本文主要是介绍51-2 一文讲通大模型的起源、核心技术、训练框架及典型应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本专题由深圳季连AIgraphX张博及团队出品,主要探讨大模型在自动驾驶领域的应用与实现。
1. 从机器学习到大模型
1956年,达特茅斯会议,“人工智能”(Artificial Intelligent,AI)概念被首次提出,人工智能作为一个学科开始被研究。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。它试图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。这个领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。
周志华在其著作《机器学习》一书中,将机器学习定义为一种让计算机从数据中学习并改进自身性能的技术。具体来说,机器学习利用大量的标注或未标注数据进行训练,以从中提取有用的信息和规律,然后利用这些信息和规律对未知的数据进行预测或分类。通过这种方式,机器能够逐渐适应各种新情况,并根据其已学习的知识进行推理和判断。
1.1 机器学习与传统程序
与传统的为解决特定任务、硬编码的软件程序不同,机器学习是用大量的数据来“训练”,通过各种算法从数据中学习如何完成任务。传统程序是人来梳理规则,机器学习程序是机器来学习数据,从数据中总结经验。
传统程序识别猫:输入信息(比如图片),让计算机判断是否有毛茸茸的毛?是,然后再判断是否有一堆三角形的耳朵?是,然后再判断......直到判断了具备猫所有的特征,结论才是猫。如果有一项不符合,那就不是猫。当然,也可以通过判断“不具备什么特征”来进行判断,比如“身上有黑白花纹吗?”没有。传统方式要制定判断某一类别或概念的全部所需规则,梳理全部的所需规则就很难,而单个规则也可能会涉及到一些困难的概念,比如对毛茸茸的定义。
机器自学程序识别猫:计算机提供大量猫的照片,随着各种猫的照片的增加,系统会不断学习更新,最终能准确地判断出哪些是猫,哪些不是。这里有三个基础概念:
- “机器学习”是“模拟、延伸和扩展人的智能”的一条路径,是人工智能程序的一个子集;
- “机器学习”要基于大量数据,也就是说它的“智能”是用大量数据训练出来的(“喂数据”),就像教小孩要一遍遍的看书学知识,教机器也是如此,要喂数据;
- 正是因为要处理海量数据,所以大数据技术尤为重要,而“机器学习”只是大数据技术上的一个应用。
虽然传统的机器学习算法在指纹识别、人脸检测等领域的应用基本达到了商业化要求,但“再进一步”却很艰难,直到深度学习算法的出现。
很多人分不清:模型、算法、程序这三个词的区别?
- 模型:将现实问题进行抽象化,抽象成数学公式。比如,人的收入和年龄、性别和学历的关系,最后抽象成一个数学公式:Y = F(A,S,E),可以先不用管这个公式具体表达是什么。
- 算法:算法,通俗的说就是“算”的方法,比如小学就开始学二元一次方程的解法,初中就开始学一元二次方程的解法。如何把“数学公式”表示的模型算出来,就是算法。
- 程序:算法可以人来算,也可以借助计算机来算,如果借助计算机来算,用计算机可理解的语言写出来“算法”,那就是程序。
1.2 深度学习
深度学习(Deep Learning,DL)是机器学习(Machine Learning,ML)领域中一个分支,它被引入机器学习使其更接近于最初的目标——人工智能AI。
- 模型复杂度:机器学习通常使用的是传统的线性模型或非线性模型,如决策树、支持向量机等,而深度学习则构建了多层神经网络,网络中的神经元之间存在大量的连接和权重,模型的复杂度更高。
- 数据量:机器学习通常需要大量的数据进行训练,而深度学习则更加注重数据的质量和多样性,通常需要更大的数据集才能获得更好的效果。这是因为深度学习模型复杂度高,需要更多的数据才能训练出精确的模型。
- 特征提取:机器学习通常需要人工提取数据中的特征,而深度学习则可以自动学习特征,减少了人工参与的过程。深度学习的自动特征学习功能是其重要的优点之一,它能够从原始数据中自动提取有用的特征,从而提高了模型的性能。
- 训练速度和计算资源:由于深度学习模型的复杂度更高,所以训练速度较慢,需要更多的计算资源,例如GPU等。机器学习的算法一般训练速度较快,而深度学习需要非常大的数据集和训练周期,并需要大量的计算资源进行训练。
以人脸识别为例子,感受一下机器学习和深度学习的不同。
机器学习程序: 首先确定想学习人脸的“面部特征”(眼睛、鼻子等等),然后根据输入的数据学习这些“面部特征”,最后依据这些“面部特征”来识别是不是人脸。
而深度学习程序是直接学习识别判断“是不是人脸”,并不需要我们告诉机器去学习哪些“面部特征”,是机器自动学习的。只需要将“数据”喂给机器,深度学习程序就自动学会了识别判断是不是人脸。对于“使用”来说,深度学习程序就是个黑箱,我们并不确定它学习到了什么,是“面部特征”还是“轮廓特点”,只是给它一张照片输入,它就实现了识别判断。深度学习算法专家深入研究算法的各层,分析出来机器是通过先学习细节特征、再组合成更宏观的特征,最后形成“人脸”的总体感知能力。基本是分为三步:
- 根据原始输入数据,确定出哪些边和角跟识别出人脸关系最大(细节特征);
- 根据上一步找出的很多小元素(边、角等)构建层级网络,找出它们之间的各种组合(局部特征),这时可以看到鼻子、眼睛、耳朵等;
- 在构建层级网络之后,对鼻子、眼睛等局部特征进行组合就可以组成各种各样的头像,就可以确定哪些组合可以识别人脸(整体特征)。
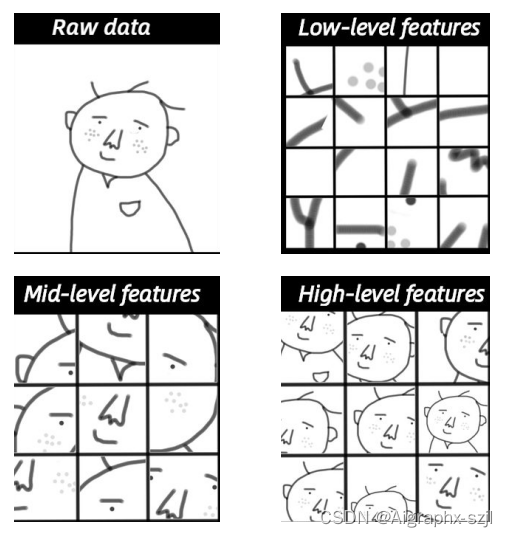
1.3 机器学习和深度学习
机器学习是一种实现人工智能的方法,深度学习是一种实现机器学习的技术。
具体不同大致有以下几点。
- 数据依赖程度不同。随着数据量的增加,二者的表现有很大区别。深度学习适合处理大数据,而数据量比较小的时候,用传统机器学习方法也许更合适。
- 硬件依赖程度不同。深度学习十分地依赖于硬件设施(提供计算的设施),因为计算量实在太大。它会涉及很多矩阵运算,因此很多深度学习都要求有GPU(专门为矩阵运算而设计的)参与运算。
- 特征工程。在训练一个机器学习模型的时候,需要首先确定学习哪些特征,比如识别人脸可能并不需要[人的身高]特征。在机器学习方法中,几乎所有特征都需要人为确认后,再进行手工特征编码。而深度学习试图自己从数据中自动学习特征。
- 解决问题的方式。(敲黑板,重点!)解决问题时,机器学习通常先把问题分成几块,一个个地解决好之后,再重新组合。深度学习是一次性地解决好问题。比如,任务是识别出图片上有哪些物体,并找出它们的位置。
- 机器学习的做法:第一步,发现是不是有物体(可动的),有三个;第二步,识别物体,分别是狗、自动车、汽车;第三步:识别物体对应位置,狗在哪里,自行车在哪里,小汽车在哪里。
- 深度学习的做法:直接一次完成任务,直接识别出来对应物体,同时还能标明对应物体名字、位置。

- 训练和推理运行时间。深度学习需要花大量时间来训练,因为有太多参数要去学习。但深度学习训练出的模型优势就在于,在推理服务上运行非常快。也是刚刚提到的实时物体检测。机器学习一般几秒钟或者最多几小时就可以训练好,推理运行也比较快。
1.4 什么是大模型
前面讲到了“模型”是现实化的一种抽象,抽象成数学公式。即使深度学习的出发点是更深层次的神经网络,但细分起来也会有非常多的不同的模型(也就是不同的抽象问题的方式),对应不同的数学公式,比如常见的CNN、DNN等。
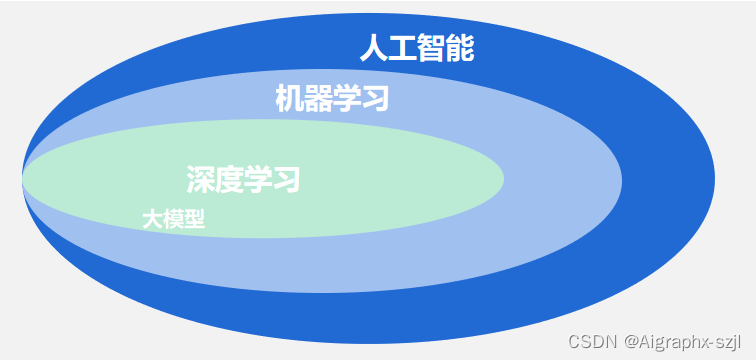
大模型是大规模语言模型(Large Language Model,LLM)的简称,简而言之就是指参数规模超过千万的深度学习模型。
2021年8月份,李飞飞和100多位学者联名发表一份200多页的研究报告《On the Opportunities and Risk of Foundation Models》,详细描述了当前大规模预训练模型面临的机遇和挑战。在文章中,大模型被统一命名为Foundation Models,可以翻译为基础模型或者是基石模型。
总之,4者之间的关系如下图所示:
大模型的特点主要表现在以下方面:
1. 大规模数据集:大模型需要处理大量的数据才能学到广泛的知识和模式,因此需要使用大规模的数据集。同时,数据集的多样性也能够帮助模型学习到更广泛的知识。
2. 多任务学习:大模型可以同时处理多个任务,这样可以让模型学习到更广泛的知识和技能。例如,语言模型可以学习到词义、语法、语义等多个方面的知识。
3. 模型架构和技术:大模型可以采用不同的模型架构和技术来优化模型的精度和效率。例如,Transformer模型可以用于处理自然语言处理任务,而卷积神经网络可以用于处理图像识别任务。
4. 模型优化:大模型需要进行参数优化,以提高模型的精度和效率。例如,可以使用梯度下降等优化算法来训练模型,同时也可以使用正则化等技术来防止过拟合。
5. 巨大的规模:大模型包含数十亿个参数,模型大小可以达到数百GB甚至更大。巨大的模型规模使它们拥有强大的表达能力和学习能力。
总之,大模型在处理大规模数据集、多任务学习和模型架构优化等方面具有显著的优势。
2. 大模型Foundation Model
2.1 涌现与同质化
在往下看之前,想抛出几个问题,希望引起大家的一个思考:
- 为什么预训练网络模型变得越来越重要?
- 预训练大模型的未来的发展趋势,仍然是以模型参数量继续增大吗?
- 如何设计、预训练一个成千上万亿级规模的大模型?
李飞飞等提出的《On the Opportunities and Risks of Foundation Models》 论文,充分肯定了Foundation Models对智能体基本认知能力的推动作用,同时也指出大模型呈现出「涌现」与「同质化」的特性。
- 「涌现」代表一个系统的行为是隐性推动的,而不是显式构建的;大模型涌现是指当AI模型的规模达到一定程度时,模型性能会显著提升,展现出让人惊讶、意想不到的能力,如语言理解能力、生成能力、逻辑推理能力等。这种现象通常出现在模型有大量参数的情况下,例如100亿到1000亿参数区间。
- 「同质化」是指基础模型的能力是智能的中心与核心,大模型的任何一点改进会迅速覆盖整个社区,但其缺陷也会被所有下游模型所继承。
回到大模型,2017年Transformer结构的提出,使得深度学习模型参数突破了1亿。到了BERT网络模型的提出,使得参数量首次超过3亿规模,GPT-3模型超过百亿,近两年国内的大模型也蓬勃发展,已经出来多个参数超过千亿、万亿的大模型。


