本文主要是介绍百度智能云向量数据库创新和应用实践分享,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文整理自第 15 届中国数据库技术大会 DTCC 2024 演讲《百度智能云向量数据库创新和应用实践分享》
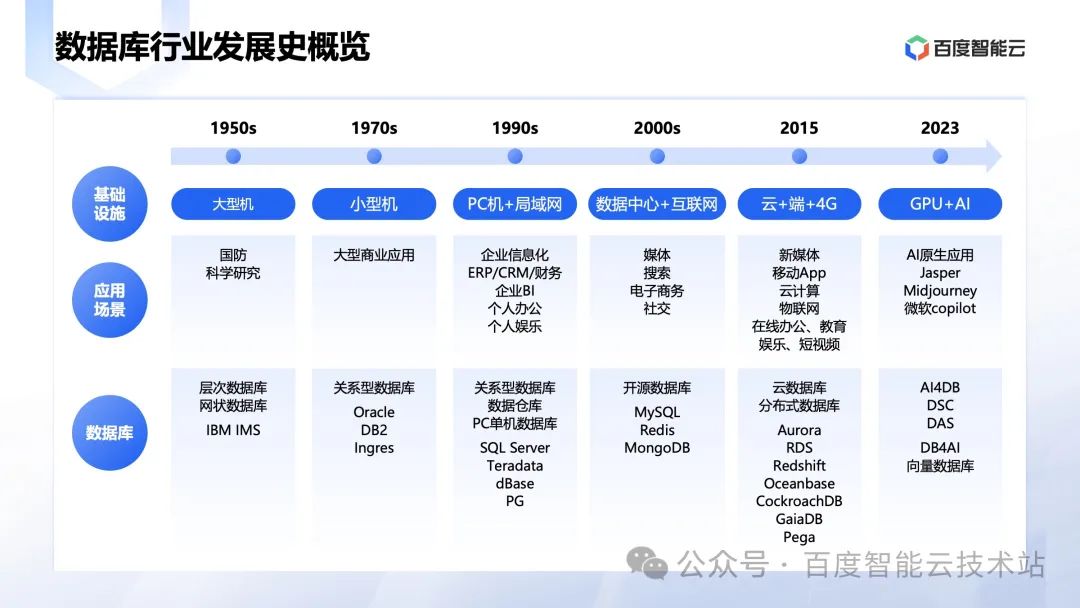
在 IT 行业,数据库有超过 70 年的历史了。对于快速发展的 IT 行业来说,一个超过 70 年历史的技术,感觉像恐龙一样,非常稀有和少见。
但是数据库之所以有这么长的生命力,核心是在不停的变更和创新。
简单回顾一下数据库的历史,在过去的 70 年里面,数据库一直跟着底层基础设施和上层业务的变化的潮流,一直在变化。从最早的大型机再演变到后面的小型机、PC 服务器、数据中心 + 互联网、云、以及现在的 AI 。
数据库在不停地演变和革新,每隔一段时间,新的硬件和新的应用就会催生新的数据库技术。所以每个时代都会有不同的当红数据库。像 PC 时代的 Oracle,互联网时代的 MySQL,云时代的云数据库。到 AI 时代硬件演变成了 GPU + CPU,应用的负载也从 CPU 往 GPU 迁移。在大模型时代,数据库与大模型相互成就。数据库这个领域当前最红的就是向量数据库,以及通过大模型加持的各种智能运维能力。另外,还有一个非常有潜力的方向是大模型数据工程,负责给大模型训练和 AI 原生应用准备数据,提升模型训练效果和加速应用落地。
如果把数据库放到整个 AI 技术栈来看,主要是处在 PaaS 和 SaaS 这一层,向量数据库和数据工程在 PaaS,运维应用在 SaaS 这一层。除了数据之外,还有大模型,以及配套的工具链 Model Builder。为了应用实现的更简单,还有 Agent Builder 和 App Builder 等等。
