本文主要是介绍数栈数据中台专栏(一) :浅析数据中台策略与建设实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

本文作者:张旭
袋鼠云合伙人、技术总监、数据中台事业部副总经理,花名:老虎。在袋鼠云工作期间,深入了解客户需求,负责多个大数据项目的落地实施,如贵州茅台、新华书店、轻松筹、贵州交警等等,对于企业应用大数据的痛点具有清晰的了解和丰富的实践经验。
数据中台是什么?
数据中台建设的价值在哪里?
数据中台和传统数仓还有数据中心有什么区别?
这几乎是笔者最近被别人问到的最多的问题。之所以有这些疑问,其一是不懂的同学真心想了解,其二是懂的同学对我们的考验。
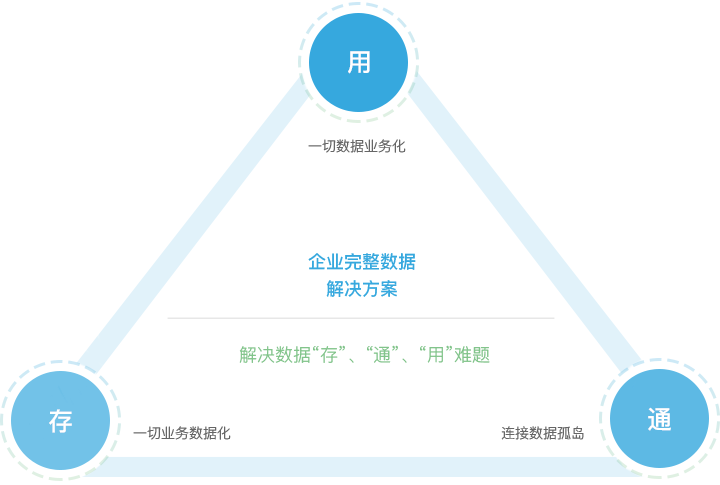
数据中台,解决数据“存”、“通”、“用”难题
让一切业务数据化,一切数据业务化
具体而说,数据中台并不是一个跨时代的全新理念,就好比笔者当年学习SOA一样,发现其实质还是组件化,模块化,是设计模式与业务端的应用。数据中台建设的基础还是数据仓库和数据中心,并且在数仓模型的设计上也是一脉传承,之所以我们现在处处推崇数据中台建设及应用,一个是因为数据中台确实有过人之处,另一个是这套模型在阿里体现了巨大的应用价值。
首先先总结一下数据中台策略中的几个过人之处
第一:数据汇聚,承上启下。
数据中台策略的基本理念是,将所有的数据汇聚到数据中台,以后的每个数据应用(无论是指标和分析类的,还是画像类和大数据类的)统统从数据中台获取数据,如果数据中台没有,那么数据中台就负责把数据找来,如果数据中台找不来,就说明当前真没有这个数据,数据应用也就无从展开。
按照这种模式,如果企业中数据应用数量大于3-5个,那么数据中台将整体上节约30%的成本,随着数据应用的增长,这样节约的成本还会更大。传统的数据仓库和数据中心,如果做得比较好,设计到位的话,也会做完整的数据模型设计,但是往往偏重于设计和技术,在执行的过程中,很难保障数据的全,也很难保证数据应用不跨过数据中心,重新做数据的话,那么后期数据则会比较混乱。