可以看到,数据上面,每一代均相比前一代有了数量级的飞跃,无论是语料的覆盖范围、丰富度上都是绝对规模的增长。可以预测到,下一代万亿模型,使用的数据如果相比GPT-3在质量、来源和规模上没有量级的变化,很难有质的提升。大模型在产学各界掀起一阵阵巨浪,背后彰显的除了分布式并行和对AI算法的掌控能力,还是一次大公司通过AI工程的创举,利用大规模AI集群来进行掰手腕的故事。
随着网络模型越来越大,单机单卡、一机多卡、甚至多机多卡的小规模集群,只要网络模型参数量一旦超过十亿以上的规模,就很难用现有的资源训练了。于是有的研究者就会提出质疑:
- 一味的让模型变大、让参数量爆炸式增长,真的能让AI模型学习变得更好吗?
- 真的能带来真正的智能吗?
- 甚至有的同学还会挑战,小学数学题都解不好?
- 生成的文字内容不合逻辑?
- 给出的医疗建议不靠谱!
这里值得澄清的一点是,目前类似于GPT-3这样的大模型,在零样本和小样本的学习能力,主要来源于预训练阶段对海量语料的大量记忆,其次是语义编码能力、远距离依赖关系建模能力和文本生成能力的强化,以及自然语言进行任务描述等设计。而在训练目标方面,并没有显式的引导模型去学习小样本泛化能力,因此在一些小众的语料、逻辑理解、数学求解等语言任务上出现翻车的现象也是能理解的。
虽然大模型刚提出的时候,质疑的声音会有,但不可否认的是,大模型做到了早期预训练模型做不到、做不好的事情,就好像自然语言处理中的文字生成、文本理解、自动问答等下游任务,不仅生成的文本更加流畅,甚至内容的诉实性也有了显著的改善。当然,大模型最终能否走向通用人工智能仍是一个未知数,只是,大模型真的是有希望带领下一个很重要的人工智能赛道。
2.2 大模型作用
虽然深度学习使得很多通用领域的精度和准确率得到很大的提升,但是AI模型目前存在很多挑战,最首要的问题是模型的通用性不高,也就是A模型往往专用于特定A领域,应用到领域B时效果并不好。

2.2.1 大模型提供预训练方案
目前AI面对行业、业务场景很多,人工智能需求正呈现出碎片化、多样化的特点。从开发、调参、优化、迭代到应用,AI模型研发成本极高,且难以满足市场定制化需求,所以网上有的人会说现阶段的AI模型研发处于手工作坊式。基本上一个公司想要用AI赋能自身的业务,多多少少也得招聘懂AI的研发人员。
为了解决手工作坊式走向工场模式,大模型提供了一种可行方案,也就是“预训练大模型+下游任务微调”的方式。大规模预训练可以有效地从大量标记和未标记的数据中捕获知识,通过将知识存储到大量的参数中并对特定任务进行微调,极大地扩展了模型的泛化能力。例如,在NLP领域,预训练大模型共享了预训任务和部分下游任务的参数,在一定程度上解决了通用性的难题,可以被应用于翻译,问答,文本生成等自然语言任务。
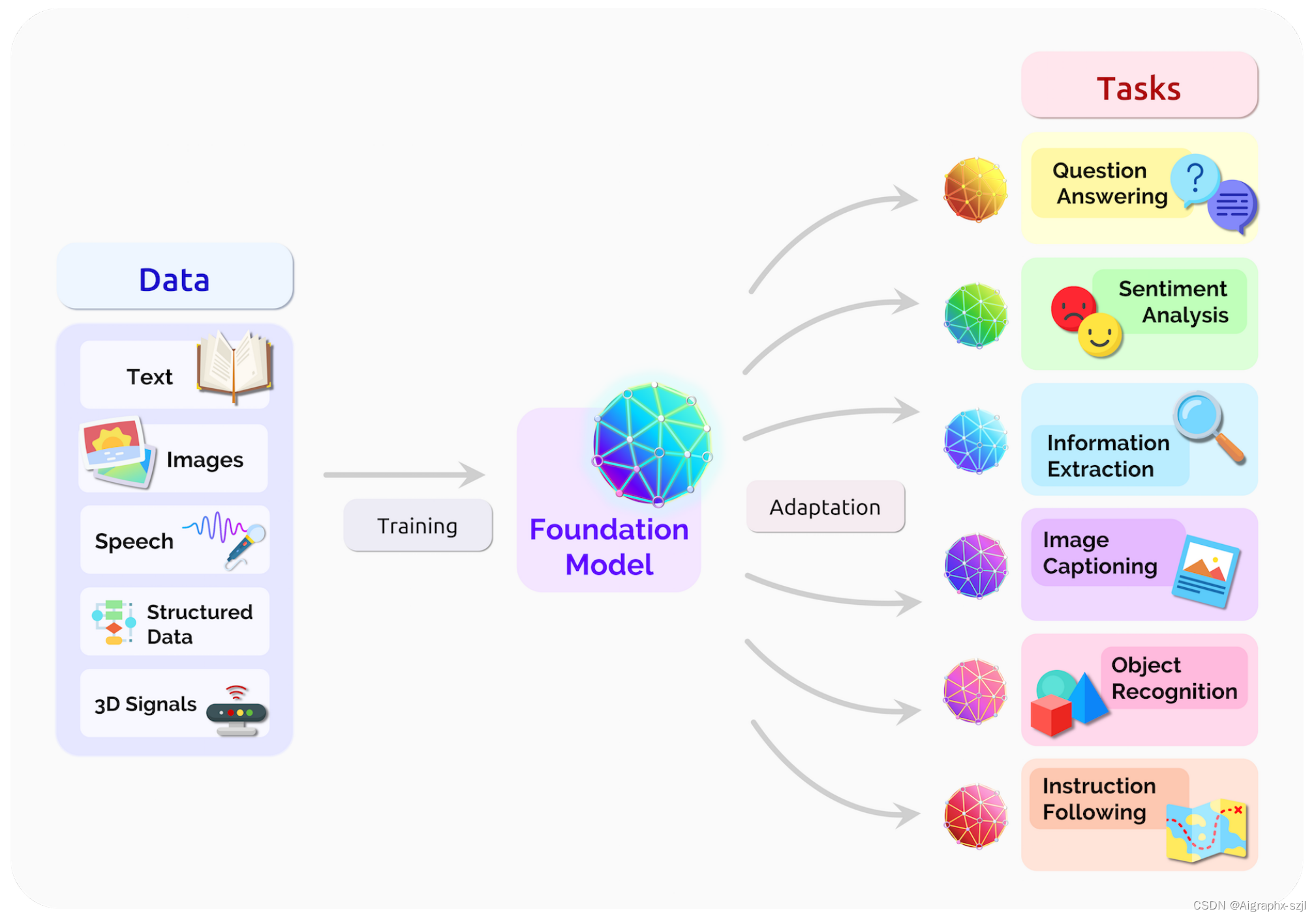
大模型可以集中来自各种模态的所有数据的信息,然后该模型可以适应各种下游任务。
继GPT-3问世仅仅不到一年的时间,Google重磅推出Switch Transformer,直接将参数量从GPT-3的1750亿拉高到1.6万亿,并比之前最大的、由google开发的语言模型T5-XXL足足快了4倍。
在惊人的数据量和可怕的网络模型参数下,Switch Transformer 模型在多项推理和知识任务中带来了显著性能提升。这说明该超大模型架构不只对预训练有用,还可以通过微调将质量改进迁移至下游任务中。
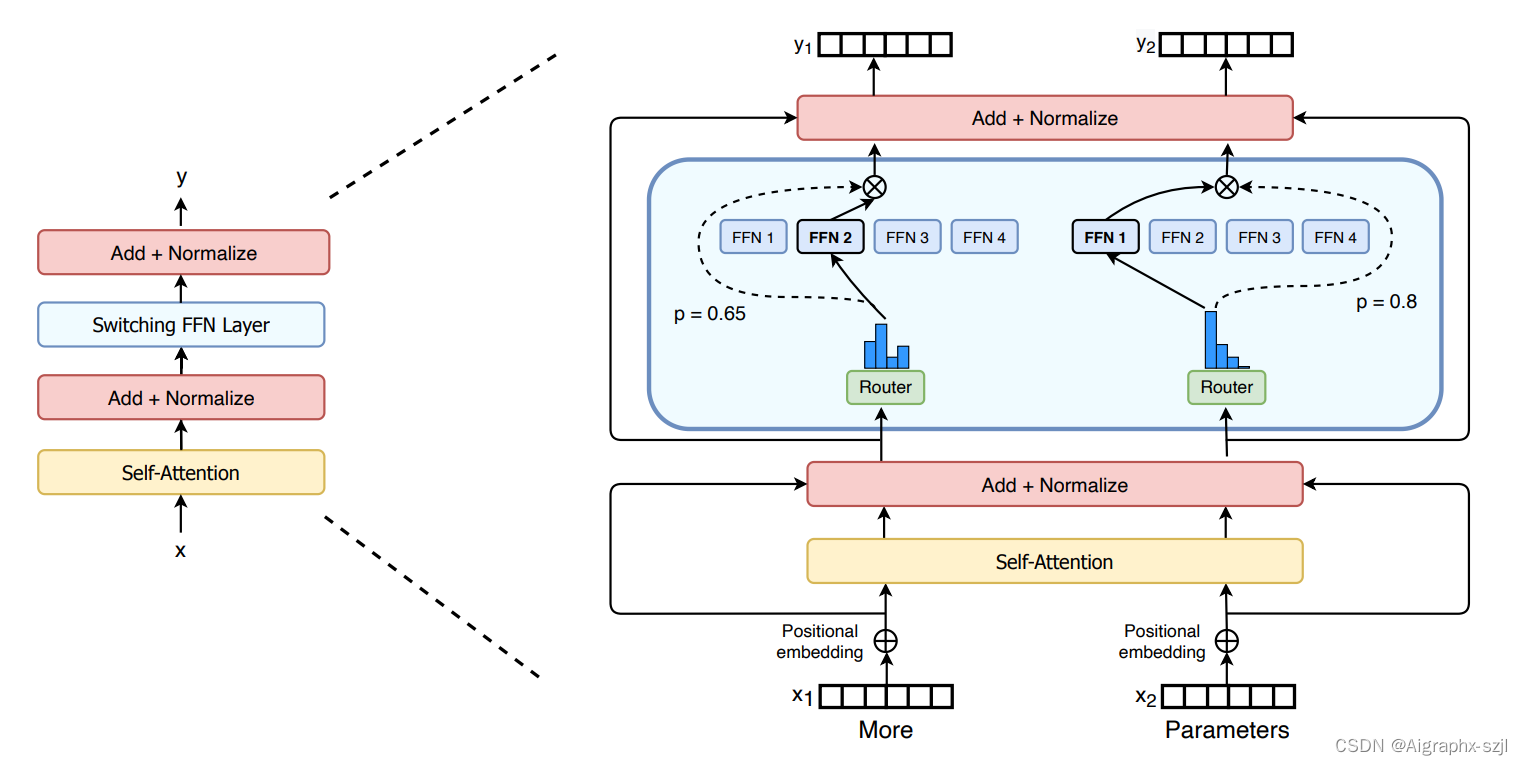
Google Switch Transformer网络架构
2.2.2 大模型具备自监督学习功能,降低训练研发成本
大模型的自监督学习方法,可以减少数据标注,在一定程度上解决了人工标注成本高、周期长、准确度不高的问题。由于减少了数据标准的成本,使得小样本的学习也能达到比以前更好的能力,并且模型参数规模越大,优势越明显,避免开发人员再进行大规模的训练,使用小样本就可以训练自己所需模型,极大降低开发使用成本。
2018年Bert首次提出,便一举击败 11 个 NLP 任务的 State-of-the-art 结果,成为了 NLP 界新的里程碑,同时为模型训练和NLP领域打开了新的思路:在未标注的数据上深入挖掘,可以极大地改善各种任务的效果。要知道,数据标注依赖于昂贵的人工成本,而在互联网和移动互联网时代,大量的未标注数据却很容易获得。
2.2.3 大模型有望进一步突破现有模型结构的精度局限
第三点,从深度学习发展前10年的历程来看,模型精度提升,主要依赖网络在结构上的变革。例如,从AlexNet到ResNet50,再到NAS搜索出来的EfficientNet,ImageNet Top-1 精度从58提升到了84。但是,随着神经网络结构设计技术,逐渐成熟并趋于收敛,想要通过优化神经网络结构从而打破精度局限非常困难。近年来,随着数据规模和模型规模的不断增大,模型精度也得到了进一步提升,研究实验表明,模型和数据规模的增大确实能突破现有精度的一个局限。
以谷歌2021年发布的视觉迁移模型Big Transfer,BiT为例。扩大数据规模也能带来精度提升,例如使用ILSVRC-2012(128 万张图片,1000 个类别)和JFT-300M(3亿张图片,18291个类别)两个数据集来训练ResNet50,精度分别是77%和79%。另外使用 JFT-300M训练ResNet152x4,精度可以上升到87.5%,相比ILSVRC-2012+ResNet50结构提升了10.5%。

