本文主要是介绍怎样做一道阿尔法贝塔剪枝的题(图解),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在前边
- 现在的时间:2019-06-20
- 不讨论原理,不说为什么,只讲怎么做这道题.
- 上学期就是说要考这个,结果没考,这学期又说要考,不知道考不考.记下来,万一再说下学期考呢.
概念与做题依据
概念:MIN层与MAX层
- 从非叶子节点开始,从下往上,我们依次轮流把每一层称为
MIN层、MAX层 - 例如下边这棵树
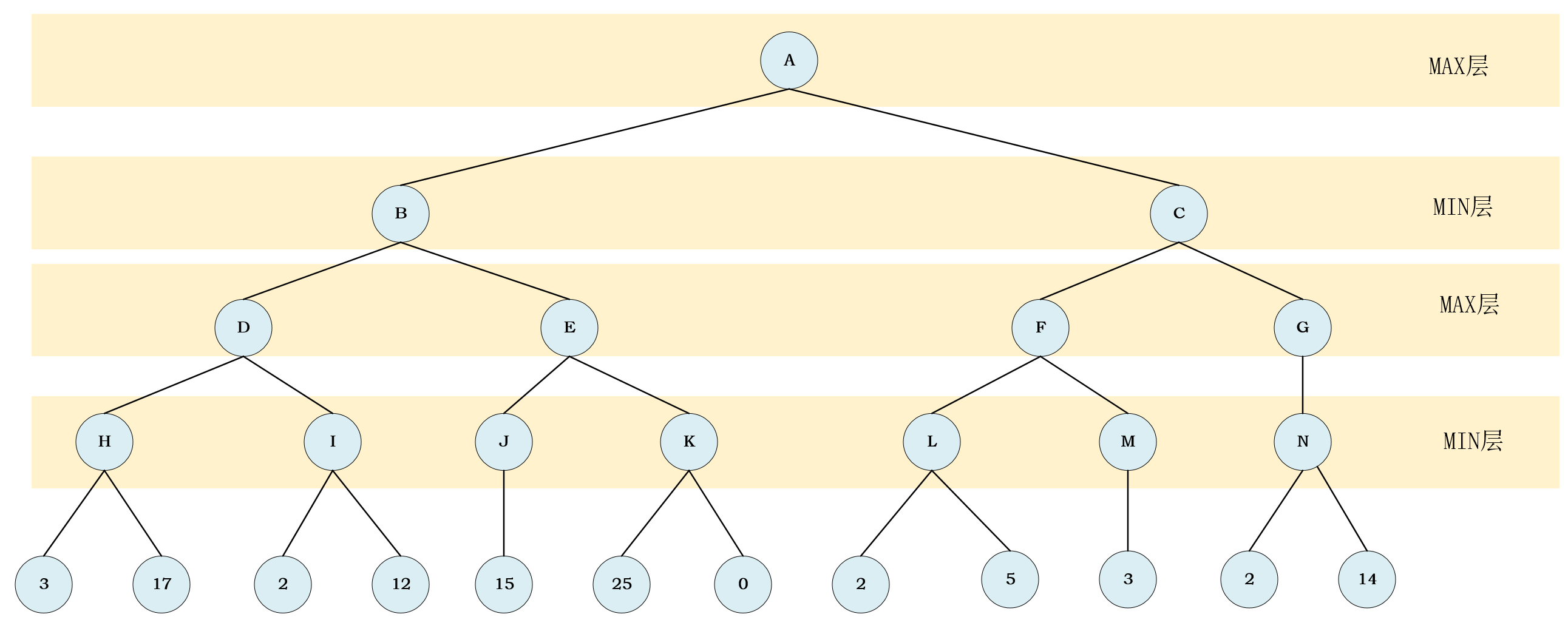
做题依据
- 树要从倒数第二层开始处理,且所有的处理都要"从左往右"处理
MIN层节点的取值是其子节点中的最小值,如果有子节点被剪了,那么就取剩下的子节点中的最小值.MAX层节点的取值是其子节点中的最大值,如果有子节点被剪了,那么就取剩下的子节点中的最大值.- 下边个依据不好表达也不太好理解,我多写几句,现在理解不了等看了后边的例子就能理解了,这条依据也是我们能够剪枝的依据,满足这条依据才可以剪枝.
- 假设有
节点x,根据节点x的某个子节点确定了节点x的取值范围. - 节点x也有父节点(包括直接父节点与间接父节点),这些父节点在你确定节点x的值时,可能已经有了取值范围,也可能还没有取值范围.
- 如果这些父节点已经有取值范围了,那么,如果节点x的聚值范围与节点x的父节点(直接或间接)的取值范围没有交集或交集中只有一个元素,则剪掉节点x的其他子节点,
其他子节点指的就是节点x的所有子节点中除推出节点x范围的那个节点外的节点.
- 假设有
- 当所有未被剪掉的节点的值都确定后,剪枝结束,题也就做完了.
例子
所要剪的树

