本文主要是介绍综合工具-Design Compiler使用(从RTL到综合出各种报告timing\area\critical_path),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
之前讲过gvim、vcs、makefile的使用,相当于自己写出一个RTL代码,可以实现编译、仿真及脚本自动化控制操作。
本篇专栏讲讲自己写出一个RTL code之后如何对其进行综合,能够看到我们写的代码的timing报告、面积报告以及critical path。
逻辑综合(synthesis)就是将前端设计工程师编写的RTL代码,映射到特定的工艺库上,通过添加约束信息,对RTL代码进行逻辑优化,形成门级网表。
整个ASIC设计可以如下描述:
产生想法->说明文档spec->根据文档编写RTL code->RTL仿真/验证->综合产生门级网表->物理布局布线->tape out。
对于逻辑综合步骤来说,我们通常使用的工具为Design Compiler,将一个RTL code在DC里做综合时,工具会先将代码转换成一个GTECH网表(generic technology (GTECH)netlist),然后在映射不同的工艺库形成真正的门级网表。
具体的实现思路就是:
①先加载工艺库(是使用台积电的,还是中芯国际的,又是多少纳米的?是一个.db文件)和RTL文件。
②添加时序约束和设计约束。(添加约束后工具才能根据你下的约束做逻辑优化)
③得到工艺库+RTL设计+约束文件后,就可以进行综合了。
④综合完毕,就要对综合的结果进行分析。看时序报告、面积报告、功耗报告。看这些报告看有没有出现一些错误。
⑤如果有问题就改设计,如果没有问题,就导出成一个ddc的网表,提供给后端人员做布局布线。
在DC中有两种library,target library 和 link library;其中target library是你在做综合的时候,使用的库(可以使用代码段:set_app_var target_library 90nm_typical.db 指定target library)。一般来说在设计里面把 link library 和 target library 都指定为同一个,只有在要修改设计所综合工艺时才会改link library,举个例子,如果需要将已有的设计从一个工艺 A 转到另一个工艺 B 时,可以将当前单元综合库 A 设为 link_library,而将单元综合库 B 设为 target_library ,重新映射一下即可,之所以说一般设定为一个值,因为要流片找对应的厂商一般工艺都是确定的,所以不会中途要修改工艺的情况,这个了解一下就好。
在使用DC前,如果是第一次使用,需要指定一个library的工作目录,以及指定所使用的target library和link library。
指定完使用的库之后,DC工具需要读入RTL文件,使用命令:read_verilog "TOP.v a.v b.c",输入了三个.v的设计文件。
但是我们通常会有很多RTL文件,但是只有一个顶层文件,所以需要指定一下告诉DC工具哪个是顶层,使用代码:current_design TOP。就可以指定module TOP为整个项目的顶层,要注意的是这里的TOP指的是module名,而不是文件名。
读入设计后,需要加时序约束,要下的时序约束有很多,比如说:
① 期望时钟的时钟频率是多少?create_clock -period 10 [get_ports CLK] (创建一个时钟,时钟的周期为10ns,对应的端口名为CLK。)
② 时钟的抖动为多少?set_clock_uncertainty -setup 0.3 [get_clocks CLK] (设置时钟沿的抖动为0.3ns,可能提前0.3,也可能落后0.3ns)
③ 时钟的翻转时间为多少? set_clock_transition -max 0.15 [get_clocks CLK](这个设置的原因是,我们理想的时钟翻转时间是为0的,直上直下,但实际上时钟的翻转跳变是需要时间的,并非直上直下,这条代码就是设置时钟的翻转时间为0.15ns)
④ 时钟延时为多少?set_clock_latency -max 0.7 [get_clocks CLK] (时钟的传播是有时间的,从产生时钟的晶振到需要时钟的模块,中间的传输时间为多少?就是这里设置的clock_latency)
⑤ 输入延时(input_delay)为多少?set_input_delay -max 0.6 -clock CLK [get_ports A](这个是针对数据来的,数据从时钟边沿开始,最延时多久才能从输入端口进来)
⑥ 输出延时(output_delay)为多少?set_output_delay -max 0.8 -clock CLK [get_ports B] (输出可接受最大延时为多少,然后DC根据你下的约束去综合内部的组合逻辑)
⑦ 输入传输延时为多少? set_input_transition 0.12 [get_ports A],输入的数据的翻转也不是理想的,从0-1的翻转并非直上直下,需要一定的时间。
Performs three levels of optimization 优化主要从三个方面进行
1.Architectural level synthesis --架构优化 插入buffer等
2.Logic level or GTECH optimization --逻辑优化 卡诺图化简等
3.Gate-level or mapping optimization --门级优化 选择用大与门,小与门等
优化的条件:先满足时序约束,再优化面积。Minimize area while meeting timing constrain
编译完了之后下面就是看我们的综合报告了
输入:report_qor 查看综合的概况(quality of result 即qor) ,可以看到关键路径的长度、裕量、周期、面积等。