虽然目前为止,大模型主要是以NLP为主,因为NLP抛弃了RNN序列依赖的问题,采用了Attention is All you need的Transformer结构,使得NLP能够演变出更多大模型。但是在最新的研究当做,图像领域也不甘示弱,CNN大模型也开始陆续涌现。例如ResNeXt WSL拥有8亿参数、GPipe拥有6亿参数规模,Google也通过EfficientNet-L2发布了4.8亿参数规模的网络模型,并且在JFT-300M数据集刷新了ImageNet的榜单,Top-1 Acc首次突破90。要知道在2020年,也就是1年前,大部分CNN网络模型规模都没有超过1亿,Top-1 Acc最高在87-89之间。

2.3 大模型应用场景
大模型在生物医疗、教育、法律援助等方面有广阔的应用前景,当前在自动驾驶、零售等方面有很多实际应用。特斯拉将Transformer引入自动驾驶系统,来实现AI模型效果的大幅优化。通过Transformer实时建模能力,对多模态融合感知数据进行感知融合,搭建具有时序特征的立体场景,提供了端到端大模型自动驾驶的解决方案。
下面从大模型的能力层面来探讨其潜在的应用场景。
2.3.1 视觉Vision
通过在规模上利用自我监督,视觉基础模型有可能将原始的、多模态的感官信息提取到视觉知识中,这可能有效地支持传统的感知任务,并可能在时间和常识推理等具有挑战性的高阶技能方面取得新的进展。这些输入可以来自不同的数据源和应用领域,这表明在医疗保健和具体的交互式感知环境中的应用前景广阔。

2.3.2 机器人Robotics
构建新型机器人基础模型将需要跨越不同环境和行为的大量数据集,模拟、机器人交互、人类视频和自然语言描述都可能是这些模型的有用数据源。尽管在获取数据方面存在挑战,但开发新的机器人基础模型对于任务规范和机器人学习中的各种问题公式具有巨大的潜力。

2.3.3 推理和搜索Reasoning and search
多模态可以让基础模型不仅用形式符号语言推理,还可以利用问题的视觉方面,如等价性、对称性和欧几里得几何,来修剪无限的搜索空间,并找到有前景的解决方案,模仿人类推理几何问题的方式。
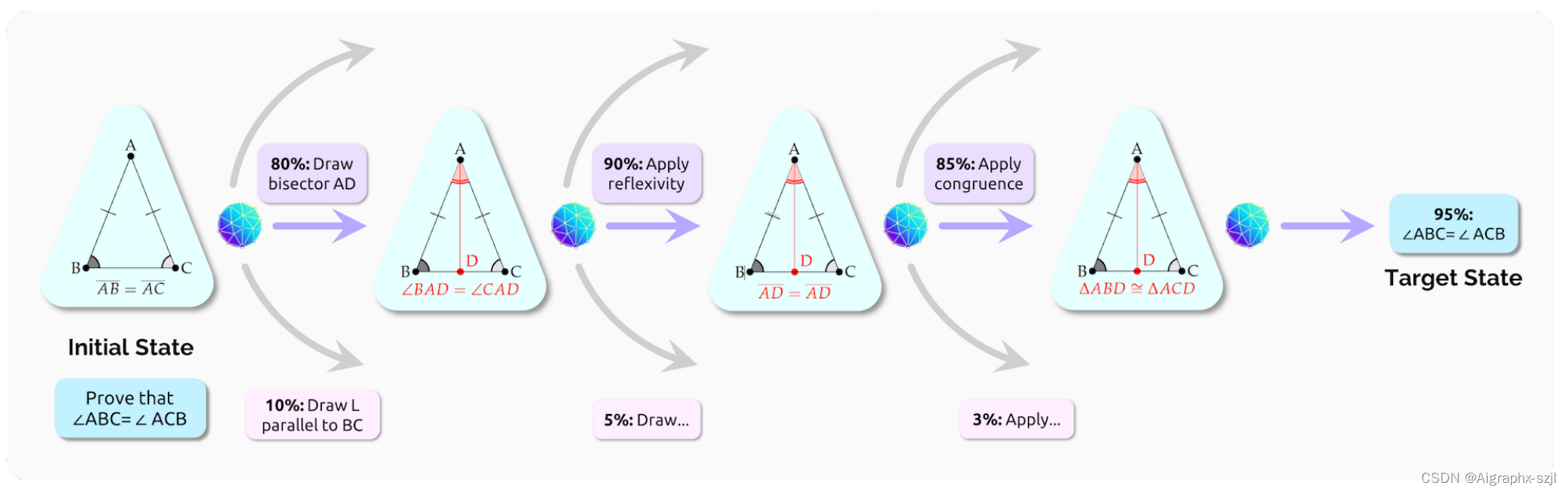
2.3.4 交互Interaction
基础模型将通过降低构建人工智能应用程序的难度阈值,为开发人员带来重大机遇,并通过提高可实现的交互类型的上限,为应用程序用户带来重大机遇。在某些情况下,开发者和用户之间的界限将开始模糊,用户可能能够轻松地开发自己的人工智能应用程序,例如使用自然语言。
2.4 大模型核心技术
大模型核心技术比较多,主要经历了从Transformer,RL之PPO算法、RLHF到GPT4、instructGPT的变迁。李飞飞等把大模型涉及的技术归纳为以下11方面。

考虑到非一蹴而就,而是经历了各个前置技术的发展、迭代、结合而成,故逐一阐述:
- 2017年之前早已有之的⼀些数学/AI/RL等基础技术,譬如微积分、概率统计、最优化、策略梯度、TRPO算法(2015年提出);
- 2017年6⽉OpenAI联合DeepMind首次正式提出的:Deep Reinforcement Learning from Human Preferences,即基于人类偏好的深度强化学习 ,简称RLHF;
- 2017年7月的OpenAI团队提出的对TRPO算法的改进:PPO算法;
- 2017年6月的Transformer/Self-Attention;
- 2018年6月的GPT(Generative Pre-trained Transformer),其关键构成是基于Transformer-Decoder的Masked Self-Attention;
- 2019年2月的融合prompt learning的GPT2,Prompt learning的意义在于不用微调也能做任务;
- 2020年5月的GPT3,参数规模到了1750亿,终于真正做到预训练之后不用再微调模式,通过In-context learning(简称ICL)开启Prompt新范式,且你可能没想到的是,这一年的9月份OpenAI已经开始研究GPT3与RLHF的结合了,且此时用的策略优化方法为PPO;
- 2021年7月的Codex,通过对GPT3进行大量的代码训练迭代而出Codex,从而具备代码/推理能力;
- 2021年9⽉Google提出的FLAN大模型:基于指令微调技术Instruction Fine-Tuning (IFT);
- 此前, Google 曾在21年5月对外宣布内部正在研发对话模型 LaMDA ,而 FLAN is the instruction-tuned version of LaMDA-PT;
- 2019年10月, Google 发布T5模型 (transfer text to text transformer) ,虽也基于 transformer ,但区别于BERT的编码器架构与GPT的解码器架构, T5是transformer 的 encoder-decoder 架构;
- 2022年1月, Google 发布LaMDA 论文『 LaMDA: Language Models for Dialog Applications』;
- 2022 年4月, Google 提出PaLM: Scaling Language Modeling with Pathways , 5400亿参数
- 2022年10月, Google 提出Flan-T5;
- 23年3月6日, Google 提出多模态LLM模型PaLM-E;
- 2022年1月的Google研究者提出的思维链技术(Chain of Thought,简称CoT);
- 2022年3月的OpenAI正式发布instructGPT:GPT3 + instruction tuning + RLHF + PPO,其中,instruction tuning和prompt learning的核心区别在于instruction tuning会提供更多的指令引导模型输出更符合预期的结果,例如
- 提示学习:给女朋友买了这个项链,她很喜欢,这个项链太____了;
- 指令微调:判断这句话的情感:给⼥朋友买了这个项链,她很喜欢。选项:A=好;B=⼀般;C=差;
- 你也可以暂简单理解instruction tuning为带⼈类指令的prompting。
- 2021年第4季度逐步发展而来的GPT3.5,并于22年不断融合Codex、InstructGPT的技术能⼒
- 2022年11月的ChatGPT:语⾔模型层⾯的核⼼架构是GPT3.5(基于Transformer-Decoder的Masked Self-Attention且融合了Codex的代码/推理能⼒、instruction tuning等技术) + RLHF + PPO3;
- 2023年3月中旬,OpenAI正式对外发布GPT-4,增加了多模态(支持图片的输入形式),且ChatGPT底层的语言模型直接从GPT3.5升级到了GPT4。
多模态大模型 CLIP, BLIP, BLIP2, LLaVA, miniGPT4, InstructBLIP 系列解读如下图:
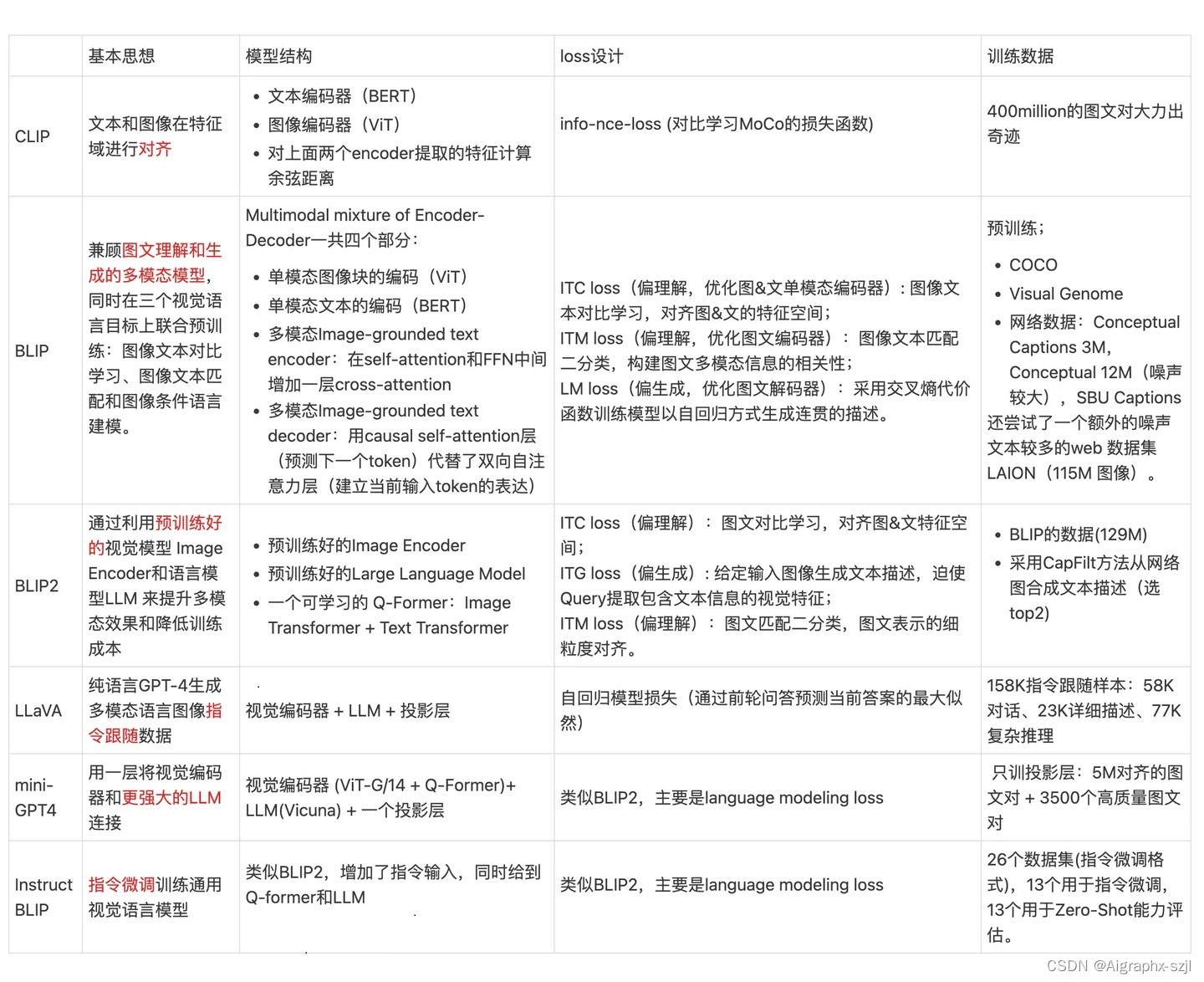
关于大模型核心技术原理,涉及内容较多,后续文章详述。
2.5 大模型训练框架
目前部分深度学习框架,例如Pytorch和Tensorflow,没有办法满足超大规模模型训练的需求,于是微软基于Pytroch开发了DeepSpeed,腾讯基于Pytroch开发了派大星PatricStar,达摩院同基于Tensoflow开发的分布式框架Whale。像是华为昇腾的MindSpore、百度的PaddlePaddle,还有国内的追一科技OneFlow等厂商,对超大模型训练进行了深度的跟进与探索,基于原生的AI框架支持超大模型训练。