开始做题
- 因为要从倒数第二层开始处理,且所有的处理都要"从左往右"处理,所以要先处理
节点H. 节点H处于MIN层,所以要取子结点的最小值.- 因为要从左往右处理所以先看
叶子节点3,因为它的值为3所以,当我们看完3时,确定节点H的取值范围为(-∞,3]

- 这时还不能确
节点H的最小值,还需要看它的第二个子节点,第二个子节点的值是17,比3大,也就最终确定节点H的值是3. - 且根据
节点H的值是3我们可以确定节点D的取值是[3,+∞),因为D位于MAX层,要取最大值,已经知道一个节点是3了,那么最小不可能小于3.

- 然后处理
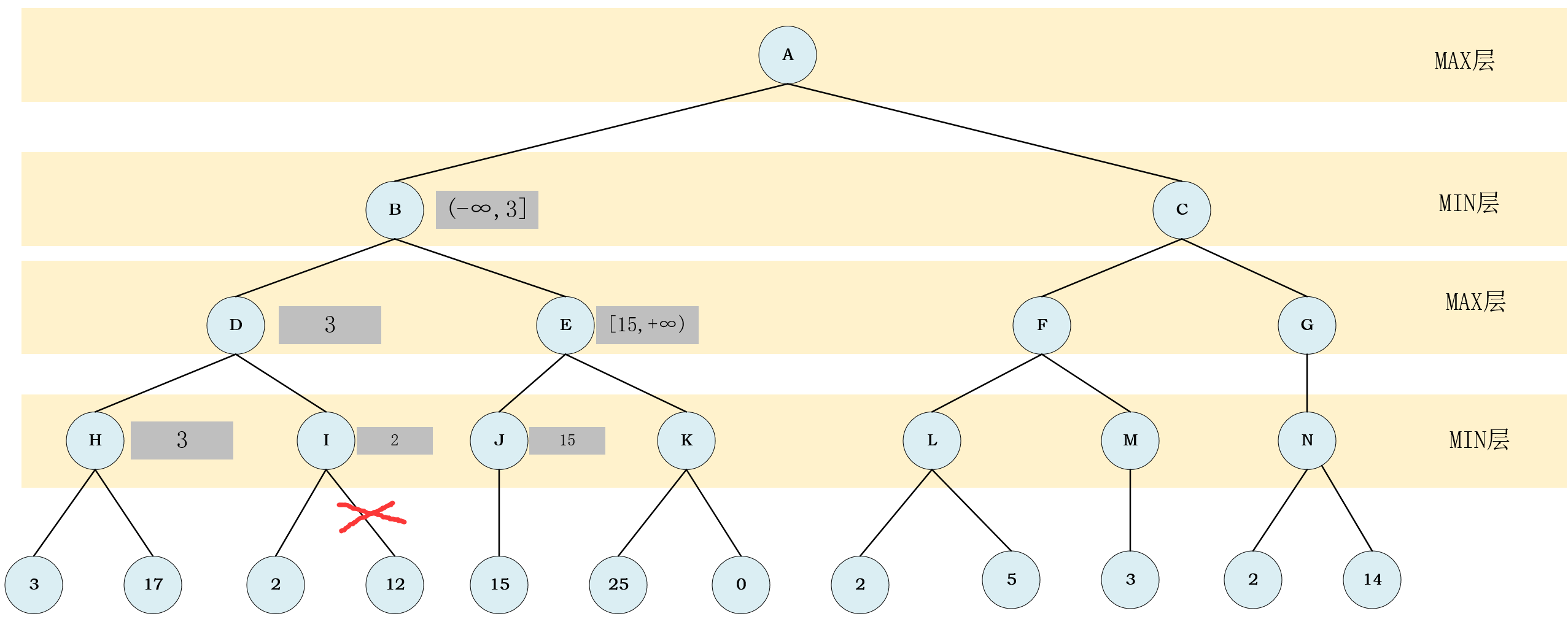
节点I,根据它左孩子(左边的子结点),可以确定节点I的取值为(-∞,2]