输入 report_timing 会得到一些DC做STA的一些报告,每一条路的时序路径的延时之类的,从某个端口到某个端口之间的延时,分析整个电路的最大延时。
在报告的底部会有一个slack,就是时间裕量,如何判断时序是否满足要求就看这个slack是否为正,如果为正那就是满足要求(显示MET),如果为负那就是不满足要求(VIOLATE 违例),即时间裕量不够。
输出约束文件:write_sdc my_design.sdc
输出ddc,就是约束文件和综合后得到的网表:write -f ddc -hier -output my_ddc.ddc
write -f verilog -hier -output my_design.gv 输出门级设计文件,一般还要输出 sdf 时延文件,然后用这两个文件去做后仿真。
Design Compiler可以使用界面模式也可以使用脚本模式,可以在terminal界面输入:design_vision打开界面化的DC,也可以输入dc_shell使用脚本模式的DC。

OK,上面简单的讲了一些使用DC的前置知识,下面来结合一个例子实操一下,拿到一个.v文件之后,怎么使用DC做综合,然后得出我们想要的timing、area报告、sdf 时延文件、网表文件等一系列流程。
第一步,写好一个需要做综合的RTL代码,这里up用的是一个全加器RTL,如下图:

然后创建一个library文件夹,把 /opt/Foundary_Library/TSMC90/aci/sc-x/synopsis 里的.db文件全部copy到新建的library中,这些文件都是工艺库文件,后续DC设置需要使用这些东西。

复制完之后,文件夹如上所示。
此时,library的上一级文件夹是这样的:

接着启动DC:在terminal界面输入dc_shell启动DC:

输入set_app_var -search_path ./library ,把DC读取工艺库的路径设置到我们当前目录的library下,设置完路径后还需要设置target library 和link library;继续在terminal中输入set_app_var target_library typical.db 设置好目标库,继续set_app_var link_library typical.db
输入完后,dc_shell的界面如下所示:

使用的工艺库都设置完了,下面就需要把我们之前写好的RTL code导入到DC中,输入:read_file -format verilog {/opt/bilibili_DC_pra/full_adder.v} 把全加器RTL文件读入进来,因为路径都不一样,所以大家可以改成自己的路径再读取,如果读取还出错,那就在dc_shell中输入start gui,这个意思是启动界面化操作,然后在界面化的左上角导入RTL文件即可。
导入成功之后,DC显示如下信息,包含输出信号的类型和位宽:

为了验证我们目前的读入代码是否成功,在dc_shell中输入:check_design来检查设计:

如果和上图显示的一样,显示1,那就代表没有错误。
没有错误就可以给设计下约束了,新建一个时钟,在dc_shell中输入:
create_clock -period 10 [get_ports clk] 和前面基础部分解释的一样,创建一个周期为10的时钟,连接着clk端口。
给输入的引脚设置相关的输入延时,比如说给除了时钟以外的所有引脚都设置input_delay为3,并且输入的input_delay是相对于clk而言的:
set_input_delay -max 3 -clock clk [remove_from_collection [all_inputs] clk]

