本文主要是介绍[论文评析]AdaptivePose: Human Parts as Adaptive Points,AAAI 2022,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AdaptivePose: Human Parts as Adaptive Points
- 文章信息
- 背景
- AdaptivePose
- 身体表示方法Body Representation
- AdaptivePose
- Part Perception Module
- Enhanced Center-aware Branch
- Two-hop Regression Branch
- Loss function
- 推理Inference
- 总结
- References
文章信息
论文题目:AdaptivePose: Human Parts as Adaptive Points
发表:AAAI 2022
作者:Yabo Xiao,1 Xiao Juan Wang, 1,* Dongdong Yu, 2 Guoli Wang, 3 Qian Zhang, 4 Mingshu He
背景
当前多人姿态估计大都采用自下而上或者自上而下的两阶段方法,这篇文章基于adaptive points这样一种新的表示方法提出了一种新的单阶段多人姿态估计方法。
那么传统的身体表示方法有哪些,都有什么问题呢? 如下图(a) -©所示,
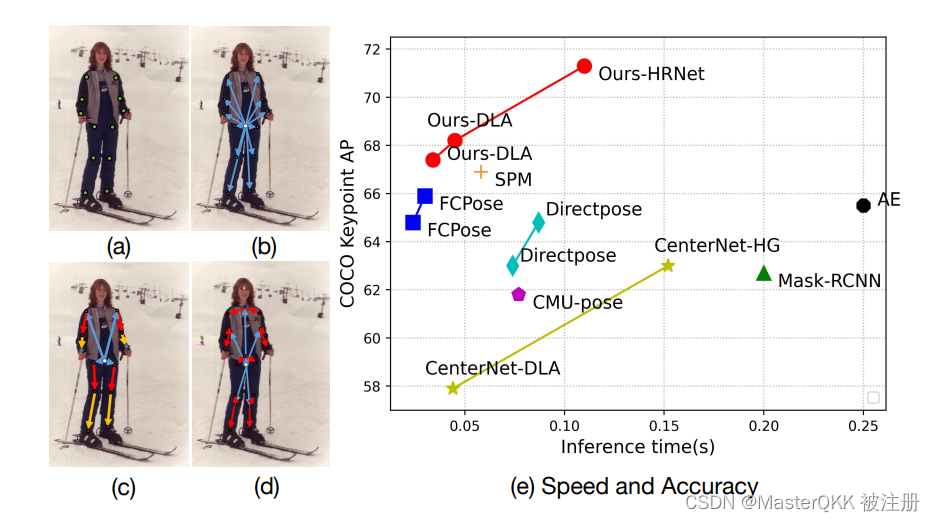
(a)通过绝对关键点的位置建立人体姿势模型: 这种方式割裂了人体与关键点之间的联系,
(b)通过中心点表示人的实例,并利用中心到关节的偏移量来形成人的姿态, 然而这种方式的问题在于:由于各种姿势的变形和中心的接受场的改变 因此很难处理中心到关节的长距离偏移问题
(c)通过根关节表示实例,并进一步提出了一个固定的分层树状结构,根据关节运动学将根关节和关键点分为四个层次。它将长距离偏移分解为累积的短距离偏移,依然存在着 沿着骨架传播的累积误差的问题
作者提出了一种新的身体表示方法,如(d)所示, 将人体部分表示为自适应点 并使用一个自适应点集,包括人类中心 和7个与人体部位相关的点来表示不同的人体实例。 这样一来人的姿势是以身体(中心)-顶部(适应点)-关节点的方式形成的。
AdaptivePose
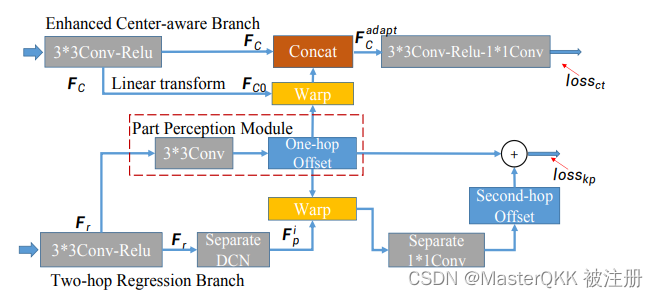
下图展示了所提出的AbaptivePose的示意图。
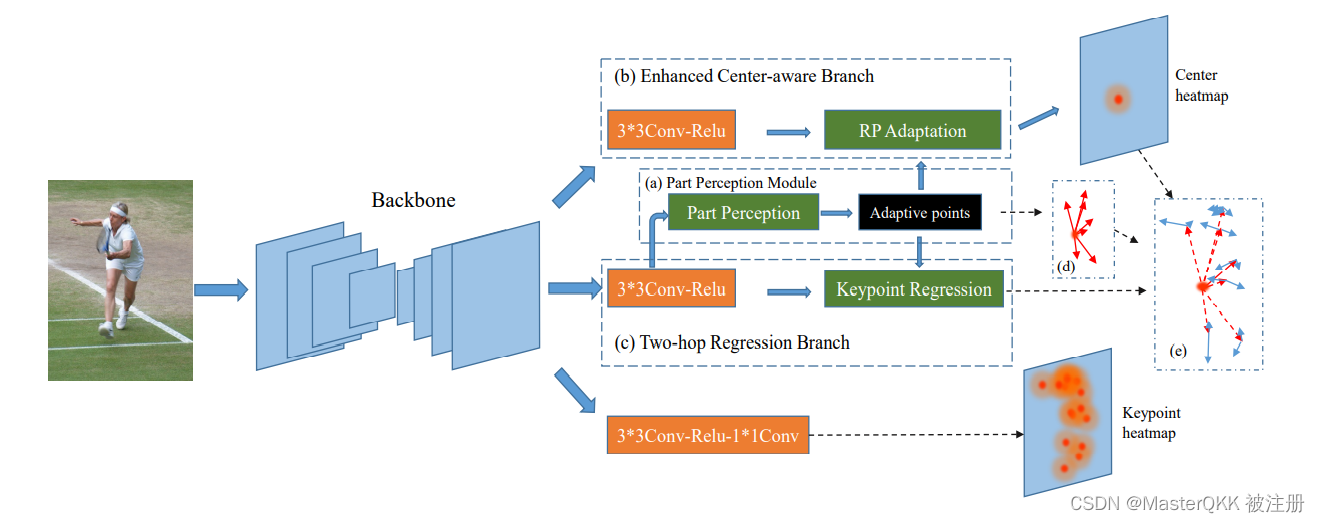
给定一个输入图像,我们首先通过Backbone提取一般的语义特征,然后通过三个精心设计的组件来预测具体信息:
(1)我们利用部分感知模块Part Perception Module,从每个人的实例的假定中心回归七个自适应的人体部分相关点。
(2)然后,我们在增强型中心感知分支Enhanced Center-aware Branch.中通过聚合自适应点的特征来预测中心热图,进行接受场适应。