下面展开DeepSpeed和MindSpore来简单了解下。
2021年2月份微软发布了DeepSpeed,最核心的是显存优化技术ZeRO(零冗余优化器),通过扩大规模、内存优化、提升速度、控制成本,四个方面推进了大模型训练能力。基于DeepSpeed微软开发了拥有170亿参数的图灵自然语言生成模型(Turing-NLG)。(2021年5月份发布的ZeRO-2,更是支持2000亿参数的模型训练),另外微软联手英伟达,使用4480块A100组成的集群,发布了5300亿参数的NLP模型威震天-图灵(Megatron Turing-NLG)。
当然,作为国内首个支持千亿参数大模型训练的框架MindSpore这里面也提一下。在静态图模式下,MindSpore融合了流水线并行、模型并行和数据并行三种并行技术,开发者只需编写单机算法代码,添加少量并行标签,即可实现训练过程的自动切分,使得并行算法性能调优时间从月级降为小时级,同时训练性能相比业界标杆提升40%。
动态图模式下,MindSpore独特的函数式微分设计,能从一阶微分轻易地扩展到高阶微分,并进行整图性能优化,大幅提升动态图性能;结合创新的通讯算子融合和多流并行机制,较其它AI框架,MindSpore动态图性能提升60%。
最后就是针对大模型的训练,网上很多人会说,大模型需要“大数据+大算力+强算法”三驾马车并驾齐驱。
ZOMI并不是非常认同这个观点,大模型首先是需要规模更大的海量数据,同时需要庞大的算力去支撑这个说没错。但是整体来说,这是一个系统工程,从并行训练到大规模并行训练,其中就包括对AI集群调度和管理,对集群通讯带宽的研究,对算法在模型的并行、数据的并行等策略上与通讯极限融合在一起考虑,求解在有限带宽前提下,数据通讯和计算之间的最优值。
目前在大模型这个系统工程里面,最主要的竞争对手有基于英伟达的GPU+微软的DeepSpeed,Google的TPU+Tensorflow,当然还有华为昇腾Atlas800+MindSpore三大厂商能够实现全面的优化。至于其他厂商,大部分都是基于英伟达的GPU基础上进行一些创新和优化。最后就是,核心技术在市场上并不是最重要的,谁能够为客户创造更大的价值,才是最后的赢家。

3. 大模型综述
3.1 经典大模型综述
这几年深感跟不上这追新打快、日新月异的大模型,更无从了解它们到底是何门何派,用的哪套武功。这个时候可能就需要请出一篇大模型综述来帮忙了!这篇由亚马逊、得克萨斯农工大学与莱斯大学的研究者推出的大模型综述《Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond》,为我们以构建一颗“家谱树”的方式梳理了以 ChatGPT 为代表的大模型的前世今生与未来。它从任务出发,首先为我们搭建了非常全面的大模型实用指南,其次还介绍了大模型在不同任务中的优缺点,最后指出了大模型目前的风险与挑战。
3.1.1 大模型的前世今生
家谱树
追寻大模型的“万灵之主”,大抵应该从那篇《Attention is All You Need》开始,基于这篇由谷歌机器翻译团队提出的由多组 Encoder、Decoder 构成的机器翻译模型 Transformer 开始,大模型的发展大致走上了两条路,一条路是舍弃 Decoder 部分,仅仅使用 Encoder 作为编码器的预训练模型,其最出名的代表就是 Bert 家族。这些模型开始尝试“无监督预训练”的方式来更好的利用相较其他数据而言更容易获得的大规模的自然语言数据,而“无监督”的方式就是 Masked Language Model(MLM),通过让 Mask 掉句子中的部分单词,让模型去学习使用上下文去预测被 Mask 掉的单词的能力。在 Bert 问世之处,在 NLP 领域也算是一颗炸弹,同时在许多自然语言处理的常见任务如情感分析、命名实体识别等中都刷到了 SOTA,Bert 家族的出色代表除了谷歌提出的 Bert 、ALBert之外,还有百度的 ERNIE、Meta 的 RoBERTa、微软的 DeBERTa等等。

可惜的是,Bert 的进路没能突破 Scale Law,而这一点则由当下大模型的主力军,即大模型发展的另一条路,通过舍弃 Encoder 部分而基于 Decoder 部分的 GPT 家族真正做到了。GPT 家族的成功来源于一个研究人员惊异的发现:“扩大语言模型的规模可以显著提高零样本(zero-shot)与小样本(few-shot)学习的能力”,这一点与基于微调的 Bert 家族有很大的区别,也是当下大规模语言模型神奇能力的来源。GPT 家族基于给定前面单词序列预测下一个单词来进行训练,因此 GPT 最初仅仅是作为一个文本生成模型而出现的,而 GPT-3 的出现则是 GPT 家族命运的转折点,GPT-3 第一次向人们展示了大模型带来的超越文本生成本身的神奇能力,显示了这些自回归语言模型的优越性。而从 GPT-3 开始,当下的 ChatGPT、GPT-4、Bard 以及 PaLM、LLaMA 百花齐放百家争鸣,带来了当下的大模型盛世。
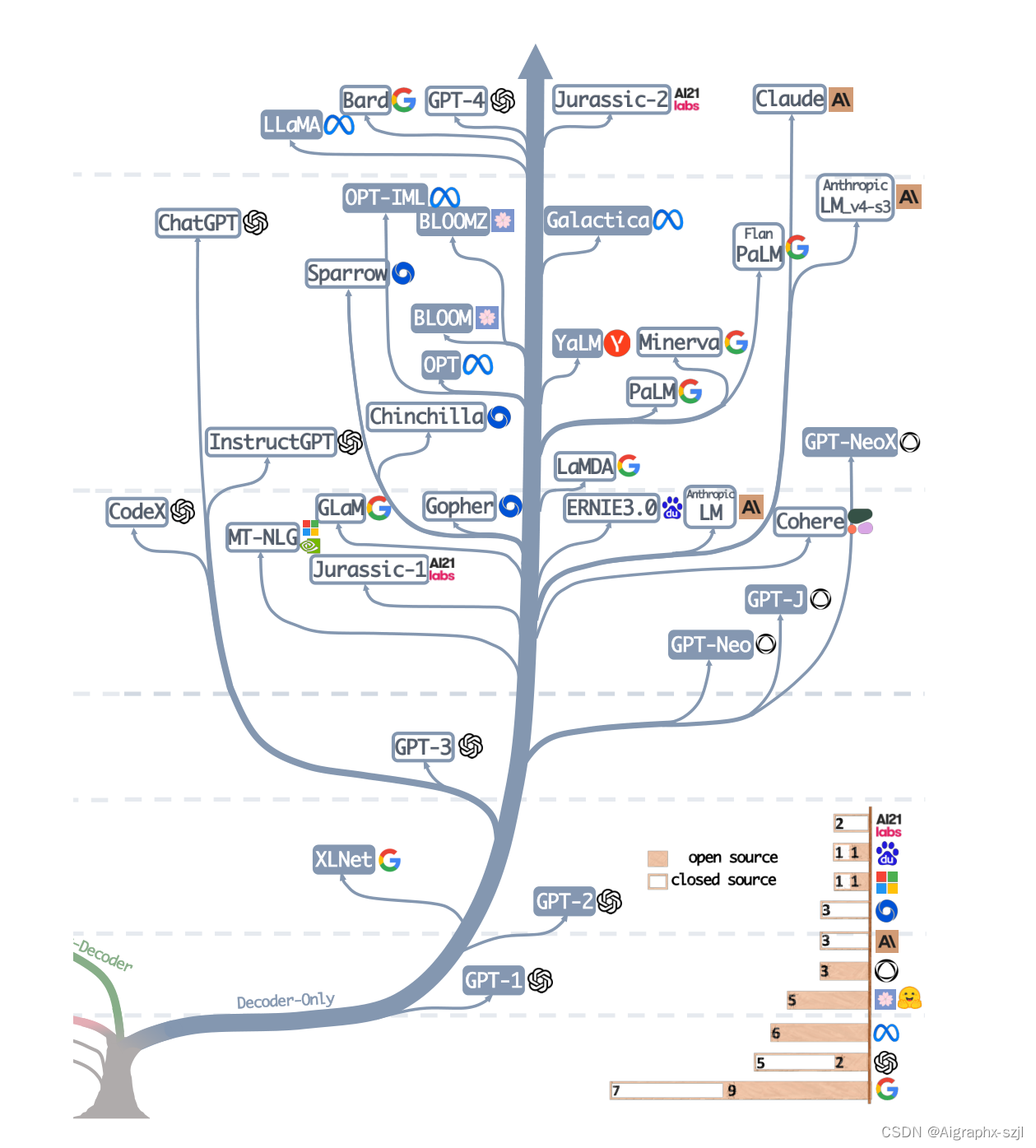
从合并这家谱树的两支,我们可以看到早期的 Word2Vec、FastText,再到预训练模型的早期探索 ELMo、ULFMiT ,再到 Bert 横空出世红极一时;看到GPT 家族默默耕耘直到 GPT-3 惊艳登场,ChatGPT 一飞冲天,技术的迭代之外也可以看到 OpenAI 默默坚持自己的技术路径最终成为目前 LLMs 无可争议的领导者;看到 Google 对整个 Encoder-Decoder 模型架构做出的重大理论贡献;看到 Meta 对大模型开源事业的持续慷慨的参与;当然也看到从 GPT-3 之后 LLMs 逐渐趋向于“闭”源的趋势,未来很有可能大部分研究不得不变成 API-Based 的研究。