- 注意,这时已经满足了我们上边说的那个不太好理解的依据.
节点I的取值范围为(-∞,2],这时其父节点节点D已经有了取值范围,范围是[3,+∞),这两个范围没有交集,我们要剪掉节点I除叶子节点2之外的其他子节点.

- 到此,我们便完成了第一次剪枝.
- 剪枝完成后,可以确定
节点I的值是2,此时节点D的所有子节点的值都以确定,继而可以确定节点D的值为3. 节点D的值为3,继而确定节点B的取值范围为(-∞,3]

- 继续处理
节点J,节点J的取值为15,根据它的取值可以确定节点E范围为[15,+∞)
- 此时又满足那一个依据了,
(-∞,3]与[15,+∞)没有交集,剪掉节点E的其他子节点
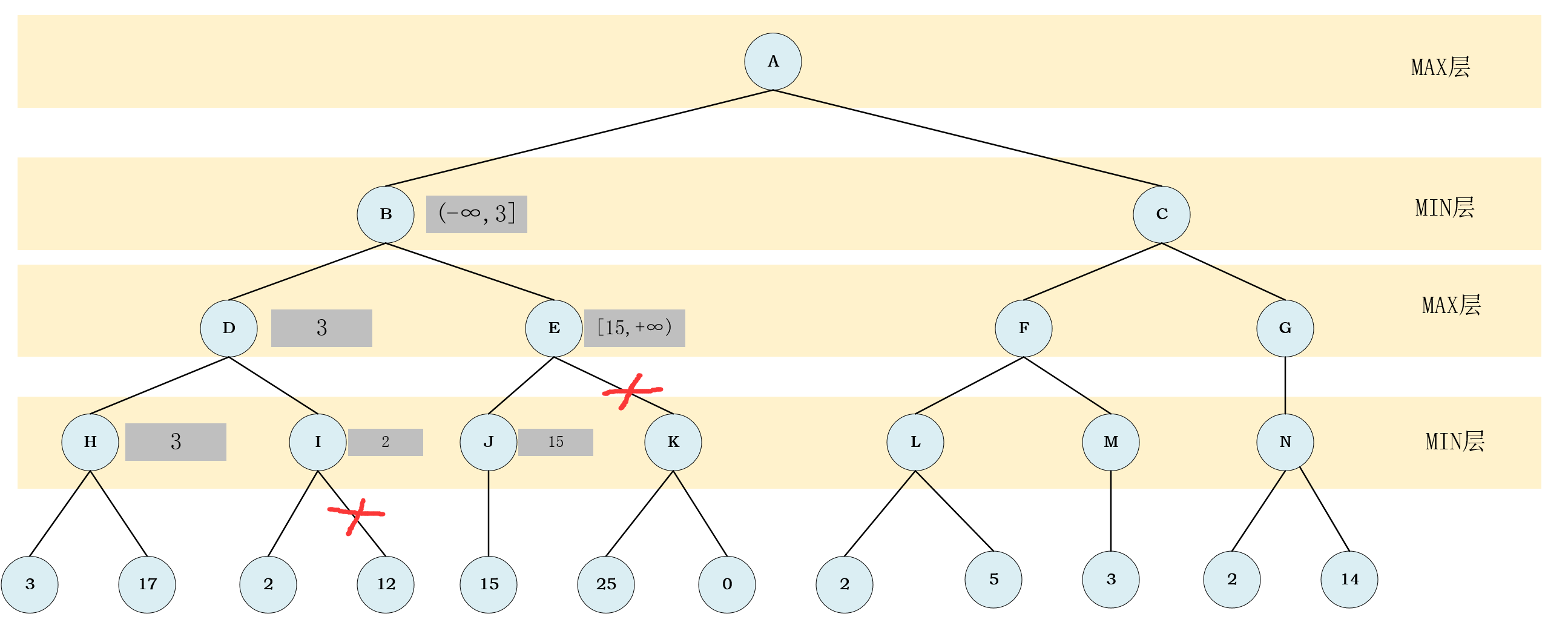
- 此时可以确定
节点E的值从而确定节点B的值,然后根据节点B的值确定节点A的取值范围.

