本文主要是介绍终生学习(增量学习)概述,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
概念
终生学习(Life Long Learning,LLL),又称为Continuous Learning、Never Ending Learning、Incremental Learning,就是机器可以不断学习新知识,而不会忘记学过的知识。LLL需要解决三个问题:Knowledge Retention、Knowledge Transfer、Model Expansion。本文内容总结自李宏毅的PPT。
1.Knowledge Retention
问题提出
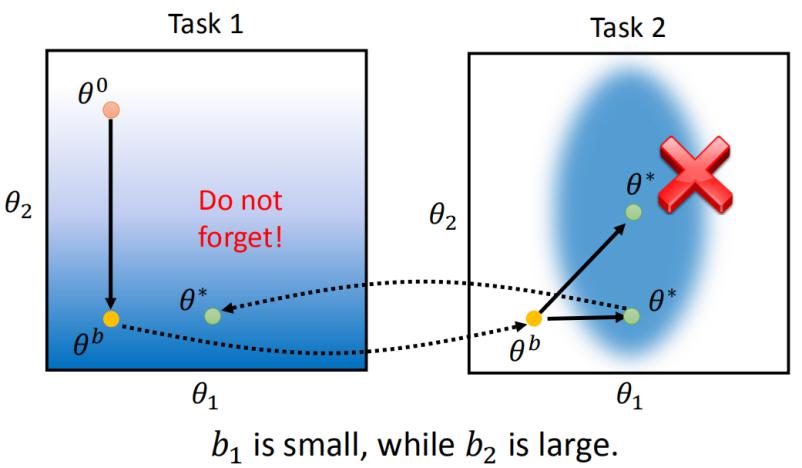
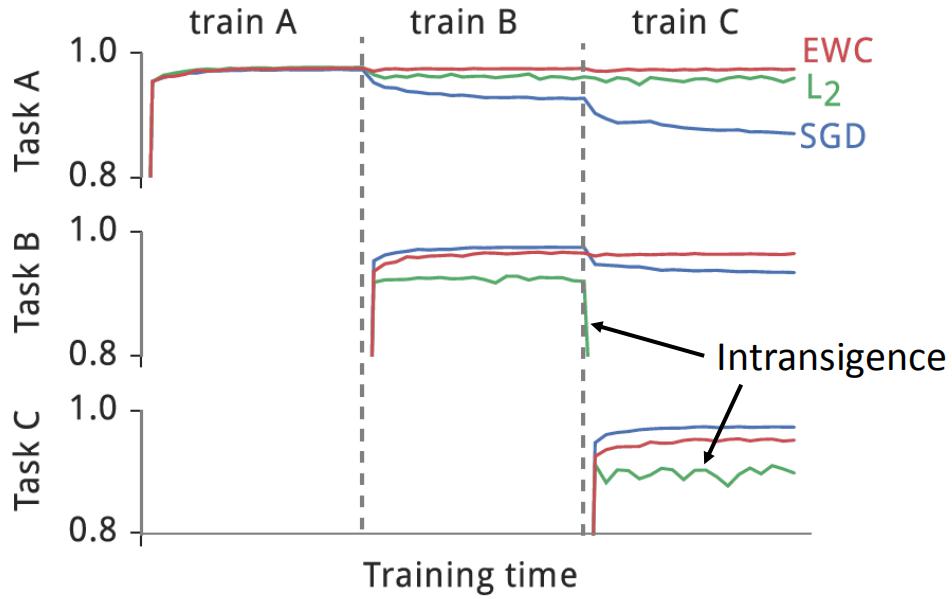
Knowledge Retention(but NOT Intransigence),知识保留。要让机器学会保存学过的知识,同时拥有学习新知识的能力。这里给出一个例子说明存在的问题。下面是两个识别手写数字识别的任务,任务1在手写数字中加入了噪声,如下图所示。
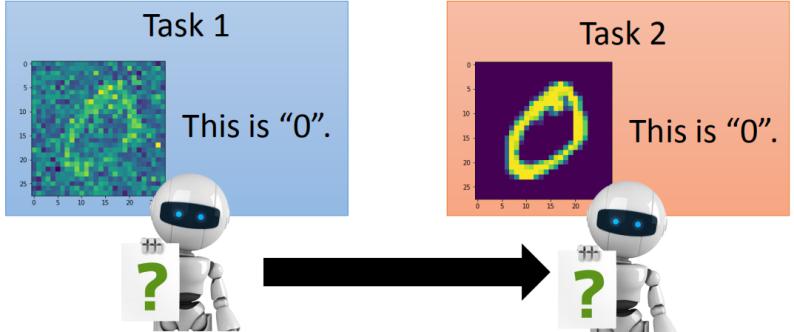