Fig,The evolutionary tree of modern LLMs traces the development of language models in recent years and highlights some of the most well-known models. Models on the same branch have closer relationships. Transformer-based models are shown in non-grey colors: decoder-only models in the blue branch, encoder-only models in the pink branch, and encoder-decoder models in the green branch. The vertical position of the models on the timeline represents their release dates. Open-source models are represented by solid squares, while closed-source models are represented by hollow ones. The stacked bar plot in the bottom right corner shows the number of models from various companies and institutions.如图,现代LLM的进化树追溯了近年来语言模型的发展,并突出了其中一些最著名的模型。同一分支上的模型具有更紧密的关系。基于Transformer的模型以非灰色显示:蓝色分支中仅解码器模型,粉色分支中仅编码器模型,绿色分支中编码器-解码器模型。模型在时间线上的垂直位置表示它们的发布日期。开源模型由实心方块表示,而闭源模型由空心方块表示。右下角的堆叠条形图显示了来自不同公司和机构的模型数量。
3.1.2 模型的力量源泉
数据
归根结底,大模型的神奇能力是来源于 GPT 么?我觉得答案是否定的,GPT 家族几乎每一次能力的跃迁,都在预训练数据的数量、质量、多样性等方面做出了重要的提升。大模型的训练数据包括书籍、文章、网站信息、代码信息等等,这些数据输入到大模型中的目的,实质在于全面准确的反应“人类”这个东西,通过告诉大模型单词、语法、句法和语义的信息,让模型获得识别上下文并生成连贯响应的能力,以捕捉人类的知识、语言、文化等等方面。
一般而言,面对许多 NLP 的任务,我们可以从数据标注信息的角度将其分类为零样本、少样本与多样本。无疑,零样本的任务 LLMs 是最合适的方法,几乎没有例外,大模型在零样本任务上遥遥领先于其他的模型。同时,少样本任务也十分适合大模型的应用,通过为大模型展示“问题-答案”对,可以增强大模型的表现性能,这种方式我们一般也称为上下文学习(In-Context Learning)。而多样本任务尽管大模型也可以去覆盖,但是微调可能仍然是最好的方法,当然在一些如隐私、计算等约束条件下,大模型可能仍然有用武之地。
同时,微调的模型很有可能会面对训练数据与测试数据分布变化的问题,显著的,微调的模型在 OOD 数据上一般表现都非常差。而相应的,LLMs 由于并没有一个显式的拟合过程,因此表现要好许多,典型的 ChatGPT 基于人类反馈的强化学习(RLHF)在大部分分布外的分类与翻译任务中都表现优异,在专为 OOD 评估设计的医学诊断数据集 DDXPlus 上也表现出色。
3.1.3 任务导向上手大模型
实用指南
很多时候,“大模型很好!”这个断言后紧跟着的问题就是“大模型怎么用,什么时候用?”,面对一个具体任务时,我们是应该选择微调、还是不假思索的上手大模型?这篇论文总结出了一个实用的“决策流”,根据“是否需要模仿人类”,“是否要求推理能力”,“是否是多任务”等一系列问题帮我们判断是否要去使用大模型。

而从 NLP 任务分类的角度而言:
传统自然语言理解
目前拥有大量丰富的已标注数据的很多 NLP 任务,微调模型可能仍然牢牢把控着优势,在大多数数据集中 LLMs 都逊色于微调模型,具体而言:
- 文本分类:在文本分类中,LLMs 普遍逊色于微调模型;
- 情感分析:在 IMDB 与 SST 任务上大模型与微调模型表现相仿,而在如毒性监测任务中,几乎所有的大模型都差于微调模型;
- 自然语言推理:在 RTE 与 SNLI 上,微调模型优于 LLMs,在 CB 等数据中,LLMs与微调模型相仿;
- 问答:在 SQuADv2、QuAC 和许多其他数据集上,微调模型具有更好的性能,而在 CoQA 上,LLMs 表现与微调模型性能相仿;
- 信息检索:LLMs 尚未在信息检索领域广泛应用,信息检索的任务特征使得没有自然的方式为大模型建模信息检索任务;
- 命名实体识别:在命名实体识别中,大模型仍然大幅度逊色于微调模型,在 CoNLL03 上微调模型的性能几乎是大模型的两倍,但是命名实体识别作为一个经典的 NLP 中间任务,很有可能会被大模型取代。
总之,对于大多数传统自然语言理解的任务,微调模型的效果更好。当然 LLMs 的潜力受限于 Prompt 工程可能仍未完全释放(其实微调模型也并未达到上限),同时,在一些小众的领域,如 Miscellaneous Text Classification,Adversarial NLI 等任务中 ,LLMs 由于更强的泛化能力因而具有更好的性能,但是在目前而言,对于有成熟标注的数据而言,微调模型可能仍然是对传统任务的最优解。
自然语言生成
相较于自然语言理解,自然语言生成可能就是大模型的舞台了。自然语言生成的目标主要是创建连贯、通顺、有意义的符合序列,通常可以分为两大类,一类是以机器翻译、段落信息摘要为代表的任务,一类是更加开放的自然写作,如撰写邮件,编写新闻,创作故事等的任务。具体而言:
- 文本摘要:对于文本摘要而言,如果使用传统的如 ROUGE 等的自动评估指标,LLMs 并没有表现出明显的优势,但是如果引入人工评估结果,LLMs 的表现则会大幅优于微调模型。这其实表明当前这些自动评估指标有时候并不能完整准确的反应文本生成的效果;
- 机器翻译:对于机器翻译这样一个拥有成熟商业软件的任务而言,LLMs 的表现一般略逊于商业翻译工具,但在一些冷门语言的翻译中,LLMs 有时表现出了更好的效果,譬如在罗马尼亚语翻译英语的任务中,LLMs 在零样本和少样本的情况下击败了微调模型的 SOTA;
- 开放式生成:在开放式生成方面,显示是大模型最擅长的工作,LLMs 生成的新闻文章几乎与人类编写的真实新闻无法区分,在代码生成、代码纠错等领域 LLMs 都表现了令人惊讶的性能。
知识密集型任务
知识密集型任务一般指强烈依赖背景知识、领域特定专业知识或者一般世界知识的任务,知识密集型任务区别于简单的模式识别与句法分析,需要对我们的现实世界拥有“常识”并能正确的使用,具体而言:
- 闭卷问答:在 Closed-book Question-Answering 任务中,要求模型在没有外部信息的情况下回答事实性的问题,在许多数据集如 NaturalQuestions、WebQuestions、TriviaQA 上 LLMs 都表现了更好的性能,尤**其在 TriviaQA 中,零样本的 LLMs 都展现了优于微调模型的性别表现;
- 大规模多任务语言理解:大规模多任务语言理解(MMLU)包含 57 个不同主题的多项选择题,也要求模型具备一般性的知识,在这一任务中最令人印象深刻的当属 GPT-4,在 MMLU 中获得了 86.5% 的正确率。
值得注意的是,在知识密集型任务中,大模型并不是百试百灵,有些时候,大模型对现实世界的知识可能是无用甚至错误的,这样“不一致”的知识有时会使大模型的表现比随机猜测还差。如重定义数学任务(Redefine Math)中要求模型在原含义和从重新定义的含义中做出选择,这需要的能力与大规模语言模型的学习到的知识恰恰相反,因此,LLMs 的表现甚至不如随机猜测。
推理任务
LLMs 的扩展能力可以极大的增强预训练语言模型的能力,当模型规模指数增加时,一些关键的如推理的能力会逐渐随参数的扩展而被激活,LLMs 的算术推理与常识推理的能力肉眼可见的异常强大,在这类任务中:
- 算术推理:不夸张的说,GPT-4 的算术与推理判断的能力超过了以往的任何模型,在 GSM8k、SVAMP 和 AQuA 上大模型都具有突破性的能力,值得指出的是,通过思维链(CoT)的提示方式,可以显著的增强 LLMs 的计算能力;
- 常识推理:常识推理要求大模型记忆事实信息并进行多步推理,在大多数数据集中,LLMs 都保持了对微调模型的优势地位,特别在 ARC-C (三-九年级科学考试困难题)中,GPT-4 的表现接近 100%(96.3%)。
除了推理之外,随着模型规模的增长,模型还会浮现一些 Emergent Ability,譬如符合操作、逻辑推导、概念理解等等。但是还有类有趣的现象称为“U形现象”,指随着 LLMs 规模的增加,模型性能出现先增加后又开始下降的现象,典型的代表就是前文提到的重定义数学的问题,这类现象呼唤着对大模型原理更加深入与细致的研究。
3.1.4 大模型的挑战与未来
总结
大模型必然是未来很长一段时间我们工作生活的一部分,而对于这样一个与我们生活高度同频互动的“大家伙”,除了性能、效率、成本等问题外,大规模语言模型的安全问题几乎是大模型所面对的所有挑战之中的重中之重,机器幻觉是大模型目前还没有极佳解决方案的主要问题,大模型输出的有偏差或有害的幻觉将会对使用者造成严重后果。同时,随着 LLMs 的“公信度”越来越高,用户可能会过度依赖 LLMs 并相信它们能够提供准确的信息,这点可以预见的趋势增加了大模型的安全风险。
除了误导性信息外,由于 LLMs 生成文本的高质量和低成本,LLMs 有可能被利用为进行仇恨、歧视、暴力、造谣等攻击的工具,LLMs 也有可能被攻击以未恶意攻击者提供非法信息或者窃取隐私,据报道,三星员工使用 ChatGPT 处理工作时意外泄漏了最新程序的源代码属性、与硬件有关的内部会议记录等绝密数据。