(3)此外,两跳回归分支Two-hop Regression Branch将自适应的人体部分相关点作为一跳节点,间接回归从中心到每个关键点的偏移量。
下面首先介绍所提出的新型身体表示方法, 然后再分别介绍这三个模块。
身体表示方法Body Representation
所提出的表示方法引入了自适应的人体部位相关点,用于精确捕捉具有各种变形的结构化人体姿势,并自适应地将长距离的中心到关节的偏移量分解为短距离的偏移量,同时避免了沿着变形的关节骨架传播的累积误差。
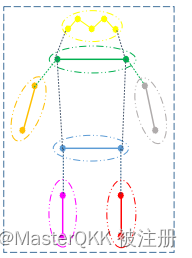
如上图所示,将人体分为7个部分,每个部分用一个 human-part related point来表示,这个点通过距离中心点的偏移量动态地回归得到。
这个过程用如下公式表示:
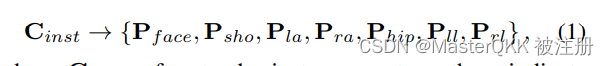
其中 C i n s t C_{inst} Cinst表示人体实例的中心,其余7个点对应人体的7个组成部分。
为了方便, 将右边7个点用 P p a r t P_{part} Ppart表示, 然后,我们利用人体部位的相关点来定位属于相应部位的关键点,用如下公式表示
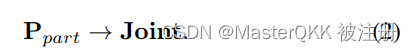
新颖的表征从实例(身体中心)-> 部分(适应性的人体部分相关点)-> 联合(身体关键点)来形成人体姿势。
AdaptivePose
下图显示了3个子网络模块:
Part Perception Module
Part Perception Module通过预测七个自适应的人体部分相关点来感知人体部分。对于每个部位,我们自动回归一个自适应的点来表示它,而不需要任何明确的监督。如上图所示,特征Fk被送入3×3卷积层,回归从中心到7个自适应的人体部位相关点的14个通道的x-y偏移量。
这些自适应点作为中间节点,用于后续进一步预测关键点,也就是文中所说的Joints。
Enhanced Center-aware Branch
如图,首先通过3x3的卷积来产生特定分支的特征Fc, 然后通过 linear transform 来获得压缩后的Fc0, 再通过对Fc0进行bilinear interpolation来获得 adaptive points的特征向量, 各部分的特征向量如下表示:
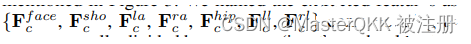
然后再将其与Fc进行拼接的得到最终的特征 F C a d a p t F_{C}^{adapt} FCadapt, 最后,使用 F C a d a p t F_{C}^{adapt} FCadapt与自适应接收场来预测中心定位的单通道概率图。其中ground_truth center map通过Gaussian分布产生,
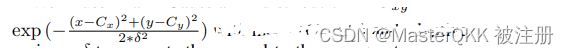
Two-hop Regression Branch