在DC中显示1,表示没问题。
接着设置输出的output_delay,比如设置输出的最大output_delay为2.5:
set_output_delay -max 2.5 -clock clk [all_outputs]
接着设置所有输入信号的翻转时间:set_input_transition 0.15 [all_inputs]
好,这样我们约束写完了,再check_design一下确认没有问题。

显示1,没有问题后,我们就可以开始跑综合了:直接在dc_shell中输入compile

DC就帮我们跑综合,并输出一些报告了,最后显示优化完成:

综合完之后我们就能让它report一些我们想要看到的东西,比如一开始我们create了一个10ns为周期的时钟,我们可以输入:report_clock 来看到我们当时设定的时钟:
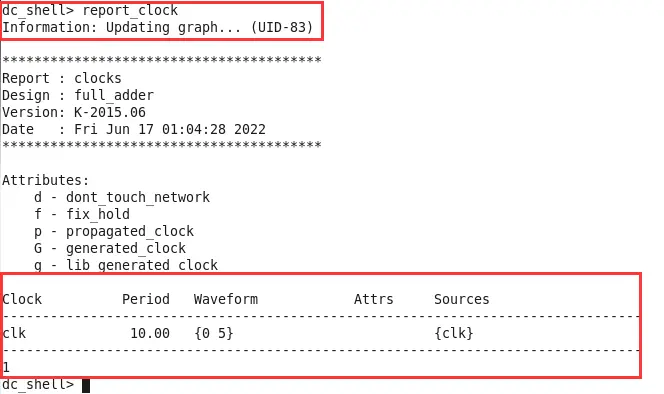
接着看我们想看的时序报告,看在我们设置的这些时序约束下,整个设计是否会出现时序违例,输入:report_timing:

可以看到,时间裕量还有很多,slack显示MET,表示满足要求,如果不满足的话,会显示VIOLATE违例。
除了timing报告外,我们可能还会看面积,输入:report_area可以查看综合后的面积报告

在面积报告里面没有线网所消耗的面积,这是因为我们之前没有规定综合使用的线网模型,如果我们设置了wire_load那么最后的area报告里面也会有布线所花的面积。
另外的,如果我们要把我们在dc_shell中输入的那些约束信息,全部打印出来,生成一个.sdc结尾的时序约束文件,可以在dc_shell中输入:write_sdc full_adder.sdc


输出成功后,可以看到文件夹里面多出了一个sdc文件,以及可以看到sdc文件中就是我们写的那些约束:

同理,我们也可以输出用于做后仿的.sdf时延文件:write_sdf full_adder.sdf,而要跑后仿的话,除了时延文件,还要RTL的网表文件,所以我们再输出RTL的网表文件:write_file -format verilog -output full_adder_netlist.v

