本文主要是介绍R语言rhdf5读写hdf5并展示文件组织结构和索引数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
h5只是一种简单的数据组织格式【层级数据存储格式(HierarchicalDataFormat:HDF)】,该格式被设计用以存储和组织大量数据。
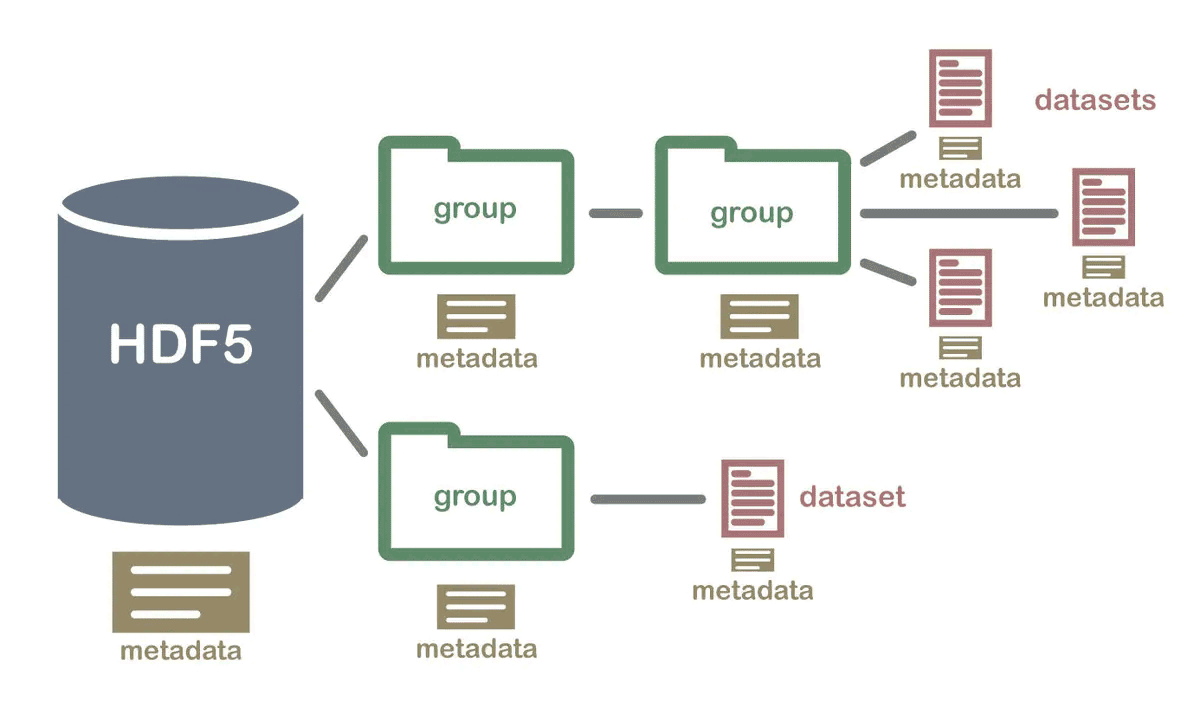
在一些单细胞文献中,作者通常会将分析的数据上传到GEO数据库保存为.h5格式文件,而不是我们常见的工程文件(rds文件,表格数据等),所以为了解析利用这些数据需要对hdf5格式的组织结构有一定的了解。
(注:在Seurat包中有现成的函数Seurat::Read10X_h5()可以用来提取表达矩阵,但似乎此外无法从h5文件中提取更多的信息)。
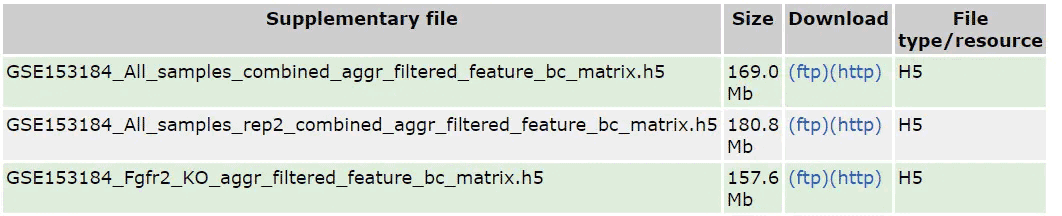
GEO数据库
在R语言中对HDF5进行操作的软件包为rhdf5。
安装
| 1 |
|
这篇关于R语言rhdf5读写hdf5并展示文件组织结构和索引数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