如果先学习任务1,因为任务1更难,那么可以直接迁移到任务2上,效果也不错,如下图左上角所示。如果先学习任务1,再学习任务2,那么机器就忘记任务1学过的东西了,如下图右上角所示。但是如果使用多任务学习的方法同时学习两个任务,就可以取得很好的效果。说明网络容量足以学习两个任务,但是却没有保留学过的知识。

多任务学习通常难以代替LLL,因为遇到新任务时,模型需要从头训练,这样无论是存储训练数据的代价还是训练代价都是难以接受的。另一方面,多任务学习可以作为LLL的上界。
为什么不每个任务训练一个模型?第一因为我们希望不同任务之间知识的融合可以提高性能,第二当模型很多的时候,难以保存训练的模型。
EWC
Elastic Weight Consolidation(EWC),前面的任务中学习的模型参数有些是重要的,而有些是可以被改变的,因此可以通过尽量保存前面任务中的重要参数来减小机器的“遗忘”问题。设 θb是前面任务中学习到的参数,每个 θb 拥有一个守卫(guard)参数b,守卫参数用于表明该参数有多重要。那么EWC下的损失函数公式如下:
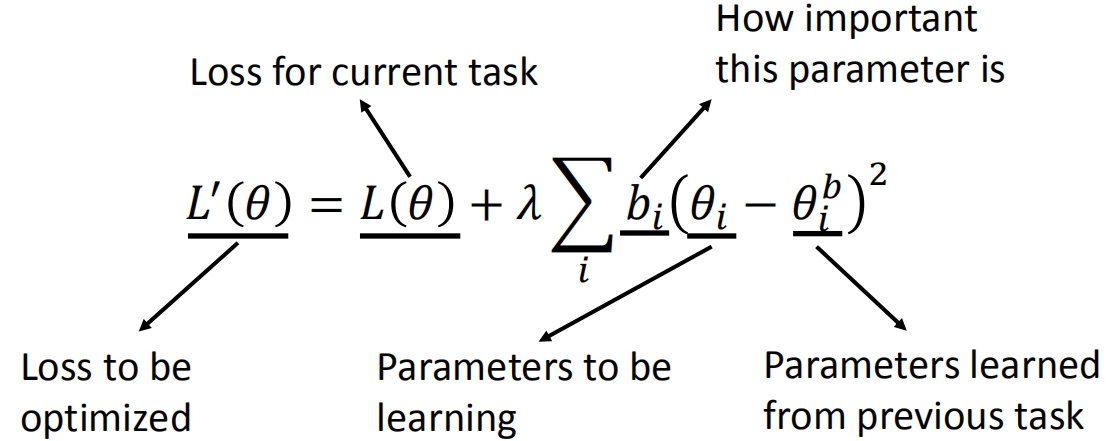