除此之外,大模型是否能应用于敏感领域,如医疗保健、金融、法律等的关键在于大模型的“可信度”的问题,在当下,零样本的大模型鲁棒性往往会出现降低。同时,LLMs 已经被证明具有社会偏见或歧视,许多研究在口音、宗教、性别和种族等人口统计类别之间观察到了显着的性能差异。这会导致大模型的“公平”问题。
最后,如果脱开社会问题做个总结,也是展望一下大模型研究的未来,目前大模型主要面临的挑战可以被归类如下:
- 实践验证:当前针对大模型的评估数据集往往是更像“玩具”的学术数据集,但是这些学术数据集无法完全反应现实世界中形形色色的问题与挑战,因此亟需实际的数据集在多样化、复杂的现实问题上对模型进行评估,确保模型可以应对现实世界的挑战;
- 模型对齐:大模型的强大也引出了另一个问题,模型应该与人类的价值观选择进行对齐,确保模型行为符合预期,不会“强化”不良结果,作为一个高级的复杂系统,如果不认真处理这种道德问题,有可能会为人类酝酿一场灾难;
- 安全隐患:大模型的研究要进一步强调安全问题,消除安全隐患,需要具体的研究确保大模型的安全研发,需要更多的做好模型的可解释性、监督管理工作,安全问题应该是模型开发的重要组成部分,而非锦上添花可有可无的装饰;
- 模型未来:模型的性能还会随着模型规模的增加而增长了,这个问题估计 OpenAI 也难以回答,我们针对大模型的神奇现象的了解仍然十分有限,针对大模型原理性的见解仍然十分珍贵。
3.1.5 自动驾驶通用大模型UniAD
2023年6月21日,自动驾驶通用大模型(Unified Autonomous Driving,UniAD),CVPR上自动驾驶领域第一篇最佳论文。其核心技术价值是建立了一套端到端感知决策一体框架,融合多任务联合学习新范式,可实现更有效的信息交换、协调感知预测决策,进而能进一步提升路径规划能力。这也是该文获得CVPR Best Paper Award称号的理由。
UniAD由4个基于Transformer解码器的感知预测模块以及1个规划模块组成,整体上是一套自动驾驶通用模型框架。
UniAD首次将感知、预测和规划等3大类主任务,以及包括目标检测、目标跟踪、场景建图、轨迹预测、栅格预测和路径规划在内的6小类子任务,整合到统一的基于Transformer的端到端网络框架内,成为一个全栈关键任务驾驶的通用模型。
在NuScenes真实场景数据集框架内,UniAD所有相关任务都达到SoTA(最佳性能:State of The Art),尤其是预测和规划效果远超其他模型。
简单来说,就解决“多任务”问题,通过多个Transformer模块,UniAD实现了多任务层级式结合。对不同任务间的信息,也能实现全角度、多方位交互。通过多组查询向量,UniAD达成了物体与地图的建模,随之将预测结果传递至规划模块,用于规划安全路径。
应用这套框架的自动驾驶全栈解决方案,能提升多目标跟踪准确率超过20%,车道线预测准确率提升30%,预测运动位移和规划的误差分别降低38%和28%。
3.2 多模态大模型综述
论文:A Survey on Multimodal Large Language Models
具体来说,论文将多模态大模型(Multimodal Large Language Model,MLLM)定义为“由LLM扩展而来的具有接收与推理多模态信息能力的模型”。
这类模型相较于热门的单模态LLM,具有以下优势:
- 更符合人类认知世界的习惯。人类具有多种感官来接受多种模态信息,这些信息通常是互为补充、协同作用的。因此,使用多模态信息一般可以更好地认知与完成任务。
- 更加强大与用户友好的接口。通过支持多模态输入,用户可以通过更加灵活的方式输入与传达信息。
- 更广泛的任务支持。LLM通常只能完成纯文本相关的任务,而MLLM通过多模态可以额外完成更多任务,如图片描述和视觉知识问答等。
因此,要想研究这类多模态大模型,往往需要掌握三个关键技术:
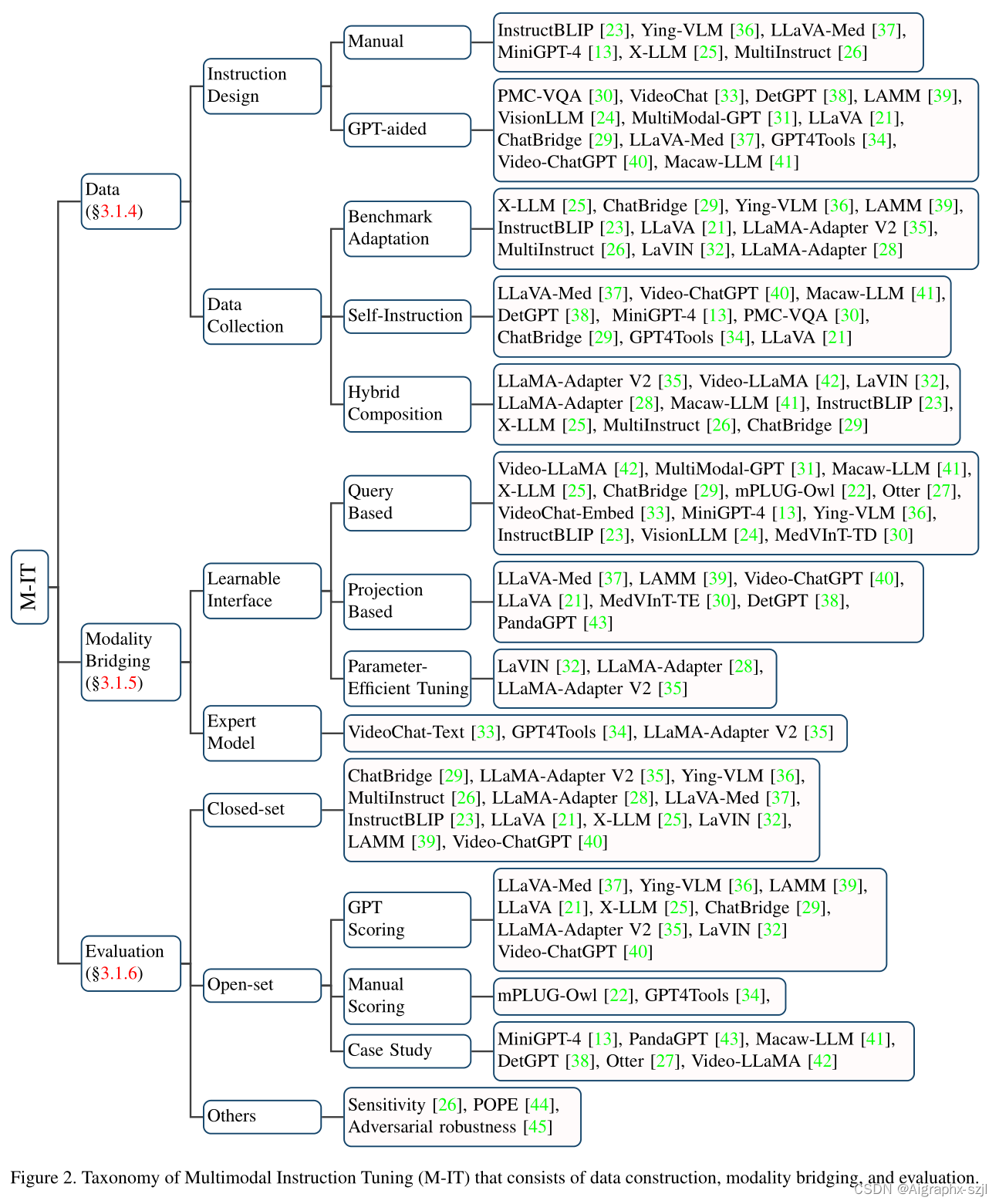
- 多模态指令微调(Multimodal Instruction Tuning, M-IT)
- 多模态上下文学习(Multimodal In-Context Learning, M-ICL)
- 多模态思维链(Multimodal Chain of Thought, M-CoT)

3.2.1 多模态指令微调M-IT
(Multimodal Instruction Tuning,M-IT) 是一种技术,它涉及在一组以指令格式排列的数据集上对预训练的LLMs进行微调。通过这种微调,LLMs可以遵循新的指令来推广到未见过的任务,从而提高零样本性能。这个简单而有效的想法已经引发了NLP领域中后续工作的成功,例如ChatGPT、InstructGPT、FLAN和OPT-IML等。
Self-Instruction 是指通过自我指导的方式构建指令格式的数据集。现有的benchmark可能不能实现某些真实场景的应用,如多轮对话等,此时就需要自我指导。这种方法的优点是可以生成大量的数据,而不需要人工标注。具体来说,一些指令跟随样本被手工制作为种子示例,然后通过提示ChatGPT/GPT-4生成更多的指令样本,以种子示例作为引导。LLaVA [21]将这种方法扩展到多模态领域,通过将图像转换为标题和边界框的文本,并提示GPT-4在种子示例的上下文中生成新数据。通过这种方式,构建了一个M-IT数据集,称为LLaVA-Instruct-150k。
3.2.2 多模态上下文学习M-ICL
ICL是LLMs的重要新兴能力之一。ICL有两个好处:(1)与传统的监督学习范式不同,传统的监督学习范式从丰富的数据中学习隐含的模式,而ICL的关键在于从类比中学习[74]。具体来说,在ICL设置中,LLMs从少量的示例以及可选的指令中学习,并推广到新的问题,从而以少量的方式解决复杂和未知的任务[14、75、76]。(2)ICL通常以无需训练的方式实现[74],因此可以在推理阶段灵活地集成到不同的框架中。与ICL密切相关的技术是Instruction-Tuning,它在实证上被证明可以增强ICL的能力。
在MLLM的背景下,ICL已经扩展到更多的模态,导致了多模态ICL(Multimodal In-Context Learning,M-ICL)。在推理时,M-ICL可以通过添加demostration set(即一组上下文样本)到原始样本中来实现。在这种情况下,模板可以扩展。请注意,我们列出了两个上下文示例以进行说明,但示例的数量和顺序可以灵活调整。事实上,模型通常对演示的排列敏感[74、77]。
3.2.3 多模态思维链M-CoT
CoT是一种技术,其主要思想是促使LLMs不仅输出最终答案,还输出导致答案的推理过程,类似于人类的认知过程。CoT已被证明在复杂的推理任务中非常有效。它通常涉及一系列中间推理步骤,可以帮助LLMs更好地理解任务和生成正确的答案。CoT通常与Multimodal ICL技术一起使用,以提高LLMs的推理能力。

Learning Paradigms
学习范式也是值得研究的一个方面。广义上有三种获取(Multimodal Chain of Thought,M-CoT)能力的方式,即通过微调和无需训练的少量/零样本学习。这三种方式的样本量要求按降序排列。
直觉上,微调方法通常涉及为M-CoT学习策略策划特定的数据集。例如,ScienceQA [65] 构建了一个科学问答数据集,其中包含lectures和explanations,可以作为学习CoT推理的来源,并在这个数据集上进行微调。Multimodal-CoT [82] 也使用ScienceQA基准测试,但是以两步方式生成输出,即基于理由(推理步骤链)和基于理由的最终答案。
与微调相比,少量/零样本学习更具计算效率。它们之间的主要区别在于,少量样本学习通常需要手工制作一些上下文示例,以便模型可以更轻松地逐步学习推理。相比之下,零样本学习不需要任何特定的CoT学习示例。在这种情况下,通过提示设计的指令,如“让我们逐帧思考”或“这两个关键帧之间发生了什么”[85, 86],模型学习利用嵌入式知识和推理能力,而无需明确的指导。类似地,一些工作[14, 83]通过任务和工具使用的描述来提示模型,以便生成程序或执行步骤的序列。
Chain Configuration
链式配置是推理的一个重要方面,可以分为自适应和预定义两种形式。前一种配置要求LLMs自行决定何时停止推理链[14, 65, 75, 76, 82, 83],而后一种设置则通过预定义的长度来停止推理链。
Generation Patterns
如何构建推理链是一个值得研究的问题。我们将当前的工作总结为两种模式:(1)基于填充的模式和(2)基于预测的模式。具体而言,基于填充的模式要求在前后上下文(前后步骤)之间推导出步骤以填补逻辑间隙[85, 86]。相比之下,基于预测的模式需要在给定条件(如指令和先前的推理历史)下扩展推理链[14, 65, 75, 76, 82, 83]。这两种模式共享一个要求,即生成的步骤应该是一致和正确的。
3.2.4 辅助的视觉推理LAVR
除此之外,还需要针对它的一个应用进行研究(以 LLM 为核心的多模态系统),即LLM辅助的视觉推理(LLM-Aided Visual Reasoning, LAVR)。

4. 大模型评测
4.1 经典大模型评测
4.1.1 评测内容
大型语言模型LLMs因其在学术界和工业界展现出前所未有的性能而备受青睐。然而,随着LLMs在研究和实际应用中的广泛使用,对其进行有效评测变得愈发重要。近期已有多篇论文围绕大模型的评估进行研究,但尚未有文章对评测的方法、数据、挑战等进行完整的梳理。本文介绍大模型评测领域的第一篇综述文章《A Survey on Evaluation of Large Language Models》。该论文一共调研了两百余篇文献,以「评测对象 (what to evaluate)」 、「评测领域 (where to evaluate)」 、「评测方法 (How to evaluate)」 和目前的「评估挑战」等几大方面对大模型的评估进进行了详细的梳理和总结。 本文的目标是增强对大模型当前状态的理解,阐明它们的优势和局限性,并为其未来发展提供见解。