看网表文件可以发现,RTL代码已经都变成门级的东西了。
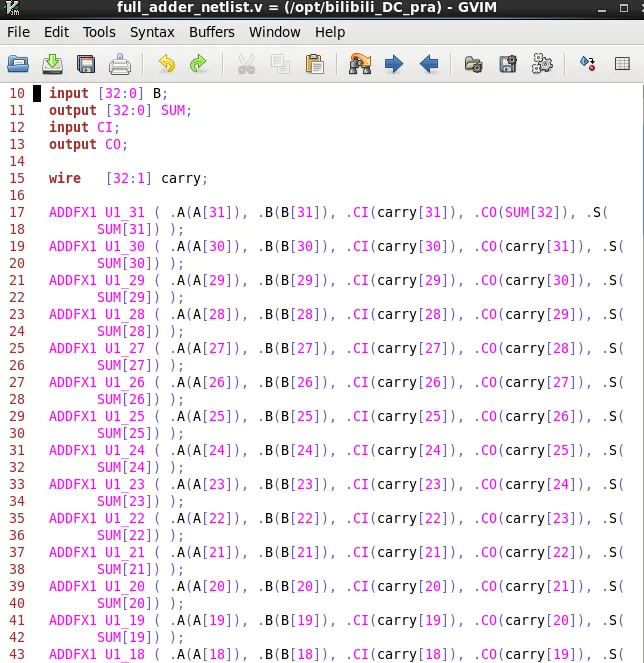
设计人员在和后端的做交互的时候,就交付给他们时延文件sdf文件和RTL的网表文件即可。
如果在综合的时候时序违例了,该怎么看critical_path呢,为了测试违例情况,我们把时钟周期设置成2ns,故意让它违例:create_clock -period 2 [get_ports clk]
修改时钟后,再compile一次,compile完report_timing。
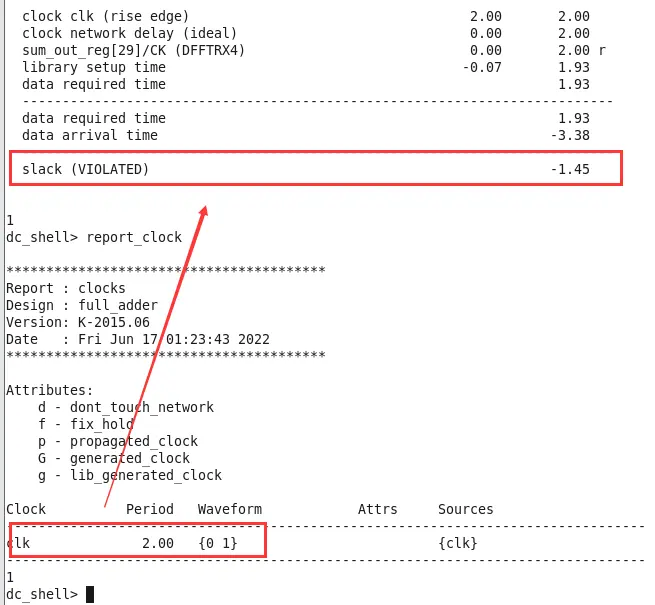
我们可以看到,当把时钟周期设置为2ns的时候,出现了时序违例,时间裕量那边也显示了VIOLATED
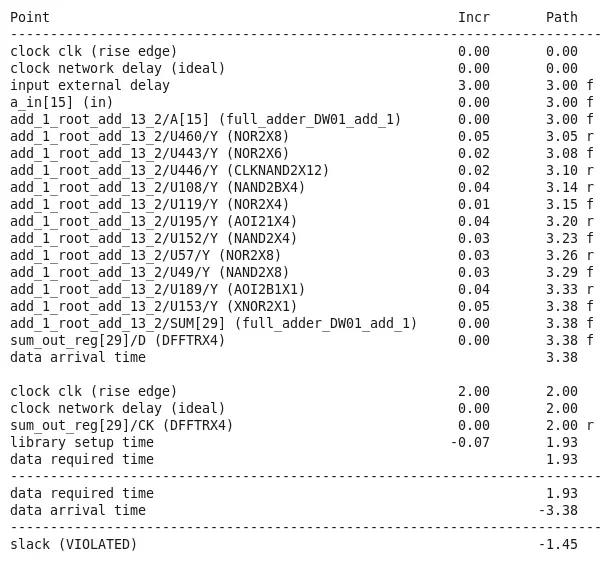
在timing报告里面,就直接显示了关键路径的走势,可以看到data_require是1.93ns,但是data_arrival time 却为-3.38ns,出现时序违例。
好,从0到看报告的DC综合教程到这里就结束了,up简单讲几句话:对于初学者来说,一下子接触那么多命令肯定是措手不及的,感觉那么多东西怎么可能记得住,我想说的是,虽然命令很多,但其实用的很多的就是我列举的那么些,刚开始接触可能一下子记不得,但是用多了,就很熟练打出来了。就好比linux操作系统,“cd ..”是返回到上一个文件夹,pwd是查看当前路径,rm是删除,cp是复制。mkdir是创建文件夹,ls是查看当前文件夹内容,你看,我说了那么多命令,你大概率每一个都很熟悉,因为在使用linux操作系统的时候,这些命令太常见了,而DC里面无论是设置路径也好,设置目标工艺库也好,下时序约束也好,用到的命令也就那些东西,一开始迷迷糊糊没事,你就记住,多练多coding,自然就熟悉了。
这篇关于综合工具-Design Compiler使用(从RTL到综合出各种报告timing\area\critical_path)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






