本文主要是介绍房天下房源爬取:scrapy-redis分布式爬虫(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
从前几天就开始准备写一个简单地分布式爬虫的项目了,今天算是把问题和bug逐渐解决了,所以会陆续放上来。
主机是windows即此电脑,项目也是在windows下写的,运行会放在linux下的ubuntu系统。
项目是爬取房天下网站全国600多个城市的所有新房和二手房信息
今天主要记录一下windows下项目的完成,和数据库存储。新房存储在MySQL数据库,二手房存储在mongo数据库。
这个网站没有反爬,我们这里还是用一下中间件,设置随机请求头
创建的是基础爬虫,不是通用爬虫,代码如下:
fang.py:开始爬虫与提取信息
# -*- coding: utf-8 -*-
import scrapy
import re
from fangtianxia.items import NewHouseItem,ESFHouseItemclass FangSpider(scrapy.Spider):name = 'fang'allowed_domains = ['fang.com']start_urls = ['https://www.fang.com/SoufunFamily.htm']def parse(self, response):#所有的城市链接都在td标签中#td标签包含在tr标签中#每一行的tr标签,从第3个开始是包含城市链接的td标签#获取所有的tr标签#过滤掉中国的港澳台,和国外房源[0:-2]trs = response.xpath("//div[@class='outCont']//tr")[0:-2]#遍历所有的tr标签for tr in trs:#找到所有的td表标签tds = tr.xpath(".//td[not(@class)]")#这里过滤掉了含有class属性的td标签#所以包含城市链接和名字的td标签是第二项city_td = tds[1]#找到所有的参数的链接的a标签city_links = city_td.xpath(".//a")#遍历所有的城市链接for city_link in city_links:#链接内的文本信息即城市名称city = city_link.xpath(".//text()").get()#href属性即链接city_url = city_link.xpath(".//@href").get()# print(city,city_url)#构造新房和二手房的链接#北京的url特殊处理if "bj." in city_url:#北京新房链接newhouse_url = "https://newhouse.fang.com/"#北京二手房链接esf_url = "https://esf.fang.com/"else:#用split方法以“.”分割url#如“http://cq.fang.com/”#分割成“http://cq”和“fang”和“com/”url_s = city_url.split(".")first = url_s[0]second = url_s[1]last = url_s[2]#新房链接newhouse_url = first + ".newhouse." + second + "." + last#二手房链接esf_url = first + ".esf." + second + "." + last# print(city)# print(newhouse_url)# print(esf_url)#把新房,二手房链接传给解析函数处理。提取信息,并把城市名传过去yield scrapy.Request(url=newhouse_url,callback=self.parse_newhouse,meta={"info":(city)})yield scrapy.Request(url=esf_url, callback=self.parse_esf,meta={"info": (city)})# break# breakdef parse_newhouse(self,response):city = response.meta.get('info')# print(city)#包含一页的div下的li标签包含房源信息#获取所有li标签,遍历处理lis = response.xpath("//div[@class='nhouse_list']//li")for li in lis:#判断该li标签是不是广告。#是广告的li标签含有h3标签,以此过滤is_gg = li.xpath(".//div[@class='clearfix']/h3")if is_gg:continueelse:#获取小区名字name = li.xpath(".//div[@class='nlcd_name']/a/text()").get()#使用正则表达式去除空白name = re.sub(r"\s","",name)# print(name)#获取居室rooms = "".join(li.xpath(".//div[contains(@class,'house_type')]//a/text()").getall())rooms = re.sub(r"\s", "", rooms)# print(rooms)#获取面积area = "".join(li.xpath(".//div[contains(@class,'house_type')]/text()").getall())area = re.sub(r"\s|/|-", "", area)# print(area)# 获取位置#为避免获取信息不全,直接获取title属性address = li.xpath(".