大模型时代未来帮助客户快速构建大模型相关应用,应用、模型、数据三者缺一不可。前面是模型和应用相关技术栈发展较快,现在工业界的普遍共识是数据技术栈这块欠缺比较多,国内外有大量的投资投向了这个领域。

为什么数据相关技术栈会成为热点,主要是数据和模型是相互相成,不可或缺的。数据平台和大模型相互成就,这个体现在两个方面,一个是大模型成就数据库,另外一个是数据库成就大模型。
大模型表现出理解、生成、推理、记忆四大能力,激发了数据库与 AI 的深度融合,让场景更通用、能力更实用。所以大家看到了把大模型应用到数据平台中可以解决一系列运维,提升易用性的潜力。

另外,大模型效果让人惊艳,但是还是存在知识更新不及时,容易幻觉,没有最新企业的内部知识和数据,无法解决企业真实业务问题,所以带火了 RAG 技术。根据现在调查,目前超过 80% 的落地应用基本都是 RAG。
RAG 是检索增强生成(Retrieval-augmented Generation),利用向量相似度检索技术搜索文档,然后组合成 prompt 喂给大模型,大模型再生成最终的答案。这就规避了刚才讲到的大模型几个典型问题。尤其是 2B 场景里面,缺乏企业自主的数据,企业无法解决企业智能问题。通过向量数据库为主的 RAG 方案是一个比较好的解决大模型数据更新不足的解决方案。

但是要做好 RAG 要经过数据提取、数据索引、检索、生成四个阶段,每个阶段都有不少难点。我这里简单提一下给大家做参考:
首先是数据提取。核心是要把各种结构化,非结构化数据能提取出来,用于后面的处理。这里的复杂度主要是:
- 文件格式复杂,以 pdf 为例子,不光有文字,还夹杂有图表,图片里面又有文字。
- 文件带有上下文信息,要把上文相关的元信息提取出来,后面就更容易处理。如果不提取元信息,那下一步数据分块就容易切分错误。