可以看到 总的损失=常规损失+参数相差。优化的目标是损失值尽可能小,只看上式的后一项,bi越大,则θi和θbi 就需要越接近,这样总的损失值才能变小。经过优化后,bi大的参数θi和θbi的值很接近,从而保留了前面任务学习到的知识。
从另一个角度看,上式的后一项可以看作一个正则化项。不同于L1或L2正则化,这里的目标是使得某些参数与之前训练好的参数尽可能相近。
下图表示模型学习任务1和任务2时某两个参数值的变化过程,在不加限制的情况下,学习任务2后,会忘记任务1学过的知识。
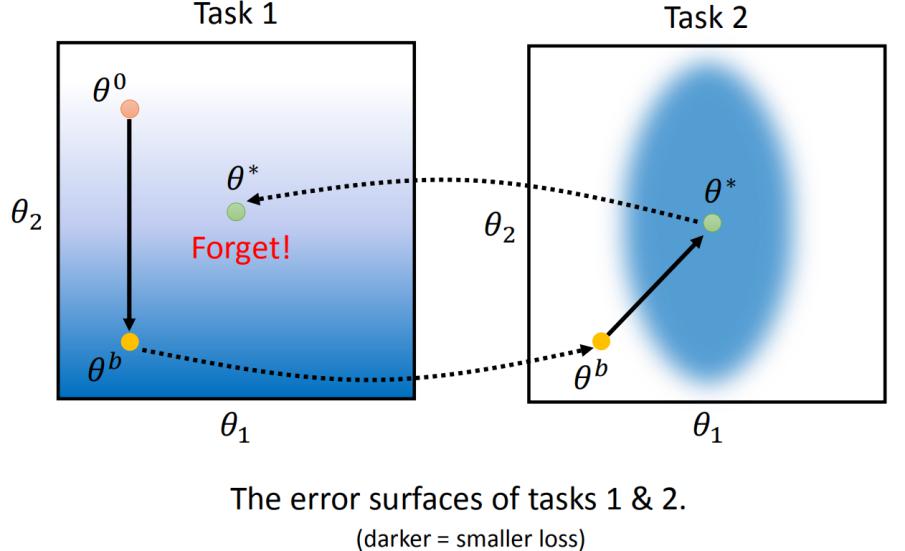
若想用EWC解决这个问题,主要的问题是如何确定守卫参数b的值。不同的参数有不同的做法,其中一个方法是根据要守卫的参数的二次导数来确定。优化后的整个模型应该处在一个局部最优值上面,就像在某个山谷里那样。从不同的参数上看这个局部最优值,它的函数曲线是不一样的。比如下图是某两个参数:
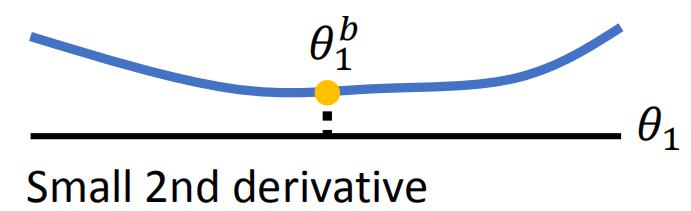

上图左的2阶导数较小,θ1参数改变影响也不大,因此b1的值小。而上图右2阶导数大,θ2改变影响较大,因此b2的值大。因此上面这个例子中学习到任务2后参数更好的选择如下:
下图是原始的EWC论文上给出的结果:
守卫参数估计的不同方法如下:
