本文主要是介绍加量不加价!扩增子新版分析流程结果解读(二),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在上期内容中,我们介绍了升级后的扩增子分析结果中的差异分析和环境因子关联分析,今天继续来了解其他的分析内容吧!
一、随机森林分析
随机森林是机器学习算法的一种,目的是根据已有的数据建立模型,从而实现对数据的分类和对其它指标的预测。如果目标变量是分类变量,随机森林可以进行分类;如果目标变量是连续变量,随机森林可以进行回归预测,此外在建立随机森林模型的过程中,还可以找出能够区分不同组样本间差异的关键物种或OTU。
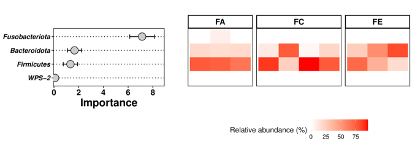
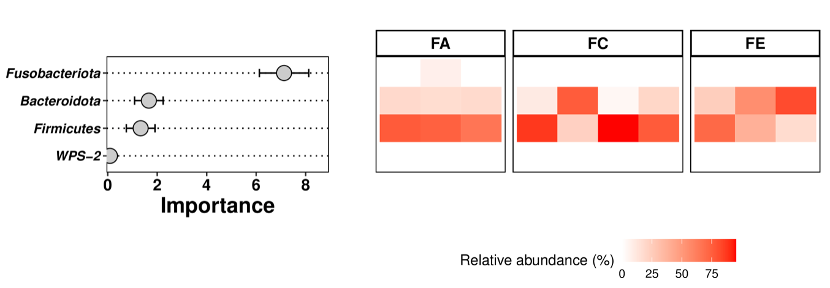
随机森林关键物种贡献度
注意事项:大样本量进行随机森林分析结果更可靠哦
二、功能预测分析
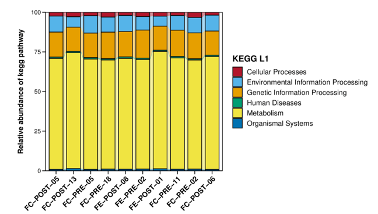
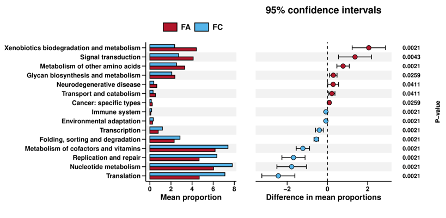
根据已知的微生物基因组数据,对微生物群落进行菌群代谢功能的预测,从而把物种的“身份”和它们的“功能”对应起来。根据菌群代谢功能预测结果,我们一方面能一窥菌群功能谱的概貌,发挥菌群多样性测序性价比高的优势;另一方面也能帮助指导后续的实验设计,更合理地筛选用于后续研究的样本。在凌恩生物结题报告中提供了PICRUSt、Tax4Fun和FAPROTAX三种功能预测分析内容。
功能丰度组间差异展示
功能注释相对丰度堆积冲击图
注意事项:Tax4Fun和FAPROTAX软件只适用于16S rRNA数据
除以上这些分析外,针对医学领域客户专门新增了医学版扩增子结题报告,欢迎继续锁定凌恩生物公众号,我们下期见!
这篇关于加量不加价!扩增子新版分析流程结果解读(二)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