其次数据索引。这一步做好文档的切分,使用 embedding 模型把文件 embedding 成向量,才可以把向量存到向量数据库里面去。这里的难点又有两个:
- 数据切分,过大或者过小都会有问题。所以一般是按照 300~400 个字节切分。还有处理更精细的,比如按意图切分。
- 另外就是 embedding 模型,文本类的有 BGE, OpenAI 的 text-embedding-3,文图关联的只有 CLIP。现在多模态模型是下一步重点。
然后就是检索。检索主要分 query 预处理,召回两个步骤:
- query 预处理主要的步骤是意图识别、同义词生成、专有名词生成等。
- 召回主要就是向量数据库的工作,要支持向量检索、文本检索、多路召回能力、召回之后重排技术。
最后是生成阶段。检索出来的结果在给大模型之前,还要 prompt 优化,包括 prompt 加上 step by step ,针对场景加上相应的提示词等。
最终的结果依赖大模型的理解,生成,逻辑推理能力。大模型能力的强弱也直接决定 RAG 的效果。
所以大家会看到要把 RAG 作为大模型应用目前主要落地场景,但还是有非常多改进的空间的,这方面的创业公司也很多,技术发展也很快,机会很多。
RAG 技术从业务逻辑上来讲,是对大模型最新的知识的补充,所以 RAG 未来的空间,核心是企业私有化知识到底多不多,有没有用于业务价值的地方。这并不取决于大模型本身能力发展到什么程度,大模型变得多智能。因为大模型再智能也无法获取私有的数据。

在 RAG 里面承担向量召回的能力,业界主要有两个流派,一个是在传统数据库里面支持插件,一个是全新自研一个以向量为场景为主的专用向量数据库。
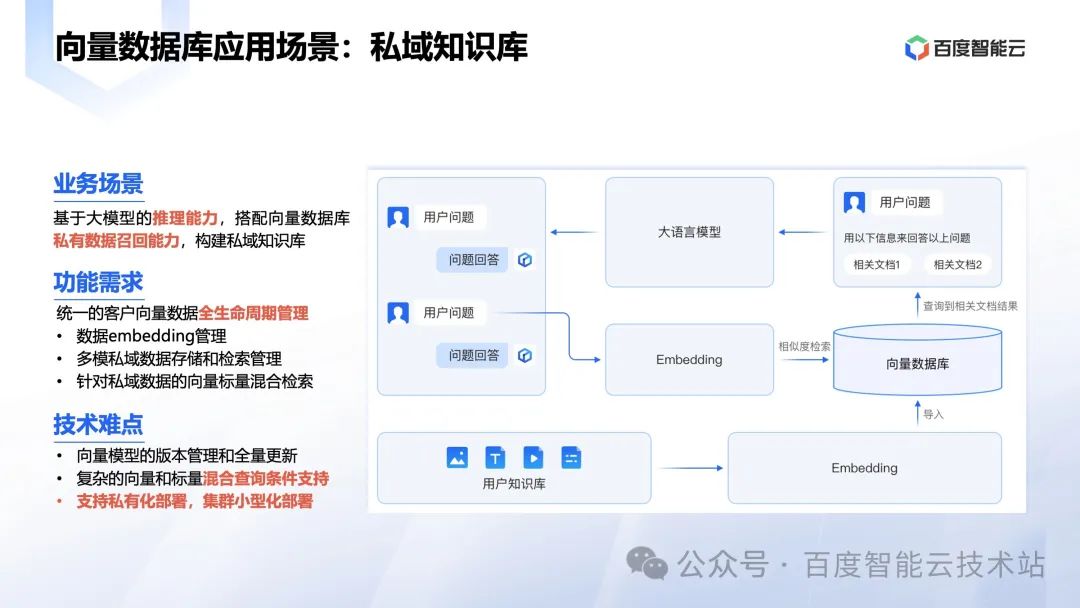
首先我们看场景,RAG 最主要的是私域知识库场景。在这个场景里面,每家企业自己的私有数据通过 embedding 存在向量数据库里面,去做各种业务,比如智能问答,客服等。