相对而言,数据中台策略中更加强调数据的“全”以及数据中台组织与数据应用组织之间的协作关系,从设计、组织、建设、流程角度保障了模式的落地。
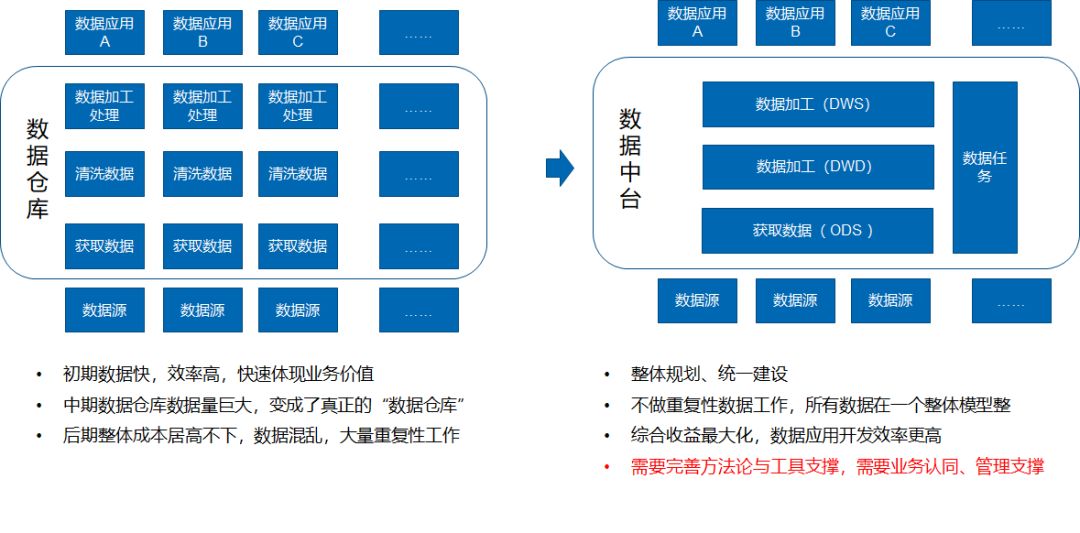 袋鼠云数据中台策略
袋鼠云数据中台策略
第二:纵观大局,推动全局
数据业务在企业中应当是一个完整业务,是一个亟需提高定位的业务,是企业的战略业务。
所以数据中台策略应当对应企业的数据战略,并提供更有力的支撑,而不是仅仅停留在把数据找到,把数据清洗,把数据算出来。
所以,构建数据中台建设,需要详实了解企业的数据情况,数据需求以及构建数据业务的推动蓝图。
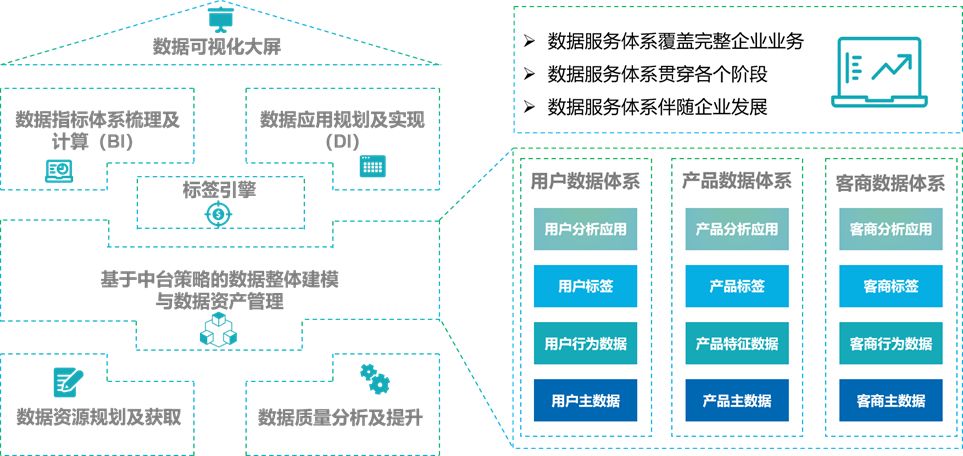
上述内容应当通过相互衔接的七个数据服务进行完整的构建以及推动。
袋鼠云数据中台七大数据服务
-
数据资源规划及获取
盘点数据资源、规划数据资源、获取数据资源,并将所有数据资源进行完整呈现;
-
数据质量分析及提升
从基础数据、业务数据、大数据视角综合分析当前的数据质量问题;
-
基于中台策略的数据整体建模与数据资产管理
企业可根据数据资源规划报告指导后续数据治理和数据资产管理平台的建设,最终服务于企业数据应用场景。
-
实体画像及标签引擎
对用户、产品、客商、营销各主题域进行标签提取,将其特征数字化,为后续进行精准 营销和用户画像提供必要条件。
-
数据指标体系梳理及计算(BI)
构建企业标签体系,着重分析当前需要但是无法获取到的指标,描述使用不便的指标,分析问题原因,绘制数据供应链条;
-
数据应用规划及实现(DI)
基于当前外部数据、IOT数据、非结构和半结构化数据进行大数据应用的规划,并论证实现过程和进行成本评估。一旦评估通过可以帮助企业进行大数据应用的完整开发和落地。
-
数据可视化大屏
数据可视化大屏,讲述数据背后的价值。在最短的时间内用最具冲击力的视觉语言,将企业最重要的数据/信息传递给最重要的人。
袋鼠云数据中台七大数据服务
通过上述服务内容,希望将企业数据资源情况完整展现,数据问题展现,数据资产情况展现,数据需求展现(传统数据分析方面、大数据应用方面)从而绘制一张完整的数据供应链地图,最终利用这张地图,辅助数据业务推进。