- 处理
节点L,可以确定节点L的取值范围是(-∞,2]

- 注意,这时也满足我们上边说的那个条件,只不过这次是间接父节点,
节占L的取值范围与其间接父节点节点A的取值范围没有交集,所以要进行剪枝.

- 剪枝后,可以确定
节点L的取值,继而确定节点F的取值范围.

- 然后处理
节点M,只有一个节点可以直接确定M的取值,根据节点M的取值确定进而确定节点F的取值,再根据节点F的取值就可以确定节点C的取值范围.
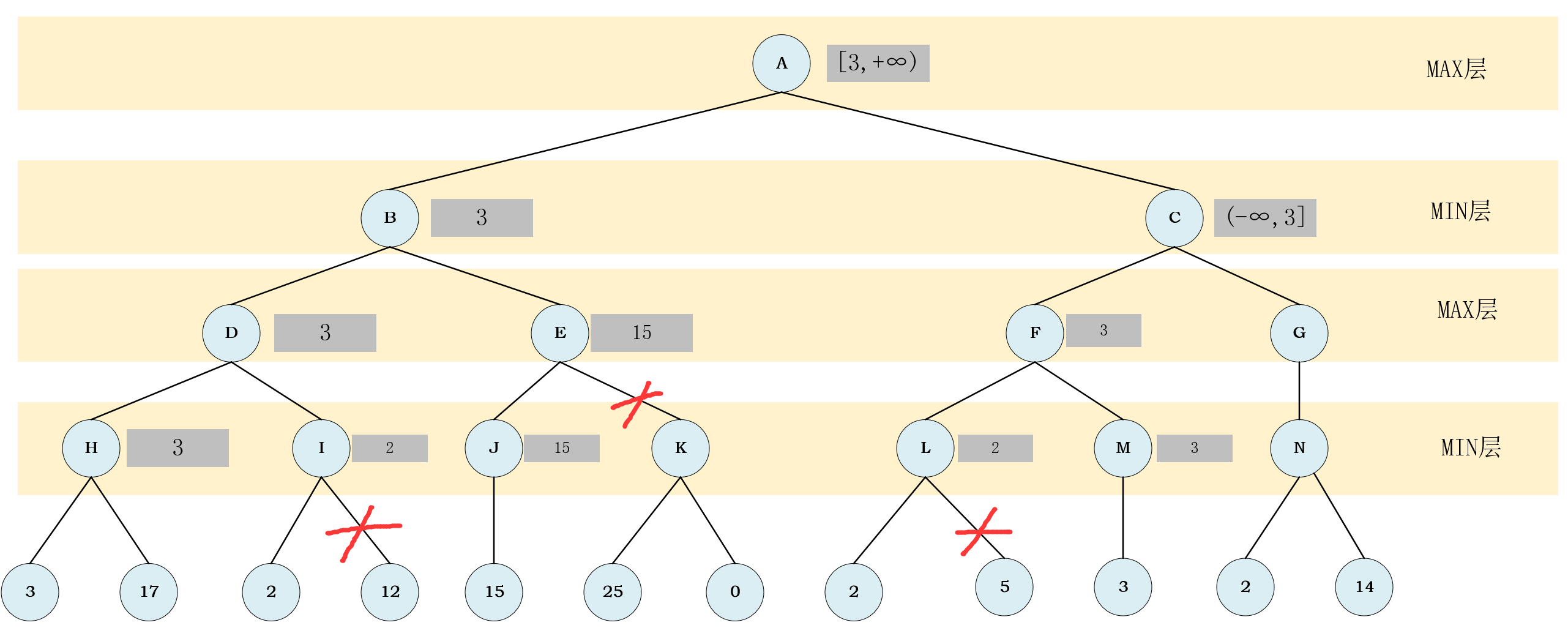
结点C的取值范围与其父节点节点A的取值范围,有交集,但交集中只有一个元素,满足我们上边所说的条件,进行剪枝.
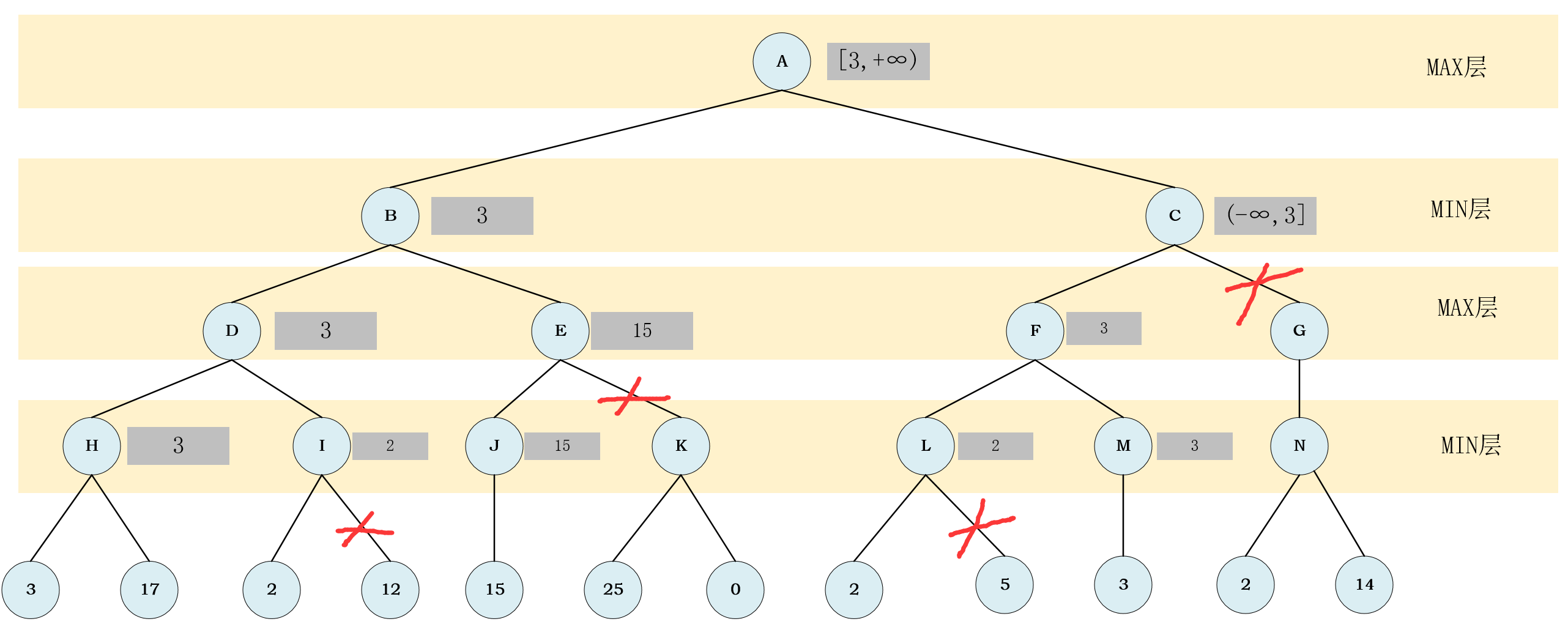
- 剪树结束后,便可以确定
节点C与节点A的值.