每家企业的数据是不一样的,部署的要求是不一样的。因此对向量数据库也有很多要求,需要能支持全生命周期的数据管理能力。技术上有很多关键的点要支持,比如
- 各种版本管理,全量更新能力;
- 复杂的查询,包括标量,向量的混合查询;
- 公有云,私有化的部署,尤其是私有化上一般会有小型化的诉求。
我们还看到很多企业规划统一的知识库,这就要求向量数据库能有很强的扩展性,性价比,在私有化上有多租户的能力等等。我们会看到从客户场景角度,需要的是一个专业全面的能力的数据库,不是一个简单的插件可以完成的。
另外,相比专业的向量数据库,传统向量数据库在系统架构、索引、存储方案上都不是为向量专项设计的,从而导致写入性能,查询时延,并发效率都比较低。是很难满足大模型时代的要求,也是缺乏竞争力的。

我们在实践中看到这些问题,因此选择全新自研百度智能云 AI 原生向量数据库 VectorDB。虽然全新自研难度更高,但是同时带来的天花板也更高。
从架构,存储引擎,计算引擎和平台能力都可以更有针对性的设计,以及取得更好的效果。在今年 6 月份我们正式推出了 1.0 版本。这个也带来很强的产品能力,主要的特点有四个方面:
- 首先是分布式架构。这是向量数据库的基础,分布式架构设计的好坏直接决定向量数据库的天花板,百度智能云向量数据库 VectorDB,支持百亿级的海量的存储,超过 4096 高维向量等。如果是基于传统数据库,不是从底层架构开始考虑,扩展性方面会非常难做。
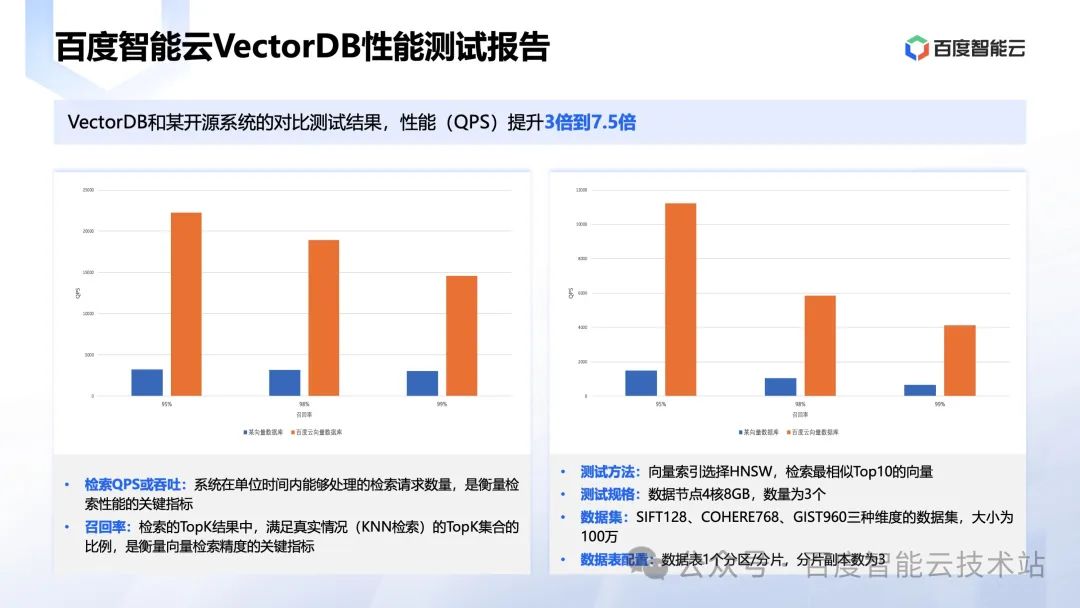
- 第二个是高性能访问。这就需要深度的索引算法优化,目前我们支持比较全的种类开源算法以及我们自研的 puck 算法。性能上,不管是时延,还是QPS 等都相比开源综合下来要高 3~7.5 倍。