第三:技术升级、应用便捷
大数据平台在很长一段时间,甚至直至现在都还是以开源产品为主流的状况,开源产品使用费力,配置繁琐,导致大数据开发门槛高,数据应用受到严重阻碍,甚至在很多地方一直把大数据技术平台和传统的数仓做区别对待,认为大数据产品的特点是流式计算和处理非结构化数据。
其实大数据产品如果能够降低使用门槛的话,会迅速替代传统数仓的技术产品。传统数仓无论在海量数据处理能力,节点扩展能力,实时计算能力,软件购买和维护成本等诸多方面都无法与当前的大数据平台进行抗衡。
目前业内比较典型的就是阿里云数加平台,数加平台基本让数据开发者能够像使用传统数据库一样的使用大数据平台了,所有操作方式都是通过可视化界面进行,大部分的开发都是通过SQL语句来实现。当笔者使用数加产品时,总是回想起第一次使用java IDE(JBuild、Eclipse) 产品时的感受。
袋鼠云数据中台产品(数栈)客观的说则是一款轻量化的,可私有部署的类数加产品,用以解决基于私有云的大数据平台的管理和开发问题。
数据中台产品在与数加产品功能对比上不分伯仲,同时又基于私有云大数据应用的特点定制开发了诸多功能以及数据治理模块用以推动企业整体数据化进程。
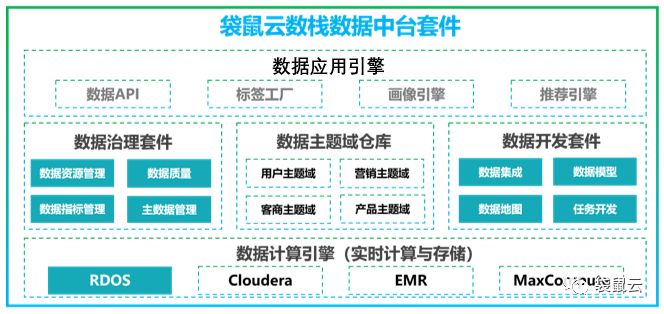
袋鼠云数栈产品体系
袋鼠云数栈产品一览
袋鼠云数据中台建设与策略已经脱离了一个单纯的产品概念范畴,更多的是关注于企业的整体数据化建设工作,希望通过数栈产品和七大数据服务贴身参与用户全方位与全过程的数据化建设。同时我们期待这样的数据化建设应当是高效率,高应用价值和低成本的。
本文声明:
本文首发于数栈公众号:数栈研习社
我们拥有一群一起在钉钉群交流的小伙伴:袋鼠云开源框架技术交流群(30537511)
数栈还在github有一个开源项目:flinkx,欢迎大家一起交流~
这篇关于数栈数据中台专栏(一) :浅析数据中台策略与建设实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