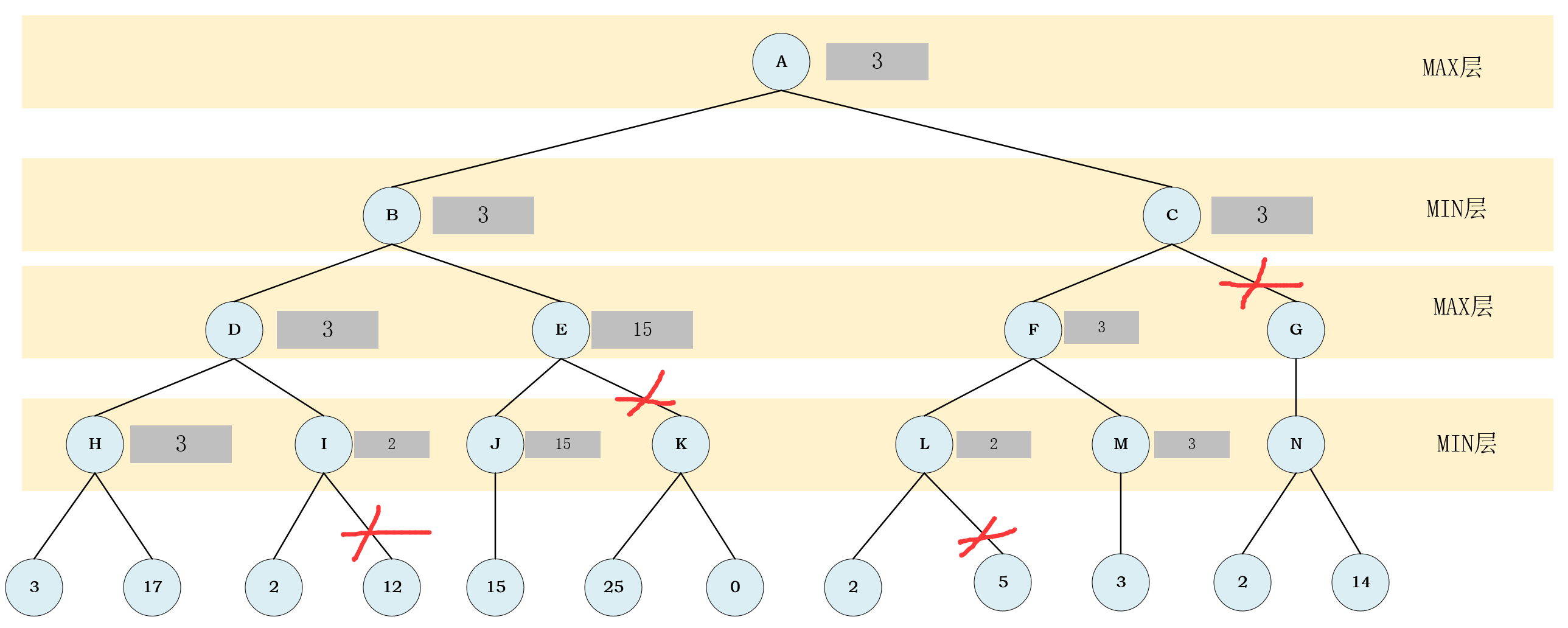
- 至此,所有未被剪枝的节点的值都已确定了,剪枝也完成了,最后的剪枝结果便是上图,去除其他的标注,最后的结果如下图.

这篇关于怎样做一道阿尔法贝塔剪枝的题(图解)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