- 第三个是全栈的能力和端到端方案。客户需要实现的是一个业务,所以不止向量数据库,是否全套的能力和方案很重要。目前我们支持主流的各种开源框架,结合百度内部的 embedding 库等,实现更好的中文实体和短语的识别等等。
- 最后是企业级能力上,尤其是弹性和高可用能力上做到了一个向量数据库目前业界天花板的水位。
综合来说,选择全新自研这条路,从而带来了一个功能,性能更强大,使用更简单的产品。

接下来深度解析下,百度智能云向量数据库 VectorDB 几个核心技术,这些能力也是一个数据库的核心支柱能力。
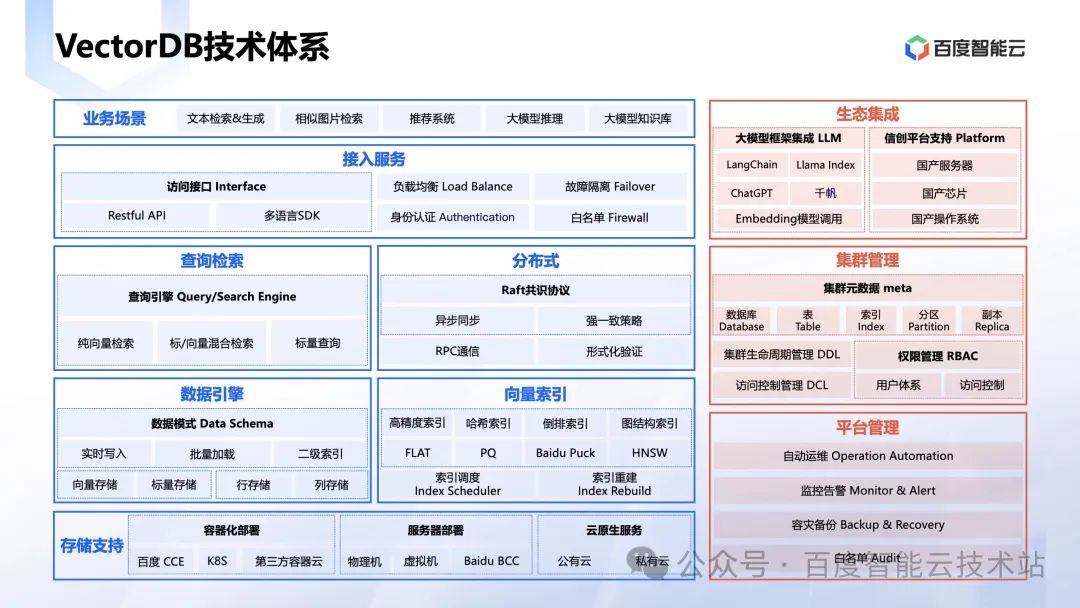
先用一张图来看下整体技术体系,VectorDB 是一个典型的全栈数据库体系,从接入服务、查询索引、数据引擎、分布式能力、向量索引,底层多种存储适配全栈能力,还有配套的生态集成、集群管理、平台管理能力。
熟悉数据库的体系的同学就能知道,只有一个成熟的数据库,具备全栈的能力,才可以各方面都优化的很好,实现一个综合的效果。
VectorDB 有三大核心能力和特点:
首先是成熟的分布式架构。
向量是一个偏 NoSQL 的场景,企业内部的数据可大可小。所以我们利用原来多年积累的存储和数据库分布式经验,在系统的每一层都做到可以扩展:
- 代理节点,这个是无状态对等的,同时支持自动的负载均衡。
- 管理节点,通过 raft 协议做高可用,负责集群的拓扑,资源管理等。
- 数据节点,复杂数据的增删改,查询和索引。支持自动的 failover 和弹性的伸缩能力。
成熟的分布式架构可以说是向量数据库的一切的基石,只有成熟的架构才能很好的支持高可靠、高可用、强扩展、大规模的能力。

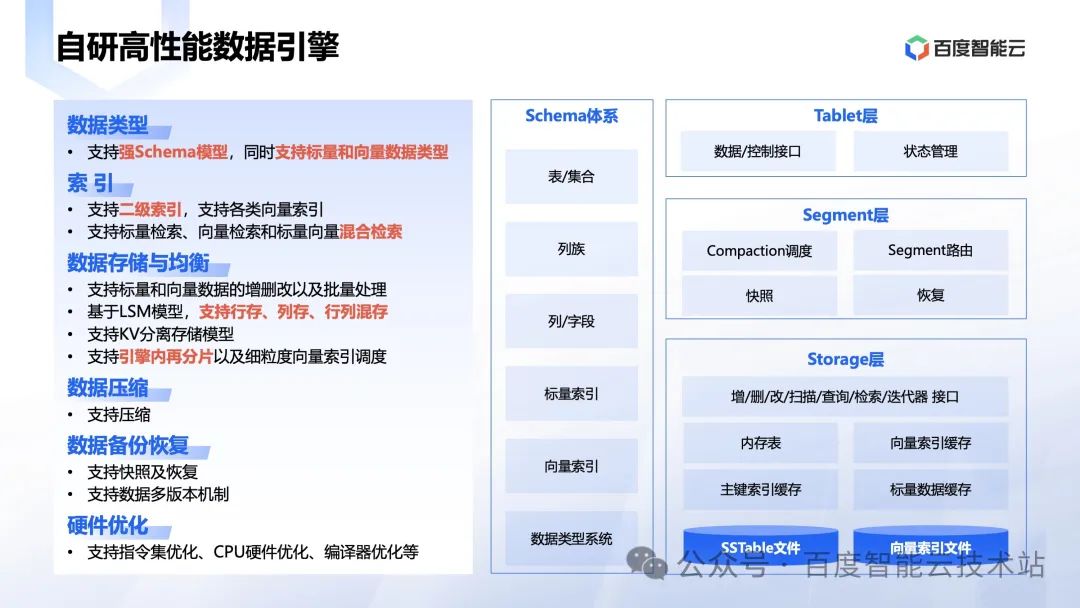
第二个是高性能数据引擎。