//div[@class='address']/a/@title").get()address = re.sub(r"\s|\[|\]", "", address)# print(address)#待售或在售sale = li.xpath(".//div[contains(@class,'fangyuan')]/span/text()").get()# print(sale)#价格price = "".join(li.xpath(".//div[@class='nhouse_price']//text()").getall())price = re.sub(r"\s|广告", "", price)# print(price)#获取行政区#有些小区信息未正常给出行政区名称,导致没有span标签,在此过滤,不获取该小区信息is_span = li.xpath(".//div[@class='address']//span")if not is_span:continuedistrict = li.xpath(".//div[@class='address']//span[@class='sngrey']/text()").get()#[]是特殊符号,需要转义district = re.sub(r"\s|\[|\]", "", district)# print(district)item = NewHouseItem(city=city,name=name,rooms=rooms,area=area,address=address,price=price,sale=sale,district=district)# print(item)yield item#判断是否有下一页,有则继续获取next_page = response.xpath("//a[@class='next']/@href").get()# print(next_page)if next_page:yield scrapy.Request(url=response.urljoin(next_page),callback=self.parse_newhouse,meta={"info":(city)})def parse_esf(self,response):city = response.meta.get('info')# print(city)# 所有的信息列表存放在dl标签中dls = response.xpath("//dl[@class='clearfix']")for dl in dls:#判断是不是广告is_gg = dl.xpath(".//h3")if is_gg:continueelse:#获取小区名name = dl.xpath(".//p[@class='add_shop']/a/@title").get()# print(name)# 地址address = dl.xpath(".//p[@class='add_shop']//span/text()").get()# print(address)# 价格price = "".join(dl.xpath(".//dd[@class='price_right']//span[@class='red']//text()").getall())# print(price)# 独栋或居室,朝向,面积等详细信息info = "".join(dl.xpath(".//p[@class='tel_shop']//text()").getall())info = re.sub(r"\s","",info)# print(info)item = ESFHouseItem(city=city,name=name,address=address,price=price,info=info)# print(item)yield itemnext_page = response.xpath("//div[@class='page_al']/p/a/@href").get()if next_page:yield scrapy.Request(url=response.urljoin(next_page),callback=self.parse_esf,meta={"info":(city)})
注释和测试代码都很详细,供参考。
item.py:
import scrapyclass NewHouseItem(scrapy.Item):#城市city = scrapy.Field()#小区名字name = scrapy.Field()#居室rooms = scrapy.Field()#面积area = scrapy.Field()#行政区district = scrapy.Field()#位置address = scrapy.Field()#待售或在售sale = scrapy.Field()#价格price = scrapy.Field()class ESFHouseItem(scrapy.Item):#城市city = scrapy.Field()#小区name = scrapy.Field()#地址address = scrapy.Field()#价格price = scrapy.Field()#独栋或居室,朝向,面积,出售人等详细信息info = scrapy.Field()
middlewares.py:仅用于设置随机请求头,由于网站无反爬,可不写