Elastic Weight Consolidation (EWC) http://www.citeulike.org/group/15400/article/14311063
Synaptic Intelligence (SI) https://arxiv.org/abs/1703.04200
Memory Aware Synapses (MAS) Special part: Do not need labelled data https://arxiv.org/abs/1711.09601
生成模型
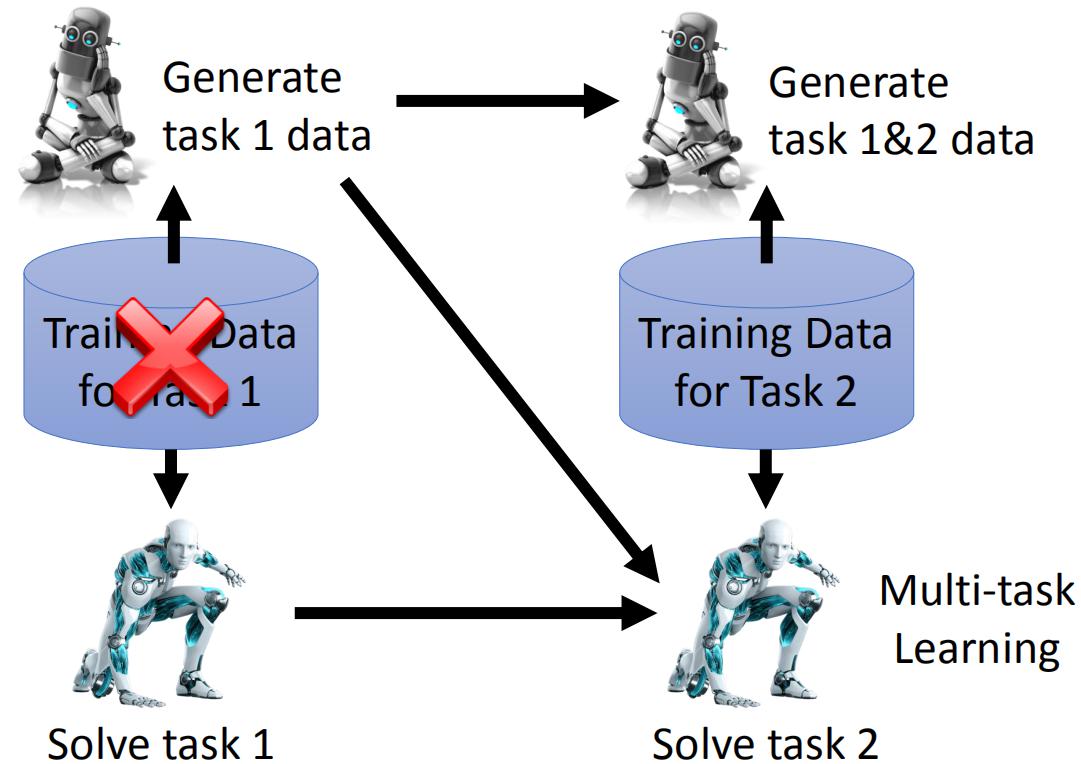
但是多任务学习作为LLL的上界,有人还是想用它来代替LLL,那么一个重要的问题是解决每个任务的数据集存储问题。其中生成模型是数据存储的解决方案之一。生成模型通过学习任务的数据集,可以生成相似的数据。不断的学习任务的数据,从而可以用一个生成模型代替每个任务的数据集。
相关论文如下:
https://arxiv.org/abs/1705.08690
https://arxiv.org/abs/1711.10563
网络结构的适应
有时候两个任务之间的网络结构不一定相同。比如前面的任务是分类15个类别,后面的任务是分类20个类别,那么两个任务需要的网络是不同的。这里由几个解决方案:
