本文主要是介绍论文阅读-Structure-based Generation(SBG) System for E2E NLG Challenge,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
两步走策略:
- 句子规划:设计句子结构,留有相应的空等待填充(对应下图Structure)
- 文案实现:把值填到对应的位置(对应下图NL Reference)

系统流程图:
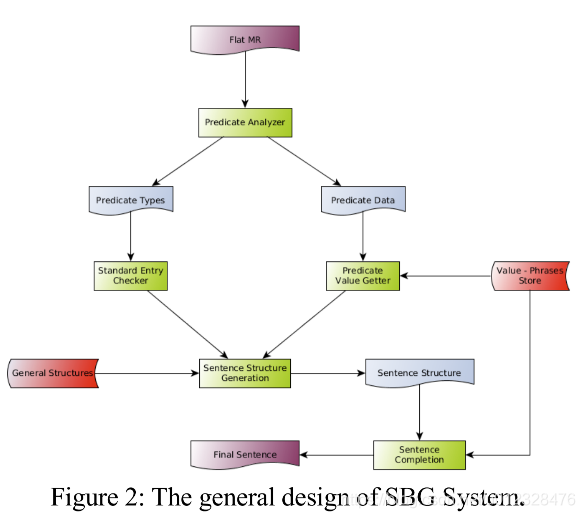
RuleBased就是怎么规划和实现都是有对应策略的,有的比较取巧,有的也是根据经验。anyway效果还不错。
模块介绍
Structure Builder
首先,分析E2E数据集,根据MR的pragmatic meaning将要预测的八个type划分成五类(Meaning),并给出之间的关系(个人理解这就是RuleBased)
仍以上图中的MR为例,
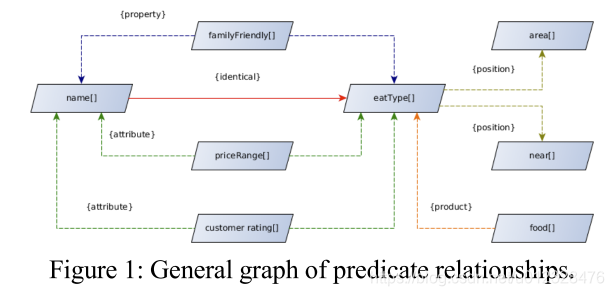
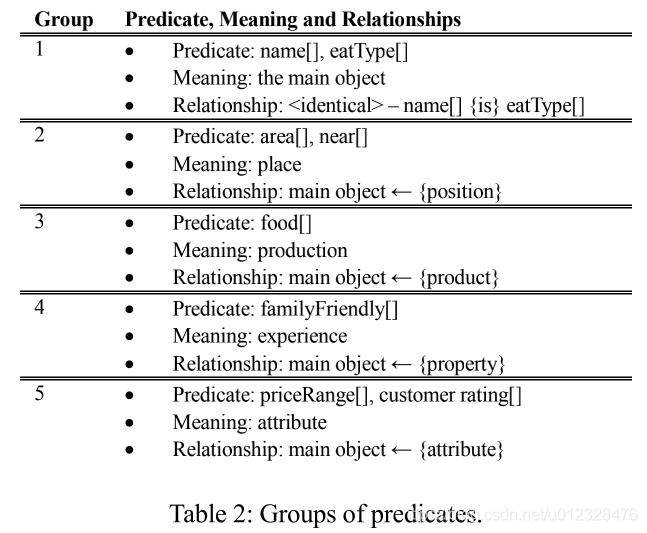
| type | Meaning | RelationShip |
|---|---|---|
| name,eatType | the main object | 主语(主体) |
| area,near | place | 对主语进行位置的描述 |
| food | production | 主语会生成什么 |
| experience | familyFriendly | 对主语的评价 |
| attribute | priceRange,customer rating | 主语的属性 |
其实这里面还是有一些困惑的,
- 为什么把
familyFriendly单独拉出来?是因为value类型是“yes”“no”? - 关于property和attribute,不太确定,找到一种比较合理的解释是,property是不可对比的属性,attribute是与其他个体或群体无关的“属性”,该属性只和本体有关。
有了这样的规则就可以将输入变成如下的structure

Data Source Collector
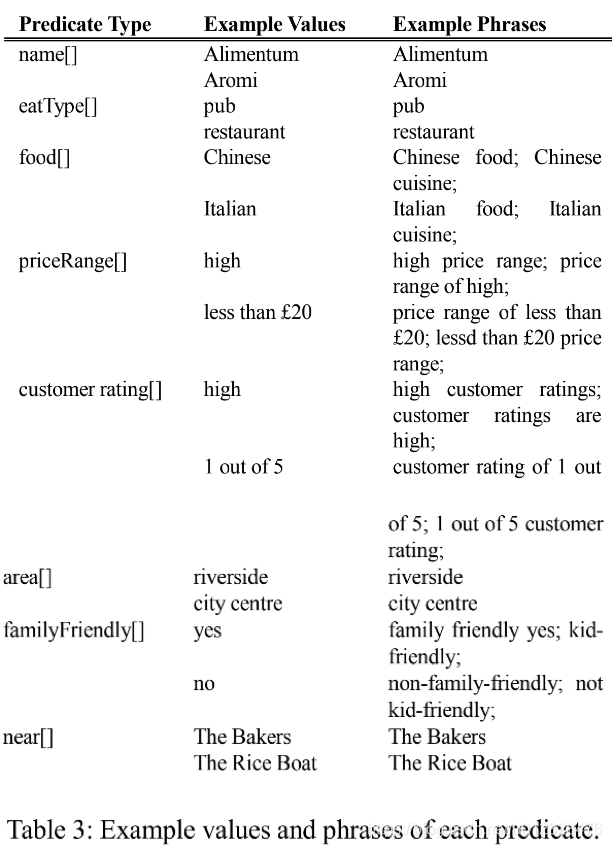
有了上面的空位,在填充时,作者还进行了同义词扩展,让最终生成的句子在表述上更加具有多样性。
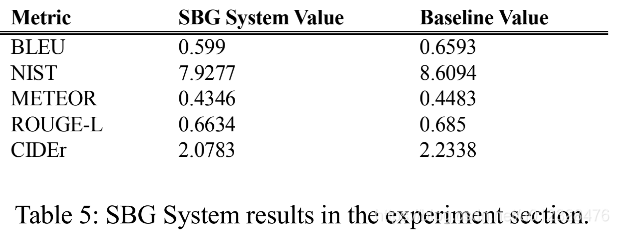
结果
自动评价的结果来看好像并没有baseline好:
这篇关于论文阅读-Structure-based Generation(SBG) System for E2E NLG Challenge的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