import randomclass UserAgentDownloadMiddleware(object):User_Agents = ['Mozilla/5.0 (X11; Linux i686; rv:64.0) Gecko/20100101 Firefox/64.0','Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.13; ko; rv:1.9.1b2) Gecko/2008''1201 Firefox/60.0','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'' Chrome/70.0.3538.77 Safari/537.36','Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML like Gecko) Chrome''/44.0.2403.155 Safari/537.36',]def process_request(self, request, spider):user_agent = random.choice(self.User_Agents)request.headers['User-Agent'] = user_agentpiplines.py:这里写了两个piplines,一个用于把新房信息存储到MySQL,一个用于把二手房存储mongo
import pymysql
import pymongo
from fangtianxia.items import NewHouseItem,ESFHouseItemclass NewhouseSQLPipeline(object):def __init__(self):self.db = pymysql.connect(host='localhost', port=3306, user='root',password='123',db='fangtianxia',charset='utf8')self.cursor = self.db.cursor()def process_item(self, item, spider):sql = """insert into newhouse(id,city,name,rooms,area,district,address,sale,price) values(null,%s,%s,%s,%s,%s,%s,%s,%s)"""#判断是否为新房的item,是就储存if isinstance(item, NewHouseItem):try:self.cursor.execute(sql,(item['city'],item['name'],item['rooms'],item['area'],item['district'],item['address'],item['sale'],item['price']))self.db.commit()print("SQL存储成功")except pymysql.Error as e:print("ERROR:", e.args)return itemclass EsfMONGOPipeline(object):def __init__(self,mongo_uri,mongo_db):self.mongo_uri = mongo_uriself.mongo_db = mongo_db@classmethoddef from_crawler(cls,crawler):return cls(mongo_uri=crawler.settings.get("MONGO_URI"),mongo_db=crawler.settings.get("MONGO_DB"))def open_spider(self,spider):self.client = pymongo.MongoClient(self.mongo_uri)self.db = self.client[self.mongo_db]def process_item(self, item, spider):name = item.__class__.__name__if isinstance(item, ESFHouseItem):try:self.db[name].insert(dict(item))print("MONGO存储成功")return itemexcept Exception as e:print("ERROR",e.args)def close_spider(self,spider):self.client.close()settings.py:
关闭协议:
ROBOTSTXT_OBEY = False
打开延迟:
DOWNLOAD_DELAY = 3
默认请求头信息:
DEFAULT_REQUEST_HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'en',
}
下载中间件:
DOWNLOADER_MIDDLEWARES = {'fangtianxia.middlewares.UserAgentDownloadMiddleware': 543,
}
piplines:
ITEM_PIPELINES = {'fangtianxia.pipelines.NewhouseSQLPipeline': 300,'fangtianxia.pipelines.EsfMONGOPipeline': 100,
}
MONGO_URI='localhost'
MONGO_DB='fangtianxia'
最后把start.py写一下就可以运行了。
这里需要说明一下,优先级高即数字小的piplines全部运行完,才会运行优先级低的piplines。
比如上面的,mongo储存完才会储存mysql
数据库:
MySQL:
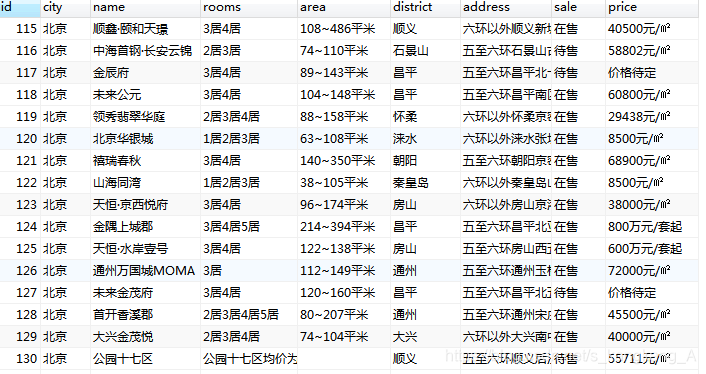
MonGo:
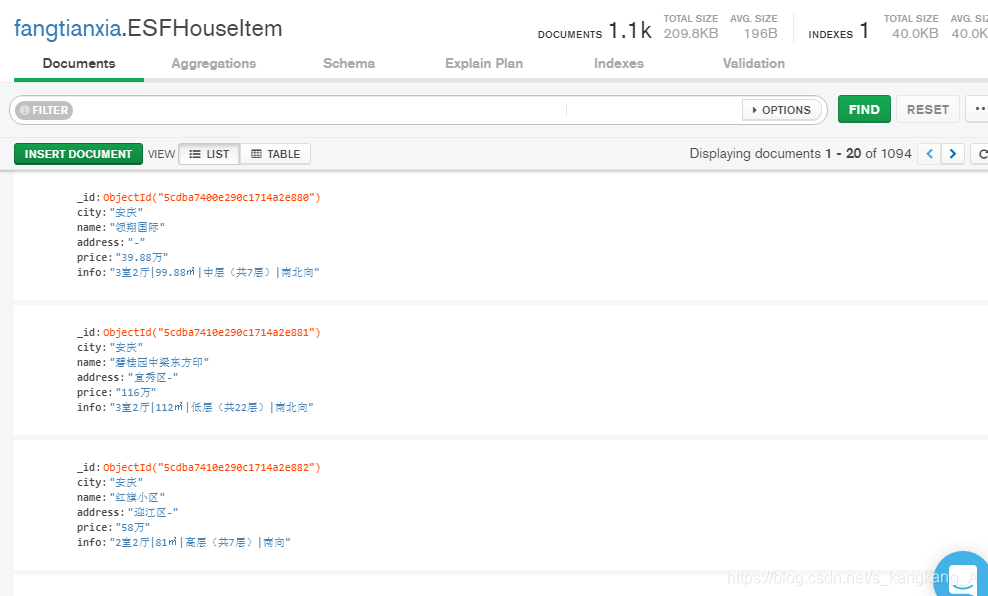
后续把它变成分布式爬虫的项目最近就会写上来。
这篇关于房天下房源爬取:scrapy-redis分布式爬虫(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