Learning without forgetting (LwF),https://arxiv.org/abs/1606.09282
iCaRL: Incremental Classifier and Representation Learning,https://arxiv.org/abs/1611.07725
2.Knowledge Transfer
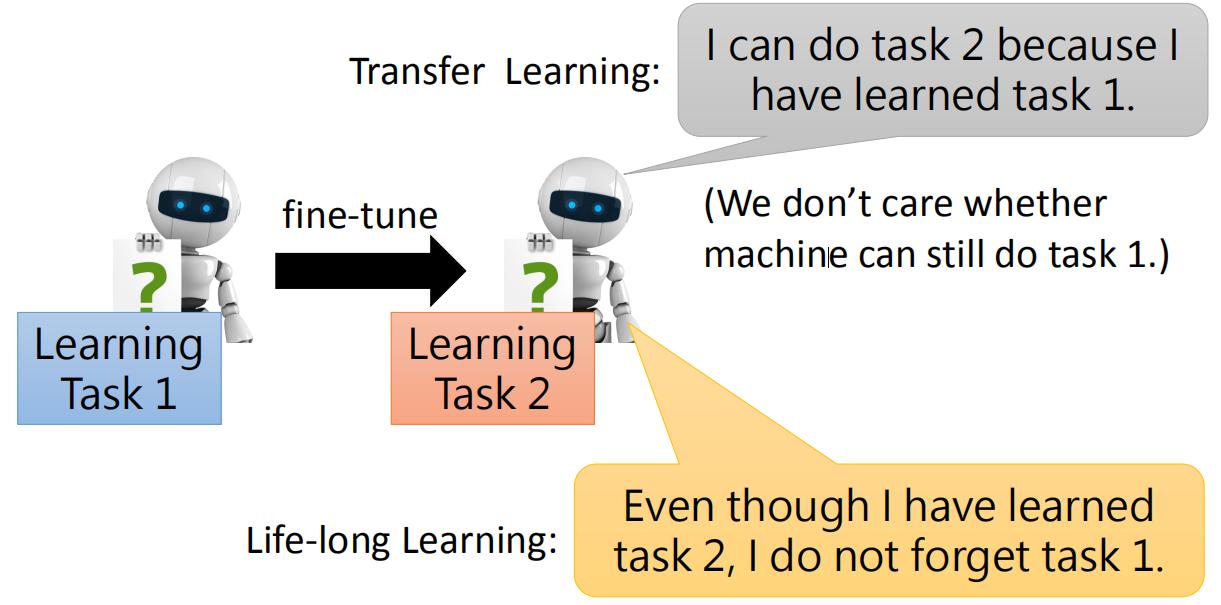
Knowledge Transfer,知识迁移。我们不仅希望机器可以记住过去的学习到的知识,还希望机器人以前学过的知识可以应用到后面的任务中,即知识迁移。这有点类似于迁移学习,不同的地方在于迁移学习不关心模型的遗忘问题,而LLL既需要将知识迁移同时要保证模型能保留学过的知识。
LLL的评估
一个常见的评估LLL的方法如下:画出下面的表格,横轴表示一个模型在不同任务上的表现,纵轴表示LLL模型学完第几个任务后的模型。
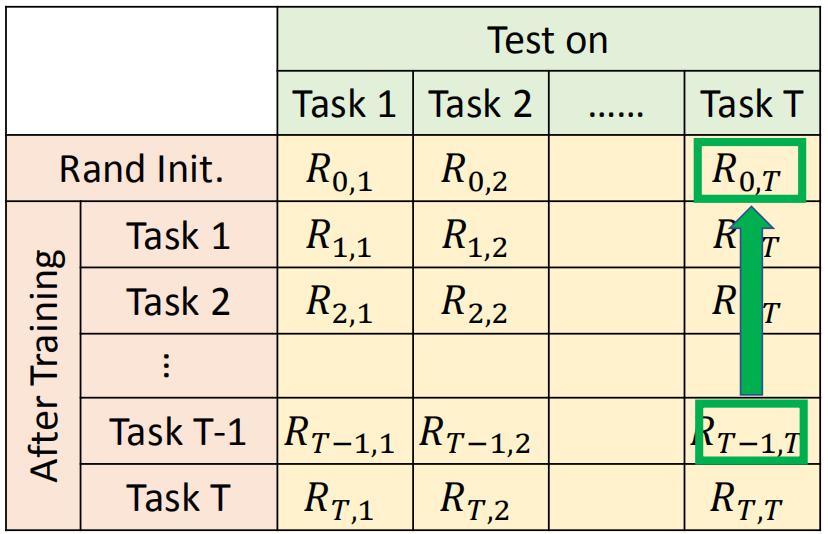
表格中的Ri,j表示训练了任务i之后,在任务j上的性能。若i>j,表示训练任务i后去评估前面学过的任务j。若i<j,表示任务i迁移到任务j的性能。下面是几个总体指标:
