
相关文章

百度/小米/滴滴/京东,中台架构比较
小米中台建设实践 01 小米的三大中台建设:业务+数据+技术 业务中台--从业务说起 在中台建设中,需要规范化的服务接口、一致整合化的数据、容器化的技术组件以及弹性的基础设施。并结合业务情况,判定是否真的需要中台。 小米参考了业界优秀的案例包括移动中台、数据中台、业务中台、技术中台等,再结合其业务发展历程及业务现状,整理了中台架构的核心方法论,一是企业如何共享服务,二是如何为业务提供便利。
Imageview在百度地图中实现点击事件
1.首先第一步,需要声明的全局有关类的引用 private BMapManager mBMapMan; private MapView mMapView; private MapController mMapController; private RadioGroup radiogroup; private RadioButton normalview; private RadioBu

百度之星 2015 复赛 1001 (数长方形)
数长方形 Accepts: 595 Submissions: 1225 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Problem Description 小度熊喜欢玩木棒。一天他在玩木棒的时候,发现一些木棒会形成长方形

百度之星 2015 初赛(1) 1002 找连续数
找连续数 Accepts: 401 Submissions: 1911 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Problem Description 小度熊拿到了一个无序的数组,对于这个数组,小度熊想知道是
百度之星初赛1002(二分搜索)
序列变换 Accepts: 816 Submissions: 3578 Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Problem Description 给定序列 A={A1,A2,...,An} , 要求改变序列A中

百度之星初赛1006(计算几何:能包含凸包的最小矩形面积)
矩形面积 Accepts: 717 Submissions: 1619 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Problem Description 小度熊有一个桌面,小度熊剪了很多矩形放在桌面上,小度熊想知道能把这些

【python 百度指数抓取】python 模拟登陆百度指数,图像识别百度指数
一、算法思想 目的奔着去抓取百度指数的搜索指数,搜索指数的爬虫不像是其他爬虫,难度系数很高,分析之后发现是图片,坑爹的狠,想了下,由于之前做过身份证号码识别,验证码识别之类,豁然开朗,不就是图像识别麽,图像识别我不怕你,于是就有了思路,果然有异曲同工之妙,最后成功被我攻破了,大致思路如下: 1、首先得模拟登陆百度账号(用selenium+PhantomJS模拟登陆百度,获取cookie) 2
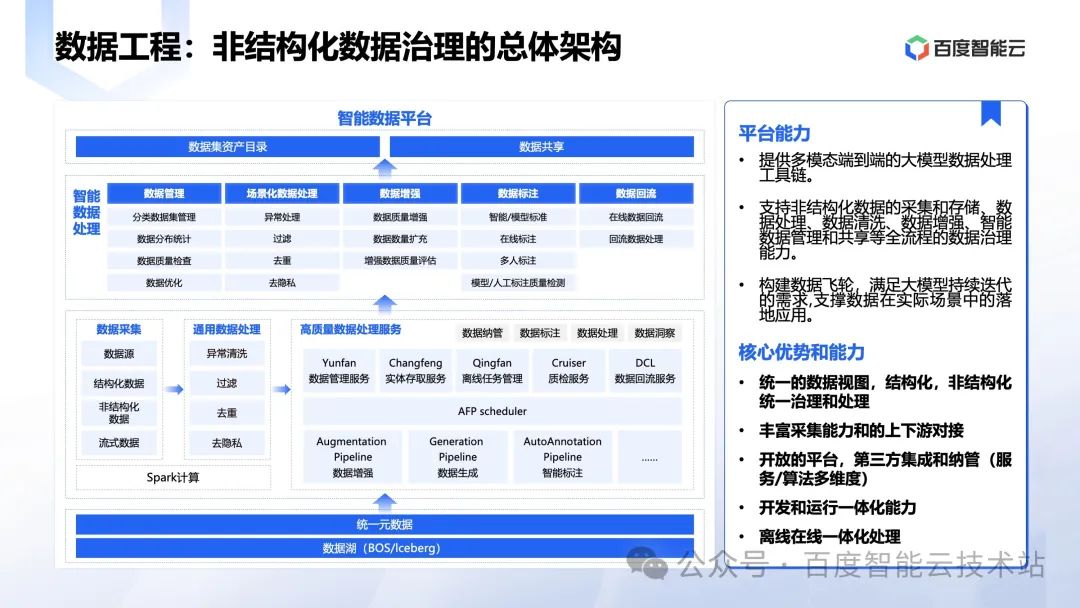
百度智能云向量数据库创新和应用实践分享
本文整理自第 15 届中国数据库技术大会 DTCC 2024 演讲《百度智能云向量数据库创新和应用实践分享》 在 IT 行业,数据库有超过 70 年的历史了。对于快速发展的 IT 行业来说,一个超过 70 年历史的技术,感觉像恐龙一样,非常稀有和少见。 但是数据库之所以有这么长的生命力,核心是在不停的变更和创新。 简单回顾一下数据库的历史,在过去的 70 年里面,数据库一直跟着底层基础设

mhtml图片提取 百度图片下载
如果你需要找一些图片,可以先去百度一下,待相关网页加载完成后,点击保存,即可得到一个mhtml文件。这个文件里的图片会用base64进行存储,只需要找到他们并转化就可以。目前在美篇之类的网站上效果还一般,需要继续排查问题。 效果 代码 大概分为提取所有base64、转化为图片两步。 import base64from io import BytesIOfrom PIL import

使用百度飞桨PaddleOCR进行OCR识别
1、代码及文档 代码:https://github.com/PaddlePaddle/PaddleOCR?tab=readme-ov-file 介绍文档:https://paddlepaddle.github.io/PaddleOCR/ppocr/overview.html 2、依赖安装 在使用过程中需要安装库,可以依据代码运行过程中的提示安装。我使用的为python3.7,安装库为: