lapply(x_test, rev) model <- keras_model_sequential() %>% layer_embedding(input_dim = max_features, output_dim = 128) %>% layer_lstm(units = 32) %>% 您获得的性能几乎与按时间顺序排列的LSTM相同。值得注意的是,在这样的文本数据集上,逆序处理与按时间顺序处理一样有效,这证实了以下假设:尽管单词顺序 在理解语言中确实很重要, 但 您使用的顺序并不重要。重要的是,经过逆向序列训练的RNN将学习与原始序列训练的RNN不同的表达方式。在机器学习中, 不同 的表示 总是值得开发的:它们提供了一个新的视角来查看您的数据,捕获了其他方法遗漏的数据方面,因此可以帮助提高任务的性能。
双向RNN利用此思想来改进按时间顺序排列的RNN的性能。
在Keras中实例化双向RNN。让我们在IMDB情绪分析任务上尝试一下。
model <- keras_model_sequential() %>% layer_embedding(input_dim = max_features, output_dim = 32) %>% bidirectional(layer_lstm(units = 32)model %>% compile(optimizer = "rmsprop",loss = "binary_crossentropy",它的性能比您在上一节中尝试过的常规LSTM稍好,达到了89%以上的验证精度。它似乎也可以更快地过拟合,这并不奇怪,因为双向层的参数是按时间顺序排列的LSTM的两倍。通过一些正则化,双向方法可能会在此任务上表现出色。
现在让我们在温度预测任务上尝试相同的方法。
model_sequential() %>% bidirectional(layer_gru(units = 32), input_shape = list(NULL, dim(data)[[-1]])model %>% fit_generator(train_gen,steps_per_epoch = 500,epochs = 40,
这和常规的layer_gru一样好 。原因很容易理解:所有预测能力都必须来自网络中按时间顺序排列的部分,因为众所周知,按时间顺序排列的部分在此任务上的表现严重不足,在这种情况下,最近的样本比过去的样本重要得多。
更进一步
为了提高温度预测问题的性能,您可以尝试其他许多方法:
- 调整堆叠设置中每个循环图层的单位数。
- 调整
RMSprop优化器使用的学习率 。 - 尝试使用
layer_lstm代替layer_gru。 - 尝试在循环层的顶部使用更大的紧密连接的回归变量:即,更大的密集层,甚至一叠密集层。
- 不要忘记最终在测试集上运行性能最佳的模型(就验证MAE而言),否则,您将开发过度拟合验证集的结构。
我们可以提供一些准则,建议在给定问题上可能起作用或不起作用的因素,但是最终,每个问题都是唯一的;您必须凭经验评估不同的策略。当前没有理论可以提前准确地告诉您应该如何最佳地解决问题。您必须迭代。
这篇关于拓端tecdat|R语言基于递归神经网络RNN的温度时间序列预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