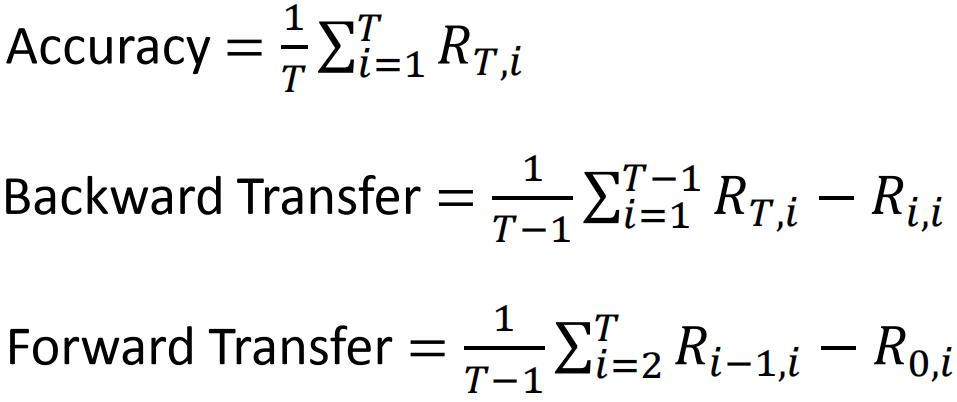
Accuracy表示在学完第T个任务后,LLL模型在所有任务上的平均指标。
Backward Transfer表示在学完第T个任务后,LLL模型对所有任务的指标与刚学完任务时的指标之差,来表示任务记住知识的能力。这个值通常是负的,我们通常希望这个值越大越好。
Backward Transfer表示在还没有学到某个任务T之前,模型根据别的任务,能够在任务T上获得多少性能。
GEM
Gradient Episodic Memory(GEM),可以约束梯度提高学过的任务的性能。就是对模型参数稍微修改一下提高性能,如下图所示:

如上图所示,θ是对当前任务优化之前的参数,虚线是当前任务优化该参数的方向,g1和g2是前面的任务优化该参数的方向,g是综合考虑后更新梯度的方向。这个方法需要保存前面任务的梯度数据。
相关论文:
GEM: https://arxiv.org/abs/1706.08840
A-GEM: https://arxiv.org/abs/1812.00420
对比
下面是各种方法实现的LLL的效果的对比:
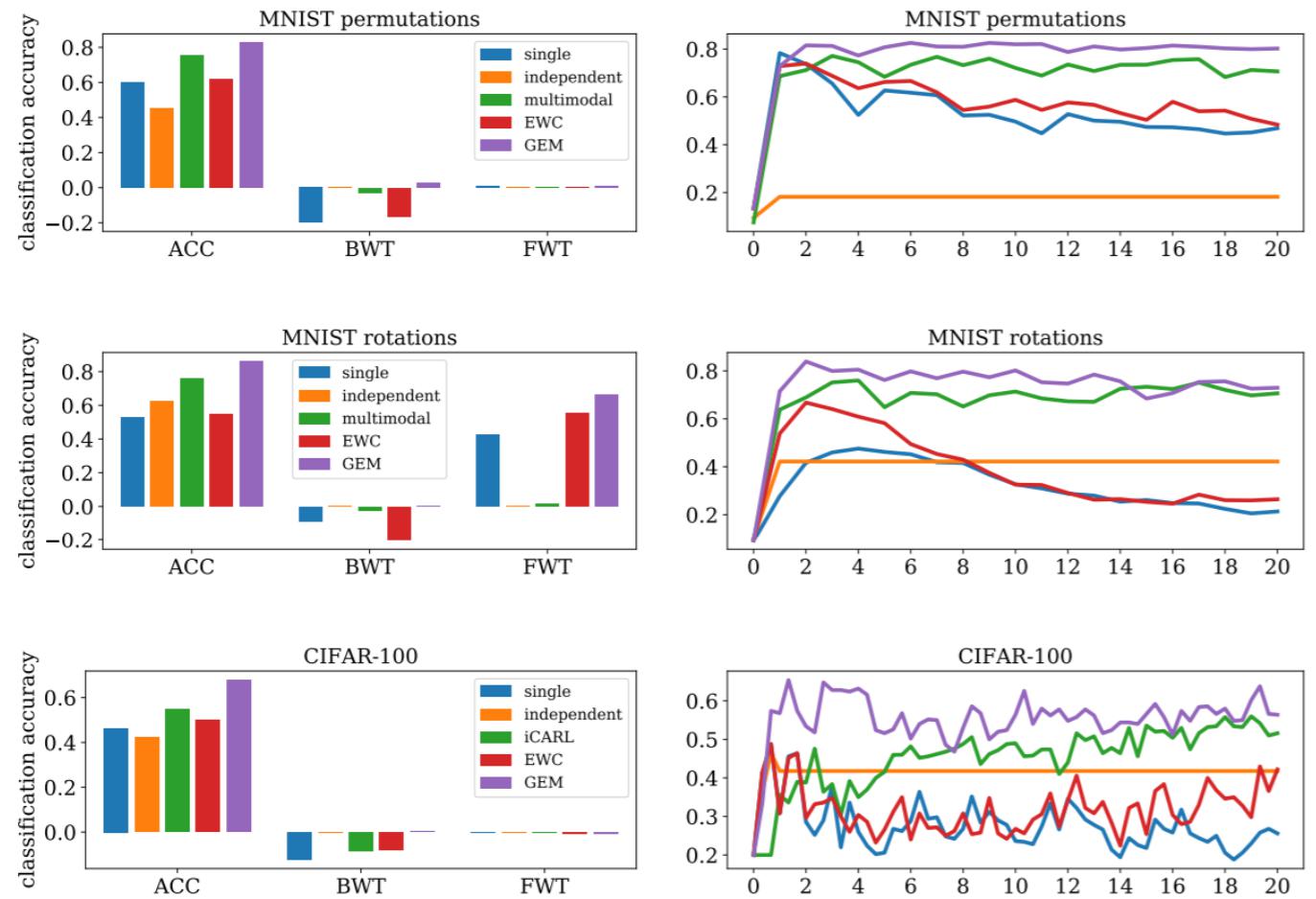
