本文主要是介绍森林的带度数层次序列存储,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
总时间限制:
1000ms
内存限制:
65536kB
描述
对于树和森林等非线性结构,我们往往需要将其序列化以便存储。有一种树的存储方式称为带度数的层次序列。我们可以通过层次遍历的方式将森林序列转化为多个带度数的层次序列。
例如对于以下森林:
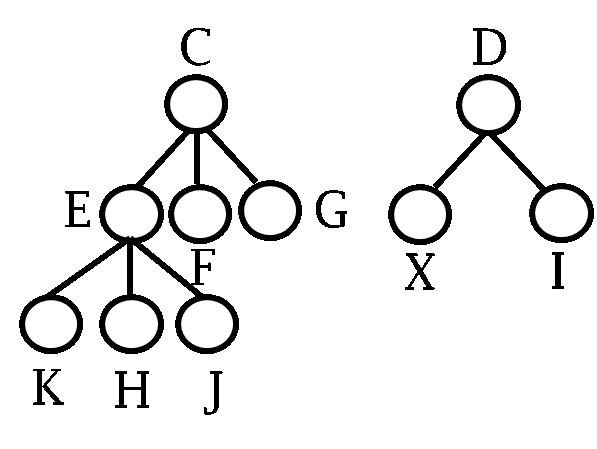
两棵树的层次遍历序列分别为:C E F G K H J / D X I
每个结点对应的度数为:3 3 0 0 0 0 0 / 2 0 0
我们将以上序列存储起来,就可以在以后的应用中恢复这个森林。在存储中,我们可以将第一棵树表示为C 3 E 3 F 0 G 0 K 0 H 0 J 0,第二棵树表示为D 2 X 0 I 0。
现在有一些通过带度数的层次遍历序列存储的森林数据,为了能够对这些数据进行进一步处理,首先需要恢复他们。
输入
输入数据的第一行包括一个正整数n,表示森林中非空的树的数目。
随后的 n 行,每行给出一棵树的带度数的层次序列。
树的节点名称为A-Z的单个大写字母。
输出
输出包括一行,输出对应森林的后根遍历序列。
样例输入
2
C 3 E 3 F 0 G 0 K 0 H 0 J 0
D 2 X 0 I 0
样例输出
K H J E F G C X I D
解决:注意是层次结构,应该采用队列帮助恢复。
为了得到节点在树中的真实地址,可以采用添加节点时返回具体位置的方法。
为一个节点增加子节点,如果子节点指针为空则直接增加,否则应该为子节点增加兄弟节点
为一个节点增加兄弟节点,如果兄弟节点指针为空则直接曾姐,否则应该为兄弟节点增加兄弟节点。
具体实现:
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include<memory.h>
#include<queue>
using namespace std;struct leaf {char ch;int n;leaf* child, * brother;leaf(){}leaf(char x,int num) {ch = x;n = num;child = brother = NULL;};leaf* add_brother(char x, int num) {if (!brother) {brother = new leaf(x, num);return brother;}else return brother->add_brother(x, num);}leaf* add_child(char x,int num) {if (!child) {child = new leaf(x, num);return child;}else return child->add_brother(x, num);}void read() {if(child)child->read();cout <<ch<< " ";if(brother)brother->read();}
};queue <leaf*> line;int main(){int n; cin >> n;while (n--) {while (!line.empty())line.pop();char q; int p;cin >> q >> p;leaf* tree = new leaf(q, p);int howMany = p;leaf* index = tree;while (!line.empty()||howMany) {if (!howMany) {index = line.front();howMany = index->n;line.pop();}//cout<<howMany<<" "<<line.size() << endl;cin >> q >> p;howMany--;if (p)line.push(index->add_child(q, p));else index->add_child(q, p);}tree->read();}
}这篇关于森林的带度数层次序列存储的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






