本文主要是介绍打破局限,西门子数控免授权数据采集实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
功能介绍:西门子828D,840DSL,808,802DSL通用数据采集程序
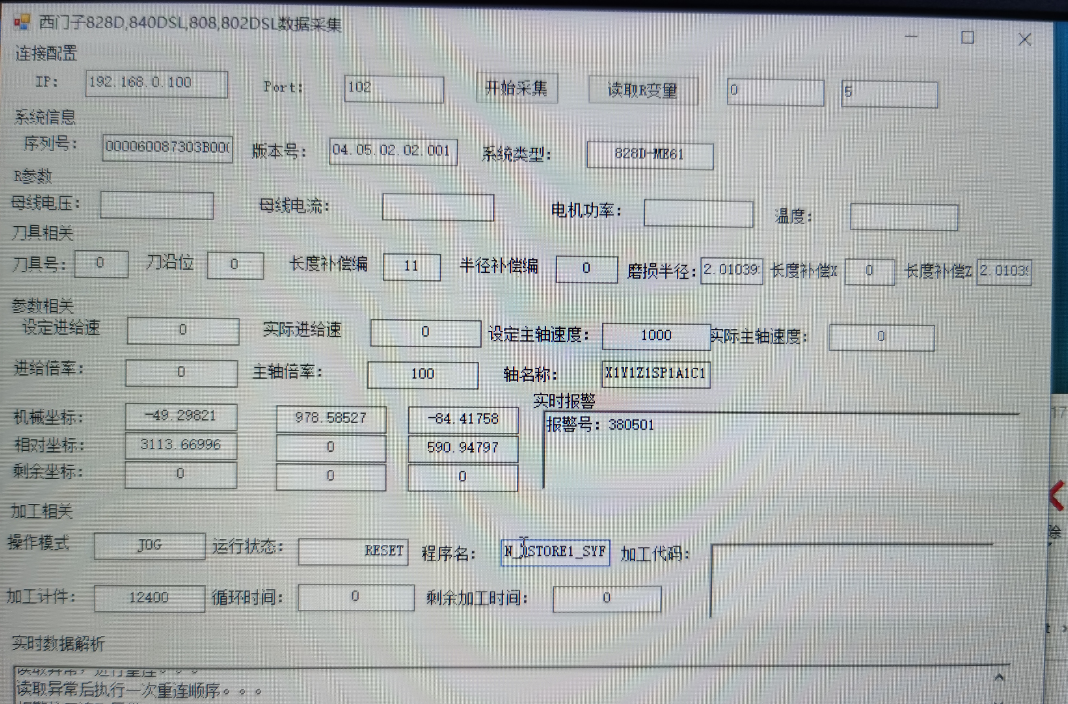
1.通过tcp发底层通信报文的方式获取数据。项目中亲测OK。
2.有些人破解协议不完整,或程序写得有问题,是容易导致机器报警的,西门子的很娇气的,挂子就等着叫维护的过来吧。
关注公众号:机床云,随时查看最新文章。

关注的我boke: https://www.cnblogs.com/bgh408/
3.功能看上去简简单单,资料都是精心总结的内容,经过实战沉淀的精华,必定付出这么多精力,你也不会免费要吧?自己的每天的收入多少?500、400、350、250?要多少天才能收集这些资料,实现这些功能,踩完这些坑?10天?一个月?两个月?我们的出发点是为客户创造价值,而不是浪费客户的资源,我们现在服务针对企业付费用户,建议申请企业资源获取服务。
为什么要去买经验---摘自《一年顶十年》
我们进入一个的领域并要深入,如果只靠自己摸索,很可能事倍功半,甚至会举步维艰。
学习者对知识和信息往往没有什么判断力,如果只是自己在网上搜来搜去,效率是非常低的,而且容易被误导。
有些时候,单靠自己折腾,会让事情变得更复杂,要是找到对的人,买他们的经验,事情则会变得简单很多。
千万不要只是埋头苦学。买经验,是必须做的事情,这样可以少走很多弯路,加速自己的进步。
这篇关于打破局限,西门子数控免授权数据采集实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






