本文主要是介绍袋鼠云的FlinkSQL插件开发,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
袋鼠云是什么
袋鼠云是一家大数据产品供应商。他开发了一个产品叫做 flinkStreamSQL。这东西是以 Flink 为基础开发的使用 SQL 来写流式计算逻辑的产品。
FlinkStreamSQL 的开源地址
什么是插件
这里所说的插件是可以理解为自定义的语法。例如下面的 SQL:
select fact.shop_id,shop.shop_name
from fact_stream as fact
left join dim_shop as shop
on fact.shop_id = shop.shopid
dim_shop 可能是一个 redis 为实体的 Table ,这袋鼠已经为我们实现了,现在我们可能从 HTTP 的接口拿到数据,此时的话,我们可以自定义一个 HTTP Table ,然后上面的代码不用修改。
整体的流程
编写、执行 FlinkStreamSQL 的流程如下所示:
CREATE TABLE source(colName colType,...function(colNameX) AS aliasName,WATERMARK FOR colName AS withOffset( colName , delayTime ))WITH(type ='kafka09',kafka.bootstrap.servers ='ip:port,ip:port...',kafka.zookeeper.quorum ='ip:port,ip:port/zkparent',kafka.auto.offset.reset ='latest',kafka.topic ='topicName',parallelism ='parllNum',--timezone='America/Los_Angeles',timezone='Asia/Shanghai',sourcedatatype ='json' #可不设置);CREATE TABLE sink(colName colType,...function(colNameX) AS aliasName,WATERMARK FOR colName AS withOffset( colName , delayTime ))WITH(type ='kafka09',kafka.bootstrap.servers ='ip:port,ip:port...',kafka.zookeeper.quorum ='ip:port,ip:port/zkparent',kafka.auto.offset.reset ='latest',kafka.topic ='topicName',parallelism ='parllNum',--timezone='America/Los_Angeles',timezone='Asia/Shanghai',sourcedatatype ='json' #可不设置);CREATE TABLE dim (columnFamily:columnName type as alias,...PRIMARY KEY(keyInfo),PERIOD FOR SYSTEM_TIME)WITH(type ='hbase',zookeeperQuorum ='ip:port',zookeeperParent ='/hbase',tableName ='tableNamae',cache ='LRU',cacheSize ='10000',cacheTTLMs ='60000',parallelism ='1',partitionedJoin='false');insert into sink(
...
)
select source.*,dim.*
from source
left join dim
where
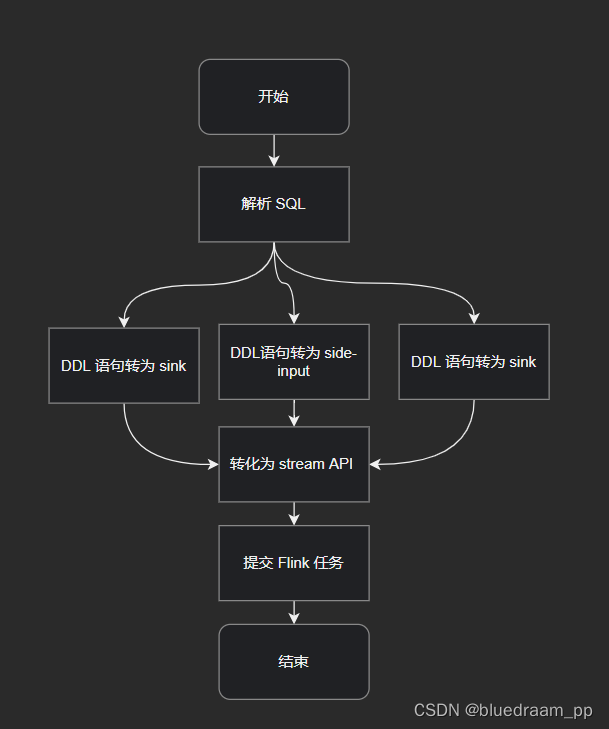
如上面画的,会将 DDL 变成 source、sink、side-put 的算子。简单的讲,执行的逻辑是
用 ; 为分割符号,分割开 sql 语句,然后使用正则表达式识别 DDL 语句、DML 语句。
其中 DDL 语句中符合(?i)^PERIOD\s+FOR\s+SYSTEM_TIME$ 则认为是 side-input ,side-input 会别解析为异步I/O
算子。如果 DDL 语句中没有则解析为 source 算子,如果 DDL 表在 DML 中在 insert into 后面,则为 sink 表。
知道了这些之后,我们可以自己定义一种 DDL 语句,如下:
CREATE TABLE dim (columnFamily:columnName type as alias,...PRIMARY KEY(keyInfo),PERIOD FOR SYSTEM_TIME)WITH(type ='http',url ='http://....',...);insert into sink(
...
)
select source.*,dim.*
from source
left join dim
where
其他的都不变,我现在的认为是实现一些接口,让 FlinkStreamSql 能通过 SQL 找到对应算子的实现。
关键的接口
DDL 语句解析的相关接口
AbstractTableInfo|--AbstractSideTableInfo|--AbstractTargetTableInfo|--AbstractSourceTableInfoAbstractTableParser|--AbstractSideTableParser|--ClickhouseSideParser|--AbstractSourceParser
袋鼠平台是如何找到对应的 AbstractSideTableInfo 的呢?其实靠 class 的命名规则,例如,hbase side table
AbstractSideTableInfo 的实现类是 HbaseSideParser。with 中的属性 type = hbase ,然后 table 的 DDL 中有 side table 的关键配置,然后所以贫出来的 class 文件文字是 HbaseSideParser ,namespace 是 com.dtstack.flink.sql.{类型}.{type}.table, 所以全程也出来了。
转化为算子的接口
BaseAsyncReqRow 此接口是继承了 RichAsyncFunction ,重要的方法有 handleAsyncInvoke 里面实现了异步调用外表接口的东西。
我实现的是的 Http side table ,使用的是 http 异步的请求接口:
<dependency><groupId>org.asynchttpclient</groupId><artifactId>async-http-client</artifactId><version>2.12.3</version>
</dependency>
使用的接口是:
AsyncHttpClient client = Dsl.asyncHttpClient();
BoundRequestBuilder builder = client.preparePost(url)
.setHeader("Content-type","application/json")
.setBody(json.getBytes());Request r = builder.build();
ListenableFuture whenResponse = client.executeRequest(build);
whenResponse.addListener(new Runnable(){public void run(){// 编写异步的回调函数}}
)
这篇关于袋鼠云的FlinkSQL插件开发的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