VectorDB 的数据引擎逻辑图。最核心的几个能力包括:
- 支持强 schema 模型,同时支持标量和向量数据存储。
- 支持二级索引,支持向量和标量的混合检索能力。
- 支持行存,列存,行列混存多种模式。
- 支持数据压缩能力。
- 具备快照,多版本的恢复能力。
- 能够硬件上充分利用芯片的指令集,编译器的能力,获得很好的性能。
我们通过从底到上,从芯片到架构的深度的优化实现了一个高性能的数据引擎。
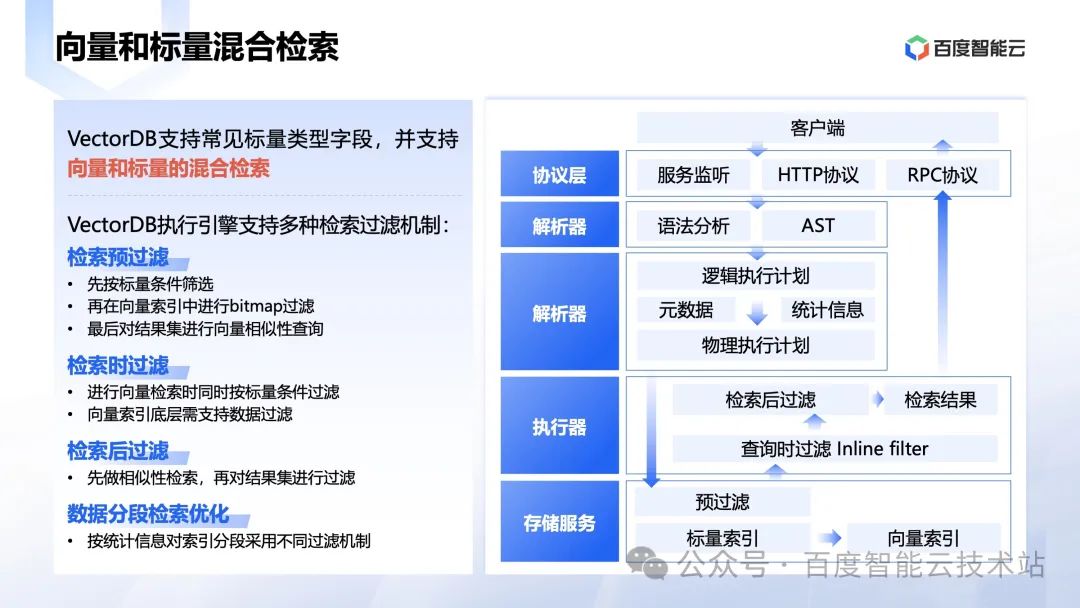
第三个就是强大的检索引擎。
在实践中,经常需要融合文本检索和向量检索的能力。向量解决近似查询,标量解决复杂条件过滤。
要很好的实现这点就要有多种的过滤机制:
- 检索预过滤。
- 检索时过滤。
- 检索后过滤。
- 按统计信息对索引进行不同的过滤机制。
现在看看 VectorDB 和开源的对比结果。
在相同的召回率条件下,VectorDB 整个 QPS 或者吞吐超越开源 3~7.5 倍。关于这个测试报告,大家可以在我们的 VectorDB 产品官网帮助中找到测试的规格、数据、测试代码,整个测试是可以复现。
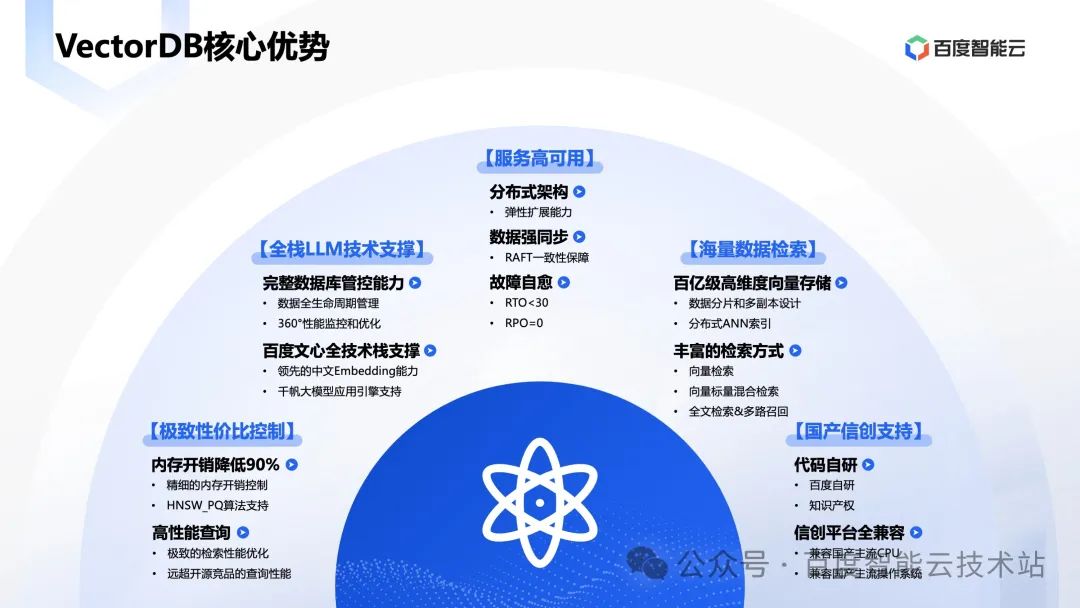
但是通过自研,百度智能云 VectorDB 带来非常强劲的竞争力,包括:
- 远高于竞品的 QPS,以及良好的内存控制。
- 全栈的能力。
- 事务数据库级别的高可用能力。
- 海量数据库存储检索。
- 代码自研,兼容各种平台。
综合来说,百度智能云向量数据库 VectorDB 是一个成熟高效,综合能力领先的向量数据库。
AI 从概念到落地进展还是非常快的,RAG 本身也是个非常成熟的技术。向量数据库 VectorDB 到目前为止服务了大量的客户,简单介绍几个典型的客户代表,以及帮助客户解决的典型问题和收益,给到大家作为参考。