图顶部表示mnist数据集每次经过置换后得到的新数据集当成新的任务,图中间是旋转后,图下面是CIFAR-100。其中single表示单个模型学完各个任务,independent表示每个任务都独立训练一个模型,multimodal是多任务学习,还有EWC和GEM。
观察上图的结果,发现GEM的精度最高,其次是多任务学习。
3.Model Expansion
Model Expansion(but Parameter Efficiency),模型拓展。当任务太多的时候,模型的容量可能不够,因此这里要求模型能自动扩展容量。目前这个问题的研究仍处于早期阶段,其中几个解决方案如下。
(1)Progressive Neural Networks
论文:https://arxiv.org/abs/1606.04671
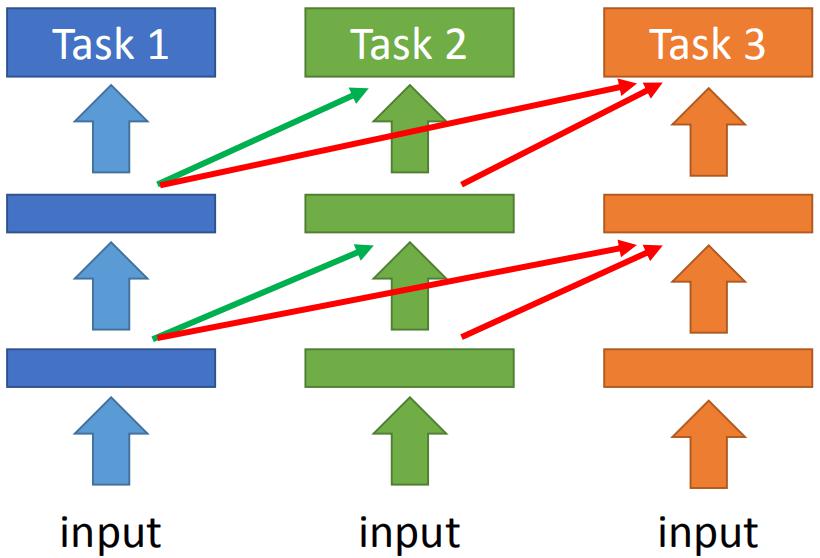
如上图左所示,首先构建一个网络训练任务1。到任务2的时候,重新构建一个网络训练任务2。这个任务2的网络接收任务1的网络的每层的输出作为输入,从而达到融合任务1的作用,如上图中间所示。而任务3网络接收任务1网络和任务2网络的输出,从而可以同时学习任务1 2 3。问题在于每个任务都构建一个网络,当任务很多的时候,参数过多从而导致无法训练。
