本文主要是介绍Spark Streaming中,增大任务并发度的方法有哪些?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Spark Streaming中,增大任务并发度的方法有哪些?
0 准备阶段
Q: 在Spark集群中,集群的节点个数、RDD分区个数、CPU内核个数三者与并行度的关系是什么?
我们先梳理一下Spark中关于并发度涉及的几个概念: File, Block, Split, Task, Partition, RDD以及节点数、Executor数、core数目的关系。
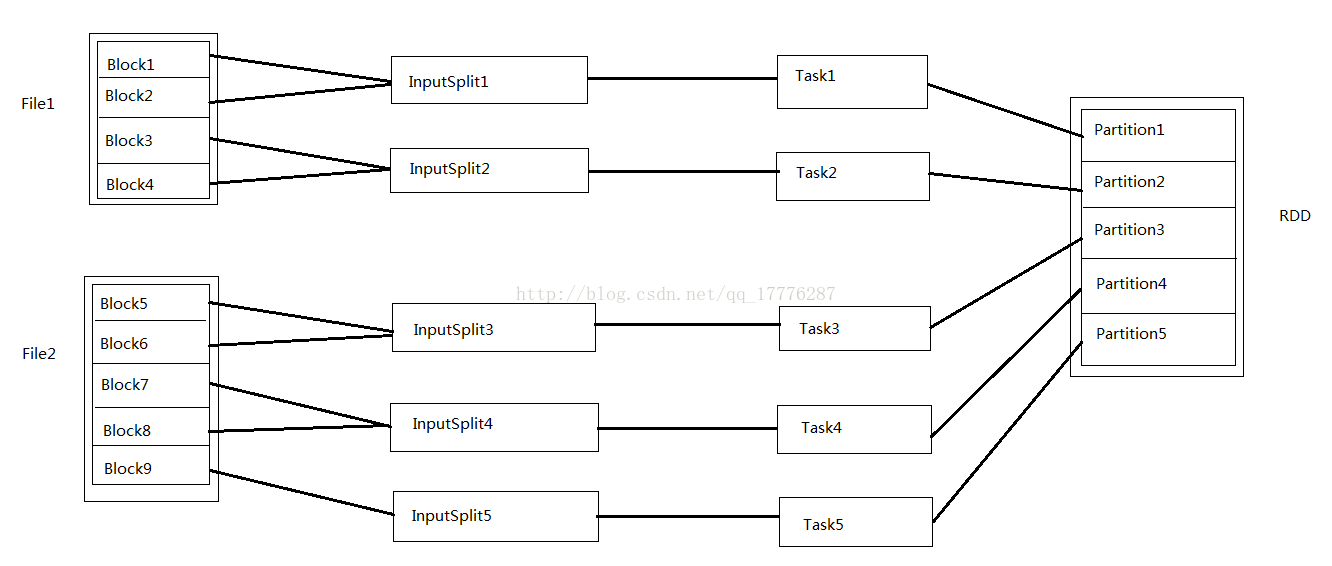
- 输入可能以多个文件的形式存储在HDFS上,每个File都包括了很多Block。
- 当Spark读取这些文件作为输入时,会根据具体数据格式对应的InputFormat进行解析,一般是将若干个Block合并成一个输入分片(InputSplit),注意InputSplit不能跨越文件。
- 随后将为这些输入分片生成具体的Task。InputSplit与Task是一一对应的关系。
- 这些具体的Task,每个都会被分配到集群上的某个节点的某个Executor去执行。
- 每个节点可以起一个或多个Executor。
- 每个Executor由若干core组成,每个Executor的每个core一次只能执行一个Task。
- 每个Task执行的结果就是生成了目标RDD的一个partition。
Note:
这里的core是虚拟的core而不是机器的物理CPU核,可以理解为Executor的一个工作线程。
而 Task被执行的并发度 = Executor数目 * 每个Executor核数
至于partition的数目:
- 对于数据读入阶段,例如: sc.textFile,输入文件被划分为多少InputSplit就会需要多少初始Task。
- 在Map阶段,partition数目保持不变。
- 在Reduce阶段,RDD的聚合会出发shuffle操作,聚合后的RDD的partition数目跟具体操作有关。例如:repartition操作会聚合成指定分区数,还有一些算子是可配置的。
1 Spark Streaming增大任务并发度
Q: 在Spark Streaming中,增大任务并发度的方法有哪些?
A: s1 core的个数: task线程数,也就是--executor-cores
s2 repartition
s3 Streaming + Kafka,Direct方式,则增加partition分区数
s4 Streaming + Kafka,Receiver方式,则增加Receiver个数
s5 reduceByKey和reduceByKeyAndWindow传入第二个参数
1.1 解析
s1 & s2:
RDD在计算的时候,每个分区都会起一个task,所以RDD的分区数目决定了总的task数据。
申请的计算节点(Executor)数目和每个计算节点核数,决定了你同一时刻可以并行执行的task。
e g:
RDD有100个分区,那么计算的时候就会生成100个task,你的资源配置为10个计算节点,每个2个核,同一时刻可以并行的task数目为20,计算这个RDD就需要5个轮次。
如果计算资源不变,你有101个task的话,就需要6个轮次,在最后一轮中,只有一个task在执行,其余核都在空转。
如果资源不变,你的RDD只有两个分区,那么同一时刻只有2个task运行,其余18个核空转,造成资源浪费。
这就是在Spark调优中,通过增大RDD分区数目,进而增大任务并行度的做法。
s5:
如果在计算的任何stage中使用的并行task的数量没有足够多,那么集群资源是无法被充分利用的。举例来说,对于分布式的reduce操作,比如reduceByKey和reduceByKeyAndWindow,默认的并行task的数量是由spark.default.parallelism参数决定的。你可以在reduceByKey等操作中,传入第二个参数,手动指定该操作的并行度,也可以调节全局的spark.default.parallelism参数。
1.2 增大kafka中的partition可以增加Spark在处理数据上的并行度吗?
s4:
在Receiver的方式中,Spark中的partition和Kafka中的partition并不是相关的,所以如果我们加大每个topic的partition数量,仅仅是增加线程来处理由单一Receiver消费的主题。但是这并没有增加Spark在处理数据上的并行度。但是,该方式下,一个Receiver就对应于一个partition,所以,可以通过增加Receiver的个数来增大Spark任务并行度。
s3:
而在Direct方式中,Kafka中的partition与RDD中的partition是一一对应的并行读取Kafka数据,这种映射关系也更利于理解和优化。
Reference Link
[1] Spark Streaming和Kafka整合开发指南(一): https://www.iteblog.com/archives/1322.html
[2] Spark Streaming和Kafka整合开发指南(二):https://www.iteblog.com/archives/1326.html
[3] Spark Streaming性能调优详解: https://www.cnblogs.com/gaopeng527/p/4961701.html
[4] Spark Streaming:性能调优 http://blog.csdn.net/kwu_ganymede/article/details/50577920
[5] Spark踩坑记 —— Spark Streaming + Kafka https://www.cnblogs.com/xlturing/p/6246538.html
这篇关于Spark Streaming中,增大任务并发度的方法有哪些?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