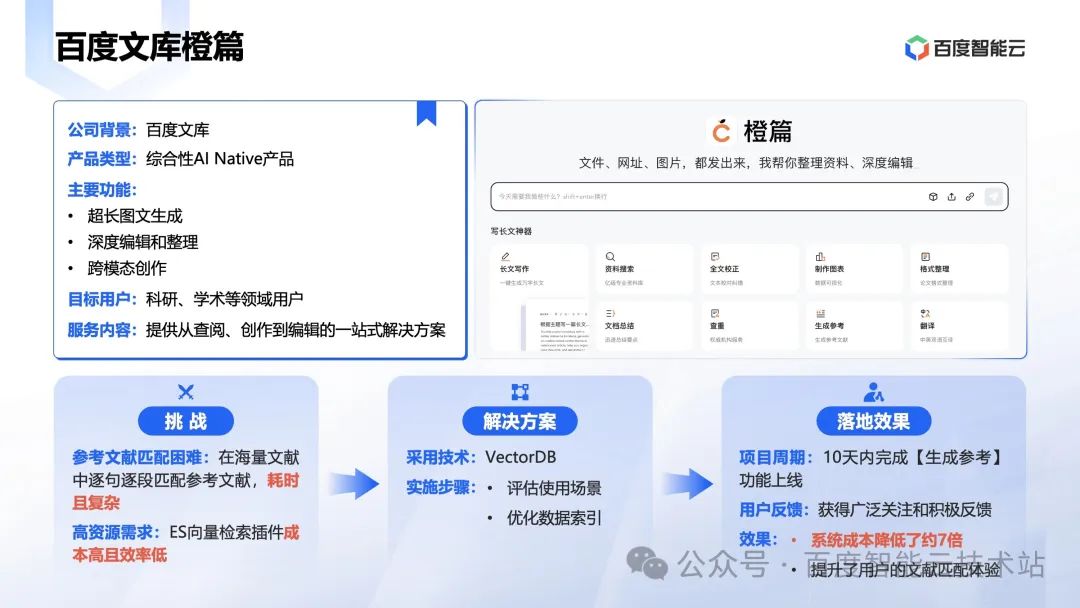
百度文库综合性 AI 产品,拥有大量的科研/学术领域用户,提供从查阅、创作到编辑的一站式解决方案。文库原来使用的开源的 ES 向量插件来构建 RAG 业务。开源的插件成本高且效率低。
通过迁移到向量数据库 VectorDB 系统成本下降了约 7 倍左右。在向量检索这个场景中,存储的是非结构化数据,业务使用的越广泛,需要存储的数据就越多,因此在架构选型的时候,建议更早的预判到未来的业务增量,提前选择一个长期收益都很大的产品。
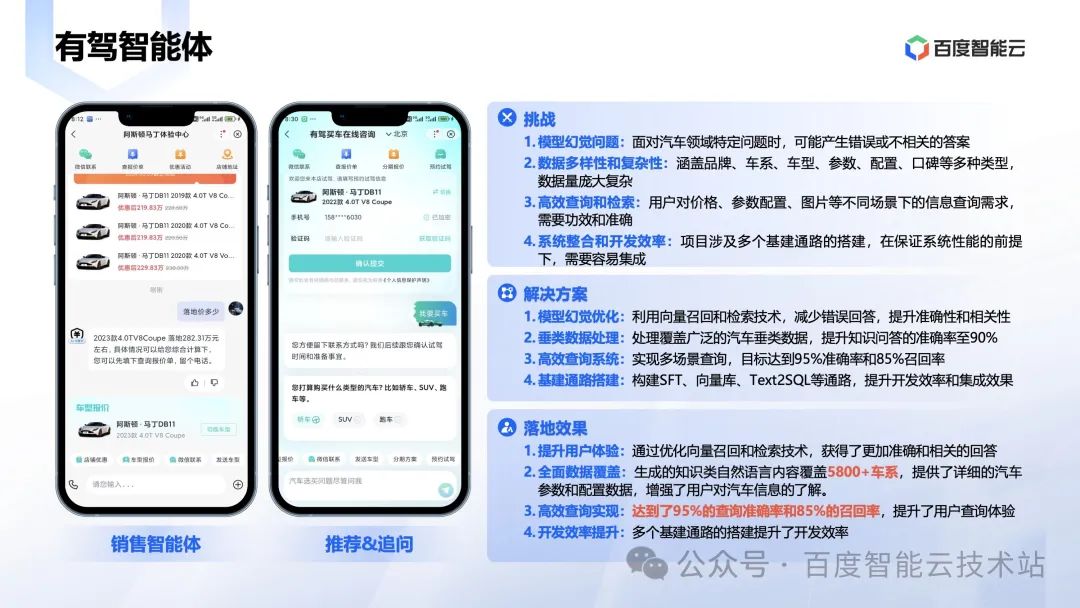
汽车领域有非常多的专业知识,而且更新和变化非常快,大模型在回答这些专业知识是非常困难的,主要体现在:
- 面对汽车领域特定问题时,可能产生错误或不相关的答案。
- 涵盖品牌、车系、车型、参数、配置、口碑等多种类型,数据量庞大复杂。
- 用户对价格、参数配置、图片等不同场景下的信息查询需求,需要功效和准确。
使用向量数据库,通过优化向量召回和检索技术,「有驾智能体」获得了更加准确和相关的回答,最后的效果是非常显著的,体现在:
- 生成的知识类自然语言内容覆盖 5800+ 车系,提供了详细的汽车参数和配置数据,增强了用户对汽车信息的了解。
- 达到了 95% 的查询准确率和 85% 的召回率,提升了用户查询体验。
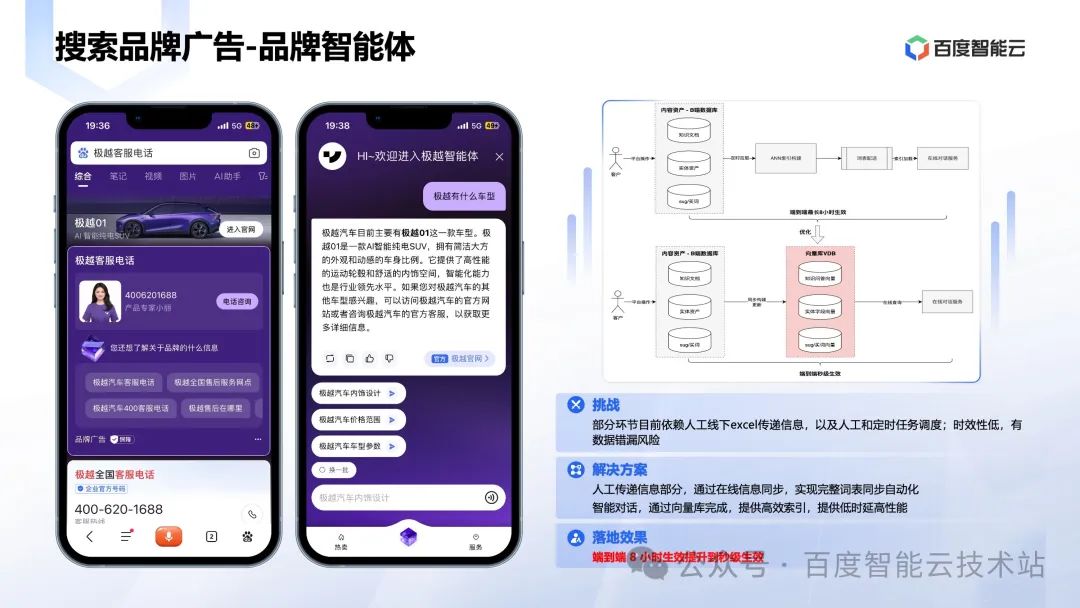
百度移动搜索原来使用的是 ANN 插件,耦合在系统中。这就导致一个问题,部分环节目前依赖人工线下 excel 传递信息,以及人工和定时任务调度。这就导致了时效性低,有数据错漏风险。
通过迁移到向量数据库 VectorDB 中,人工传递信息部分,通过在线信息同步,自动的同步完整词表到向量数据库里面,同时借助向量数据库的高效索引,实现高效的查询。因此在同样条件下,数据发生变化时,之前端到端 8 小时生效提升到现在秒级生效。