本文主要从三个方面对现有工作进行了探索:
- 评估内容 (What to evaluate),对海量的LLMs评估任务进行分类并总结评估结果;
- 评估领域 (Where to evaluate),对LLMs评估常用的数据集和基准进行了总结;
- 评估方法 (How to evaluate),总结了目前流行的两种LLMs评估方法。
4.1.2 评测总结
在这一部分,总结了LLMs在不同任务中的成功和失败案例。
「LLMs能够在哪些方面表现出色?」
- LLMs在生成文本方面展现出熟练度,能够产生流畅且准确的语言表达。
- LLMs在语言理解方面表现出色,能够进行情感分析和文本分类等任务。
- LLMs具备强大的语境理解能力,能够生成与输入一致的连贯回答。
- LLMs在多个自然语言处理任务中表现出令人称赞的性能,包括机器翻译、文本生成和问答任务。
「LLMs在什么情况下可能会失败?」
- LLMs在生成过程中可能会表现出偏差和不准确性,导致产生有偏差的输出。
- LLMs在理解复杂的逻辑和推理任务方面能力有限,在复杂的环境中经常出现混乱或错误。
- LLMs在处理大量数据集和长期记忆方面面临限制,这可能在处理冗长的文本和涉及长期依赖的任务方面带来挑战。
- LLMs在整合实时或动态信息方面存在局限性,使得它们不太适合需要最新知识或快速适应变化环境的任务。
- LLMs对提示非常敏感,尤其是敌对提示,这会触发新的评估和算法,以提高其鲁棒性。
- 在文本摘要领域,可以观察到LLMs可能在特定的评估指标上表现出低于标准的性能,这可能归因于那些特定指标的内在限制或不足。
- LLMs在反事实任务中不能取得令人满意的表现。
4.1.3 重大挑战
评估作为一门新学科:对大模型评估的总结启发我们重新设计了许多方面。在本节中将介绍以下7个重大挑战。
- 「设计AGI基准测试」。什么是可靠、可信任、可计算的能正确衡量AGI任务的评估指标?
- 「设计AGI基准完成行为评估」。除去标准任务之外,如何衡量AGI在其他任务、如机器人交互中的表现?
- 「稳健性评估」。目前的大模型对输入的prompt非常不鲁棒,如何构建更好的鲁棒性评估准则?
- 「动态演化评估」。大模型的能力在不断进化、也存在记忆训练数据的问题。如何设计更动态更进化式的评估方法?
- 「可信赖的评估」。如何保证所设计的评估准则是可信任的?
- 「支持所有大模型任务的统一评估」。大模型的评估并不是终点、如何将评估方案与大模型有关的下游任务进行融合?
- 「超越单纯的评估:大模型的增强」。评估出大模型的优缺点之后,如何开发新的算法来增强其某方面的表现?
本文的重点是,「评估应该被视为推动LLMs和其他人工智能模型成功的基本学科。」 现有的研究方案不足以对LLMs进行全面的评估,这可能为未来的LLMs评估研究带来新的机遇。
4.2 多模态大模型评测
A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
随着多模态LLM的不断发展,它在多模态任务中展示出了惊人的能力,然而,目前的研究缺乏对MLLM性能的全面评估。因此,需要一个综合的评估基准来填补这一空白,全面评估MLLM的能力。由腾讯优图实验室和厦门大学的研究者提出了MME,一个用于多模态大型语言模型的综合评估基准,试图解决这个问题。
本篇论文介绍了一种名为 MME 的多模态大型语言模型评估基准,该基准用于全面评估多模态大型语言模型的性能。该基准包括 14 个子任务,涵盖了感知和认知能力的方方面面。为了避免数据泄漏,所有指令答案对的注释都是手动设计的。简洁的指令设计使能够公平地比较 MLLMs,而不需要费力地进行提示工程。此外,这样的指令设计可以更轻松地进行定量统计。通过对 10 个先进的 MLLMs 进行了全面评估,结果表明现有的 MLLMs 仍然有很大的改进空间,同时也揭示了后续模型优化的潜在方向。

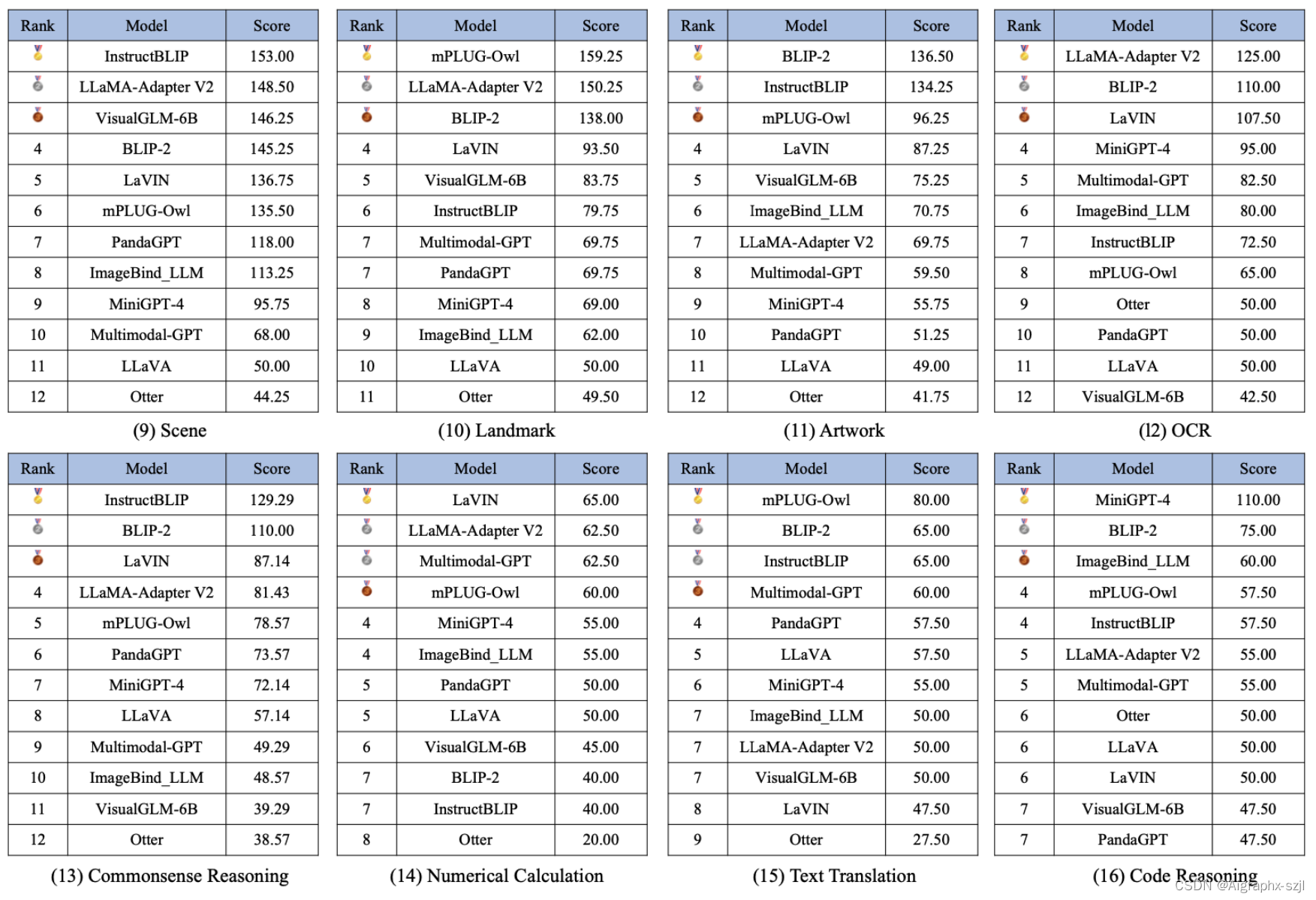
本文总结了四个常见的问题,这些问题在很大程度上影响了MLLM的性能。第一个问题是不遵循指令。尽管我们采用了非常简洁的指令设计,但有些MLLM并没有按照指令进行回答,而是自由回答。例如,如图4的第一行所示,指令明确要求“请回答是或否”,但MLLM只是做出陈述性表达。如果在生成的语言开头没有出现“是”或“否”,则判断模型回答错误。我们认为一个好的MLLM(特别是在指令调整之后)应该能够遵循这样简单的指令,这在日常生活中也非常常见。
第二个问题是感知能力的缺乏。如图4的第二行所示,MLLM错误地识别了第一张图像中香蕉的数量,并错误地阅读了第二张图像中的字符,导致错误的答案。我们注意到感知的性能容易受到指令微妙之处的影响,因为同一张图像的两个指令只有一个词的不同,却导致完全不同甚至矛盾的感知结果。
第三个问题是推理能力的缺乏。如图4的第三行所示,从红色文本中我们可以看出,MLLM已经知道第一张图像不是办公室,但仍然给出了错误的答案“是”。类似地,在第二张图像中,MLLM计算出了正确的算术结果,但最终却给出了错误的答案。这些现象表明在MLLM的推理过程中逻辑链断裂了。添加CoT提示,例如“我们逐步思考”[19],可能会得到更好的结果。我们期待进一步深入的研究。
第四个问题是按照指令进行的对象幻觉,这在图4的第四行中有例子。当指令中包含描述一个图像中不存在的对象时,MLLM会想象该对象存在,并最终给出“是”的答案。不断回答“是”的情况导致准确率约为50%,准确率+约为0,如表1、2和3所示。这表明迫切需要抑制幻觉,并且社区应该考虑生成答案的可靠性。
5. 大模型设计
本部分在施工中,针对具体自动驾驶大模型场景还经验不足,欢迎各位拍砖。
下面是引用通用大模型的相关介绍文章,修改而来。
AIGC模型训练过程:
- 训练GPT(预训练阶段【数据收集→token 化→超参数→批组化→评估模型→微调下游任务/少样本prompt】
- +SFT监督式微调阶段
- +RLHF【奖励建模+RL】
- +ChatGPT(RLHF模型)对比 Claude(SFT模型)、使用 GPT(序列采样token/token来思考【知识广博+储存大量事实+无损记忆】/思维链CoT/ReAct+AutoGPT/指定顺序优化)
设计一个类似GPT-3.5/GPT-4的大模型从开发→部署→应用需要经过的八大步骤。
需要经历多个阶段,包括确定问题领域和模型任务、数据采集、数据标注、数据处理、模型设计、模型训练、模型调优、模型测试和评估、模型部署和应用等。在每个阶段中需要仔细考虑各种因素,并根据具体情况进行调整和优化,同时需要不断进行优化和改进,以提高模型的性能和效率。
需要经历多个步骤,包括确定目标、设计模型架构、收集数据、预处理数据、训练模型、微调模型和部署模型。在整个过程中需要注意细节,例如模型架构的选择、数据集的质量和可靠性、训练参数的调整等等。每个步骤都需要花费大量的时间和精力,因此需要进行全面的计划和管理。
需要注意的是,以下步骤和内容是相互关联、相互影响的,需要综合考虑和平衡,才能设计出一个高效、准确、可靠的大模型。
5.1 目标和开发计划
5.1.1 确定目标
首先需要明确模型要解决的问题、目标任务和应用场景。例如,GPT-3.5是一款基于语言模型的人工智能模型,用于自然语言处理和语言生成任务。比如选择一个特定的任务,如自动驾驶、文本分类、问答、图文生成等。
5.1.2 开发计划
下面是一个开发、部署和上线一个像GPT-3.5、GPT-4这样的大模型大致的时间安排:
- 研究阶段:需要花费数月时间进行前期的研究、技术选型、设计等工作。
- 数据准备阶段:需要数月的时间,包括数据采集、清洗、整合、标注等工作。
- 模型训练阶段:需要数月的时间,具体时间根据模型大小、数据量、算法等因素而定。
- 模型评估阶段:需要数周至数月的时间,包括模型的各项指标、性能、准确率、速度等的评估和优化。
- 部署准备阶段:需要几周的时间,包括模型的部署环境、硬件、软件等的准备。
- 模型部署阶段:需要数周至数月的时间,包括模型部署、测试、调优等工作。
- 模型上线阶段:需要几周的时间,包括模型上线、监控、维护等工作。
- 需要注意的是,以上时间仅供参考,具体时间安排还需要根据实际情况而定。同时,开发、部署和上线大模型的成本也非常高,需要投入大量的人力、物力和财力。
5.1.3 团队分工
团队分工:需要组建一个包括数据工程师、算法工程师、架构设计师、硬件工程师、模型训练师、模型调优师和部署工程师等各类专业人员的团队,进行协同工作。
模型开发需要多个团队成员协同完成,可以根据各自的专业领域和技能分工,如数据收集和预处理、模型架构设计、模型训练和调优、部署和应用等。同时,需要进行有效的沟通和协调,确保整个开发过程的顺利进行。
在实现一个像GPT-3.5这样的大型自然语言处理模型时,需要组建一个具有多个技能的团队。这个团队可以包括数据科学家、机器学习工程师、软件开发人员、系统管理员等不同角色的人员。
5.1.4 注意事项
- 数据质量:数据集的收集和预处理是设计大型模型的重要步骤,需要保证数据集的质量和代表性,以提高模型的性能。
- 扩展性:在模型架构设计过程中,需要考虑到模型的可扩展性和可重用性,以便在未来的任务中进行调整和优化。
- 多重保证:在模型训练和测试期间,需要使用多种不同的技术和方法来确保模型的质量和性能。例如,需要使用交叉验证和模型选择等技术来选择最佳的模型。
- 资源均衡:在模型部署和优化期间,需要考虑到模型的计算资源和内存使用等问题,以确保模型能够在实际应用中高效地运行。
5.2 数据工程
确定目标任务后,需要收集和准备相关的数据集。这通常需要花费大量的时间和精力来获取和标注数据,以确保数据集的质量和代表性。数据的数量、质量和多样性对模型的性能有很大影响。需要选择合适的数据集,并进行数据清洗和预处理。数据的质量和多样性对于模型的性能至关重要,因此需要充分的时间和精力来准备和清理数据,还要评估数据的质量和多样性。
- 数据集准备:首先,需要准备一个大规模的数据集。从多个数据源收集和筛选数据,这个数据集可以来自于互联网上的各种来源,例如维基百科、新闻文章、社交媒体或者现场采集驾驶视频等。
- 自动驾驶场景问答对准备;
- 数据库和存储:选择适合的数据库和存储方式,以管理和存储大量数据,如MySQL,Hadoop或其他方式等。
- 数据收集与预处理:在数据采集过程中,由于各种原因,收集到的数据可能存在噪声、异常值、缺失值等问题,因此需要进行数据预处理与清洗。常见的数据预处理与清洗包括去重、缺失值填充、异常值处理等操作。这些操作可以减少模型对于噪声和异常数据的敏感度,提高模型的泛化能力。视频数据还首先需要通过一系列算法切割成合适的图片等。
- 数据标注:通过专用工具进行数据标注,自动标注为主,人工检测为辅。
5.3 算法工程
AI框架:如PyTorch和TensorFlow等,或者更进一步的DeepSpeed、派大星PatricStar框架,或者Whale、MindSpore、PaddlePaddle等。
算法和模型:选择适合的算法和模型,如卷积神经网络、循环神经网络和自注意力模型等。需要选择合适的深度学习算法来训练模型。例如,可以选择Transformer、GPT、BERT等模型,然后根据需求进行改进和优化,如使用梯度累积、学习率调整等技巧。同时需要设计合适的预训练、微调和生成模块。
在这个阶段,需要制定模型的总体架构和选择适合的算法,包括:
- 选择适当的预训练模型和架构
- 定义输入和输出的格式和结构
- 设计和实现自定义的模块和组件
5.4 模型架构
根据任务和数据集的特点设计适合的模型架构。这个过程可能涉及到深度学习、机器学习和自然语言处理等领域的知识。需要设计合适的模型架构,包括网络结构、层数、卷积核大小等。同时需要考虑模型的可解释性和可训练性。
架构设计:设计模型的整体架构,包括网络结构、模型参数、损失函数等。设计模型的整体架构,可以考虑使用 Transformer 或其变种模型,如 GPT、BERT 等。根据实际需求,可以设计多层的编码器和解码器,以及注意力机制等模块。
模型架构设计是设计一个大模型的核心步骤。这需要对相关领域的先前研究进行综合评估和分析,以确定适当的模型结构和参数。需要考虑到模型的深度、宽度、层数、注意力机制、卷积神经网络(CNN)和循环神经网络(RNN)等。
GPT-3.5的架构非常复杂,包括了多个层次的神经网络结构。在这里,我们可以使用Python的深度学习框架,例如TensorFlow或PyTorch,来实现这个模型。具体来说,我们可以使用Transformer+BEV模型结构。
架构设计和实现:设计模型的架构和实现,并进行优化,如使用分布式训练、模型压缩等技术来提高训练效率和模型性能。
5.5 硬件配置
由于GPT-3.5是一个非常大的模型,无法在单个计算机上进行实现和训练,需要使用大规模的计算资源来进行训练和推理。因此,在实现这个模型之前,需要考虑如何配置计算机硬件,以便于支持模型的运行。这包括选择合适的GPU或TPU,以及优化计算机网络和存储系统,以提高模型的性能和效率。
硬件配置:由于模型规模较大,需要使用高性能的计算机进行训练和推理。需要选择合适的硬件配置来训练和部署模型。例如,可以选择GPU或TPU加速训练和推理,并进行优化,如使用混合精度训练、模型并行等技术来提高训练效率和模型性能。
计算机硬件和云服务:选择适合的计算机硬件和云服务,以提高训练和推理速度,如GPU和云计算服务等。
5.6 大模型预训练
在准备好数据集和模型架构之后,我们可以开始训练模型。由于GPT-3.5是一个非常大的模型,需要使用分布式训练技术来加速训练过程。在Python中,可以使用Horovod和MPI等工具来实现分布式训练。
- 模型训练:使用预处理后的文本数据集对模型进行训练,采用大规模分布式训练,以提高训练效率。训练过程中需要注意参数初始化、学习率调整、梯度裁剪等技巧,以确保模型训练的稳定和收敛。训练一个大型的神经网络需要使用大量的计算资源和时间。需要使用高性能计算集群和并行计算技术来提高训练速度。通常需要进行超参数调整和模型优化等步骤以提高模型性能。模型训练是整个模型设计的核心环节。训练过程中需要确定模型的结构和超参数,并使用大规模数据集进行训练。针对大模型的训练,通常需要使用分布式计算框架进行训练,如TensorFlow、PyTorch等。模型训练的时间通常需要数小时甚至数天以上,具体时间取决于模型规模、训练数据集的大小、计算硬件等因素;
- 模型评估与验证:使用准备好的数据集对模型进行训练,并在验证集上进行验证和调整。这个过程通常需要花费大量时间和计算资源。模型训练和调优完毕后,需要对模型进行测试和评估,以确保模型的性能符合要求。常见的模型测试和评估方法包括交叉验证、测试集评估等。通过这些方法可以评估模型的准确率、召回率、精度、F1分数等指标,以及模型对于不同场景和数据的适应能力,并使用测试集来验证模型的泛化性能。比较不同模型和算法的性能,选择最佳的模型。
模型训练是模型开发的核心环节,需要充分利用计算资源和时间来提高模型性能。具体包括:
- 使用大规模的数据集进行预训练;
- 调整模型的各个参数,包括学习率、批次大小、正则化等;
- 进行针对特定任务的微调。
5.7 大模型微调
在预训练完成后,需要将模型在特定任务上进行Fine-tuning(微调)。对预训练模型进行微调,使用特定任务的数据集对其进行重新训练。这包括对模型的权重进行微调和训练超参数进行调整,以使其在特定任务上表现更好。对微调后的模型进行评估和调整。这通常涉及对验证集进行评估,以确定模型的性能和确定是否需要进行调整。
- 模型调优:需要对模型进行调优,包括超参数调整(学习率、批次大小等)、正则化、优化器选择、损失函数选择、dropout等,在Python中,可以使用TensorFlow或PyTorch等深度学习框架提供的调优工具来实现这些操作,以提高模型的性能和准确度。同时需要进行模型压缩、模型剪枝、模型蒸馏等,这些方法可以减小模型的规模,降低模型的计算成本,同时保持模型的性能,可以以提高模型的效率和性能。使用测试数据集对模型进行评估,并根据评估结果对模型进行调优。可以考虑使用 BLEU、ROUGE、METEOR 等指标进行评估;
- 大模型CoT,IFT,RLHF,PPO等核心技术的运用;
- 模型迭代:根据测试和用户反馈,对模型进行调优和迭代,如调整超参数、增加数据量、修改模型结构等来提高模型效果;
- 参数调整和优化:选择合适的优化算法、损失函数等,并调整模型参数,以获得更好的性能。这个过程需要不断地进行实验和验证。
5.8 部署
在完成模型预训练和微调之后,需要将模型部署到实际的应用场景中。这可以通过Python的Web框架,例如Flask或Django来实现。具体来说,可以将模型封装成一个API,并通过HTTP协议提供服务,以便于其他应用程序调用和使用。
需要将模型部署到合适的平台上,例如云端服务、本地服务器或移动设备。同时需要考虑模型的可扩展性和高可用性。将训练好的模型部署到实际应用中,进行测试和使用。这个过程需要考虑模型的可扩展性、安全性和可维护性等方面。
- 模型格式:将模型保存为可部署格式,如ONNX或TensorFlow。
- 硬件配置:选择合适的硬件资源,如GPU、TPU等,以保证模型训练和推理的高效性。
- 部署和测试:将模型部署到生产环境中,并进行测试和验证,通过进行性能测试和优化,以确保模型在实时应用中的性能和可扩展性。如使用A/B测试、用户调查等方式来评估模型效果。模型部署的方式包括Web服务、API接口、移动应用程序等。在部署过程中需要考虑模型的计算成本、延迟、安全性等因素。模型部署后,需要进行实时监控和优化,以保证模型的性能和稳定性。
- 部署和应用:将训练好的模型部署到实际应用场景中,可以考虑使用 Flask、Django 等框架进行部署。在应用场景中,可以通过 API 调用模型,生成自然语言文本。
- 部署和优化:在模型验证和测试后,需要将模型部署到实际应用中,进行性能调优和内存优化,优化部署和推理速度。这需要考虑模型的计算资源、内存使用和响应速度等问题。还需要对模型进行优化以提高其运行效率和准确性。
本节引用论文链接:
https://arxiv.org/pdf/2108.07258.pdf On the Opportunities and Risks of Foundation Models
https://arxiv.org/pdf/2304.13712.pdf Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond
https://arxiv.org/abs/2306.13549 A Survey on Multimodal Large Language Models
https://arxiv.org/pdf/2307.03109.pdf A Survey on Evaluation of Large Language Models
https://arxiv.org/abs/2306.13394 A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
引用博客链接:
https://blog.csdn.net/wawa_nudt/article/details/124344203
https://blog.csdn.net/Kenji_Shinji/article/details/125455825
https://blog.csdn.net/xixiaoyaoww/article/details/130703957
https://blog.csdn.net/qq_41185868/article/details/129786149
这篇关于51-2 一文讲通大模型的起源、核心技术、训练框架及典型应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