(2)Expert Gate
论文:https://arxiv.org/abs/1611.06194
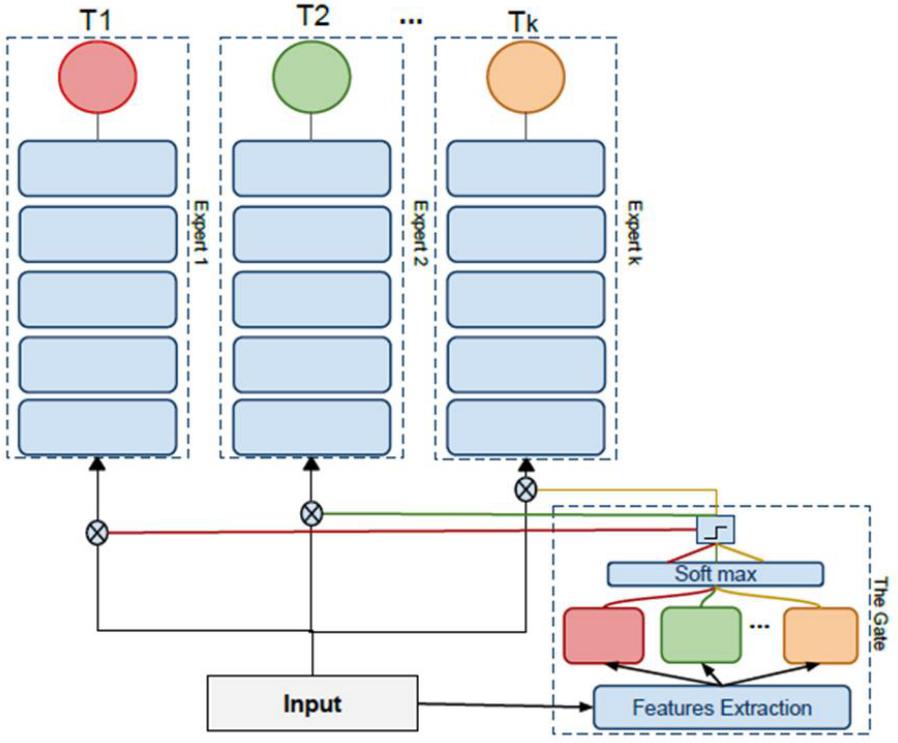
(3)Net2Net
论文:https://arxiv.org/abs/1511.05641 ,https://arxiv.org/abs/1811.07017
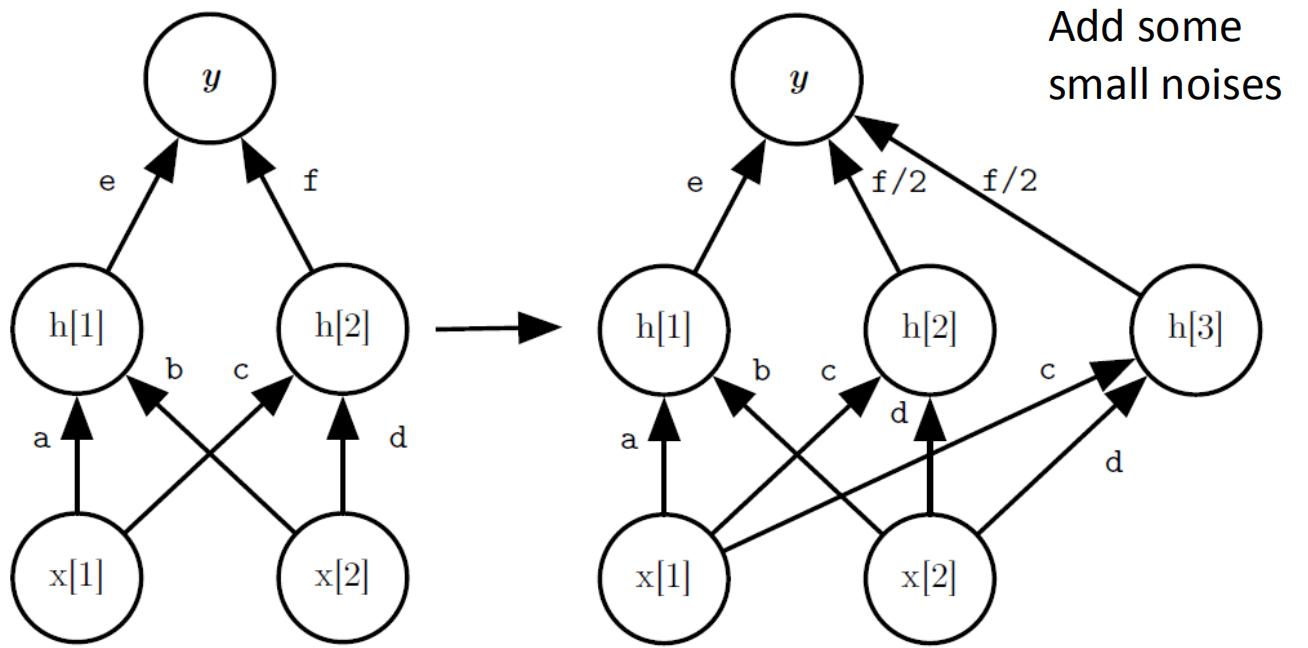
这个论文主要想解决的是网络容量不够时,如何加入新的神经元而不会导致网络忘记学过的知识。Net2Net的方法如上图所示,新加入的h|3|神经元输入权重与h|2|一致,输出权重是h|2|的一半。这样可以使得网络变宽,但是不会忘记学过的东西。存在的问题是h|2|和h|3|的权重完全一致,会导致更新的梯度也一致,因此需要在两个神经元的权重上加入很小的噪声,使得它们不完全一致。
其它问题
如下图所示,机器的遗忘程度也和任务学习的先后顺序有关。
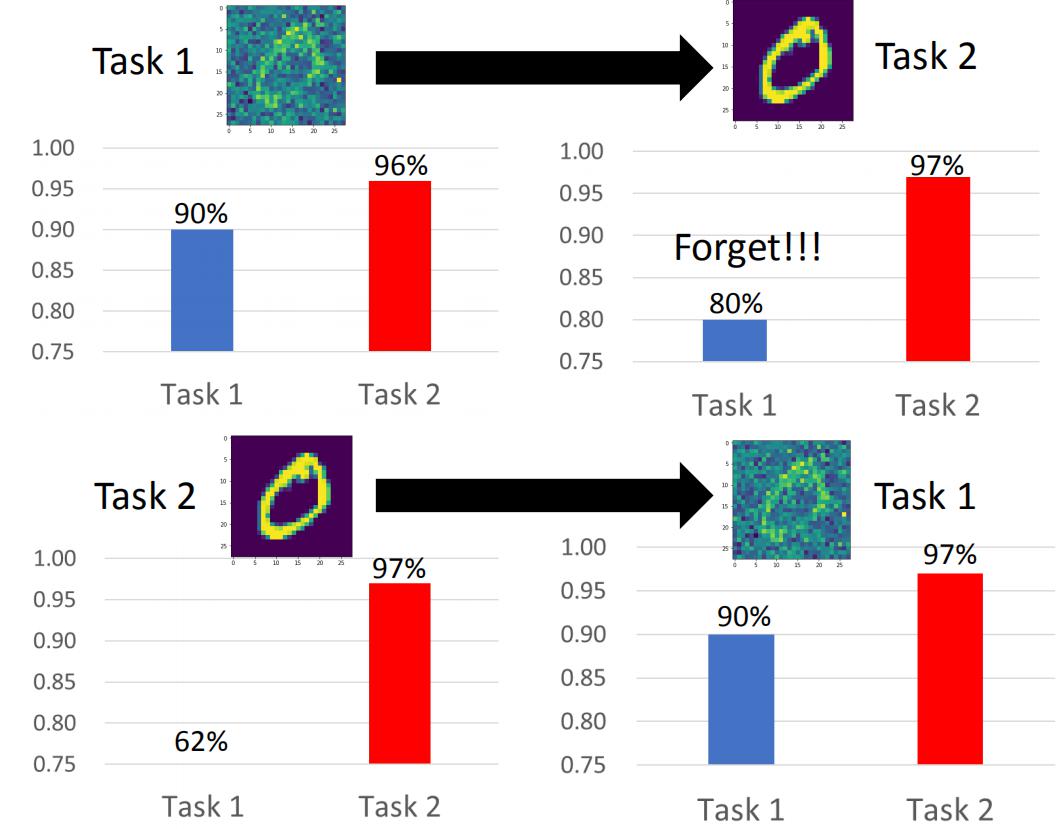
这篇关于终生学习(增量学习)概述的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