非常好的提升了效率和客户满意度。这个 case 核心体现了一个产品不止是实现功能,还要考虑后续数据的变更和运维的便利性,这就对向量数据库的整个数据库导入导出,平台管理能力提出了要求。
通过这些实际案例,我们看到向量数据库通过自身完整、成熟可靠的能力,很好的解决了客户成本问题,并实现复杂业务。
随着大模型能力的越来越强,企业意识到私有化知识的价值越来越大,相信有越来越多的企业会选择相关技术构建对应的业务。
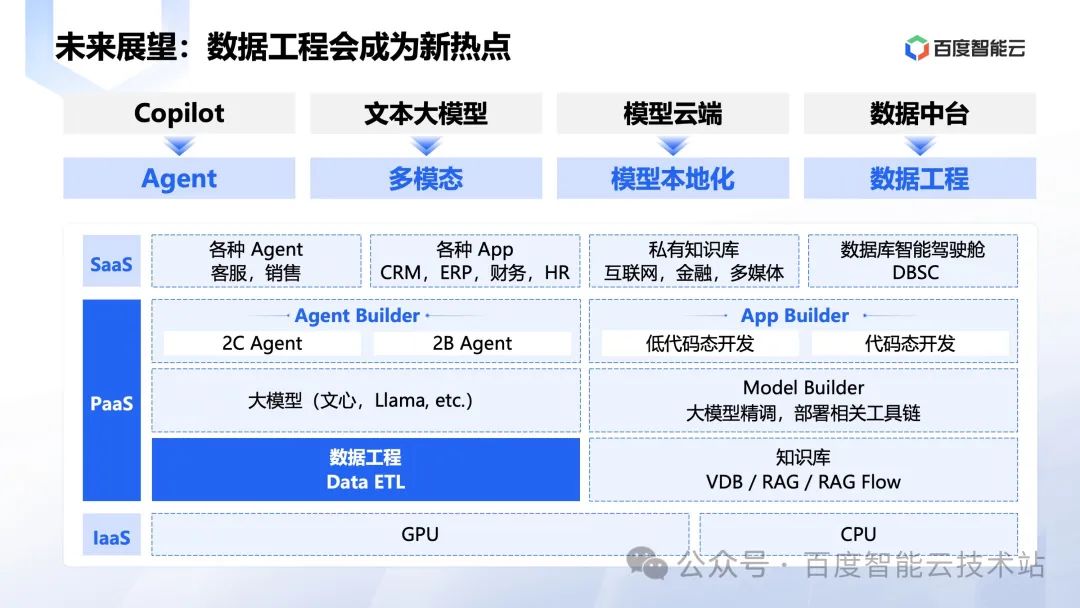
AI 相关技术发展还是相当快的,大模型和整个数据平台(包括数据库和大数据)会持续结合。我们也看到了很多新的趋势,从底层的 IaaS,模型会从云端扩展到端,PaaS 会从现在纯文本模型扩展到多模态,上层应用会从当前主流的 Copilot 扩展到 Agent,更充分利用大模型的自主决策能力。
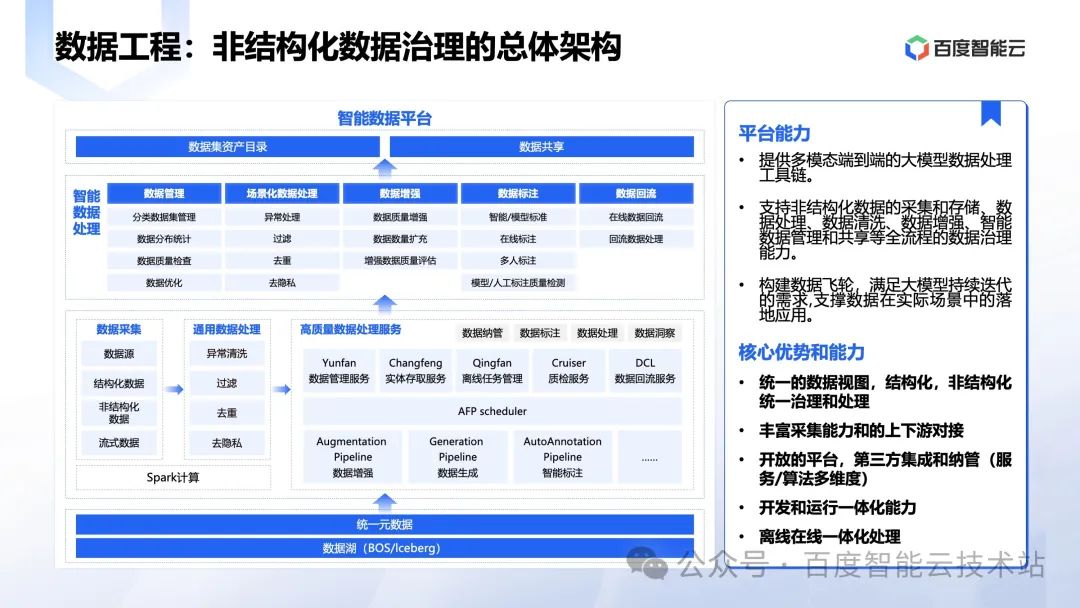
另外,数据领域我们观察到一个非常重要的趋势,那就是在大数据领域,传统数据中台会从单纯结构化数据治理扩展到数据工程,这个未来会帮助客户解决一系列问题:
- 提供多模态端到端的大模型数据处理工具链。
- 支持非结构化数据的采集和存储、数据处理、数据清洗、数据增强、智能数据管理和共享等全流程的数据治理能力。
- 构建数据飞轮,满足大模型持续迭代的需求,支撑数据在实际场景中的落地应用。
应该说,大模型时代,数据相关技术栈还有很多优化的空间,数据相关技术发展正当其时!
这篇关于百度智能云向量数据库创新和应用实践分享的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