我们利用两跳回归方法来预测位移,而不是直接回归中心到关节的偏移量。这样,由部件感知模块预测的自适应人与部件的相关点作为一跳节点,将长距离的中心到关节的偏移量自适应地分解为中心到部件和部件到关节的偏移量, 这种两跳的方式用如下公式表示:
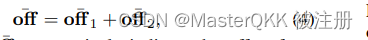
其中第一个偏移量表示从ceneter到对应adaptive points的偏移, 第二个偏移量表示从对对应adaptive points到对应keypoints的偏移。
下面介绍损失函数
Loss function
Loss总共有三部分组成:
(1)中心点ceneter的预测损失,
由于ground_truth已经转化为了heatmap, 将该损失建模为逐像素的Focal loss, 定义如下:
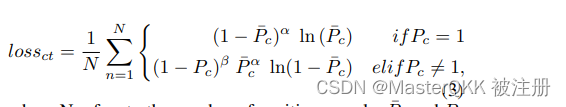
其中P表示预测/ GT的置信度值。
(2)Keypoints的预测损失
Keypoints的预测通过偏移量offset来体现, 基于L1范数计算Loss, 定义如下:
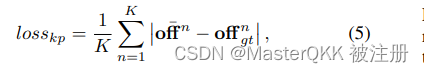
其中K表示正的keypoints的数量。
(3)Keypoints的辅助损失函数
除了直接基于offset计算keypoints的loss以外, 作者还定义了额外的辅助损失来学习keypoints的heatmap表示, 使得该特征能够保持更多的人类结构几何信息。 损失的定义与中心点ceneter的预测损失类似。
推理Inference
在推理过程中,增强型中心感知分支Enhanced Center-aware Branch输出中心热图,表明该位置是否为中心。两跳回归分支Two-hop Regression Branch 输出从中心到每个关节的偏移量。
我们首先通过在中心热图上使用5×5的max-pooling核来保持20个候选位置,然后检索相应的偏移量(δix, δiy)来形成人体姿势,而不需要任何后处理和额外的修正。keypoints的预测用如下公式表示:
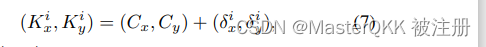
其中(Cx, Cy)表示预测的中心点center, δ x i , δ y i \delta_{x}^{i}, \delta_{y}^{i} δxi,δyi表示预测的偏移量,
总结
不多的one-stage多人姿态估计方法,
References
1.Xiao Y, Wang X J, Yu D, et al. Adaptivepose: Human parts as adaptive points[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2022, 36(3): 2813-2821.
这篇关于[论文评析]AdaptivePose: Human Parts as Adaptive Points,AAAI 2022的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
