本文主要是介绍论文阅读 | Event-based Video Reconstruction via Potential-assisted Spiking Neural Network,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:用SNN脉冲神经网络做基于事件相机的图像重建的文章
论文地址:【here】
代码地址:【here】
Event-based Video Reconstruction via Potential-assisted Spiking Neural Network
引言
目前的重建方法:用ANN人工神经网络
问题:人工神经网络,计算密集型,消耗大的功率,不利于处理低时延事件
解决:稀疏事件数据可以有效地与神经形态硬件芯片相结合,用于低功率脉冲神经网络(SNN)应用(神经形态芯片可以参考这篇知乎)
因此,本文结合了SNN,提出了第一个基于SNN的做事件相机图像重建的文章,并提出了一种混合电位辅助SNN(PAEVSNN),它利用自适应膜电位(AMP)神经元来改善EVSNN的时间感受域。
方法设计
1.输入表征
基于距离传播的体素网格,和E2VID一样
2.脉冲神经元的设计
- LIF Neurons
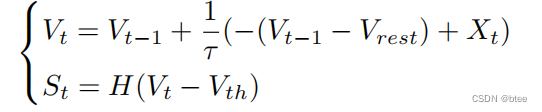
其中,Xt是输入,Vt-1是上一时刻电位,1/τ(-(Vt-1-Vrest))是触发后的衰减的电位状态
St是神经元输出,即超过阈值输出一个脉冲,这里的原本H函数不可导,用1/π(arctan(πx)+1/2)替代
代码
class LIFNode(BaseNode):def __init__(self, tau: float = 2., v_threshold: float = 1.,v_reset: float = 0., surrogate_function: Callable = surrogate.Sigmoid(),detach_reset: bool = False):assert isinstance(tau, float) and tau > 1.super().__init__(v_threshold, v_reset, surrogate_function, detach_reset)self.tau = taudef extra_repr(self):return super().extra_repr() + f', tau={self.tau}'def neuronal_charge(self, x: torch.Tensor):if self.v_reset is None:self.v = self.v + (x - self.v) / self.tauelse:if isinstance(self.v_reset, float) and self.v_reset == 0.:self.v = self.v + (x - self.v) / self.tauelse:self.v = self.v + (x - (self.v - self.v_reset)) / self.tau
- Membrane Potential Neurons
膜电位神经元,引入时间信息
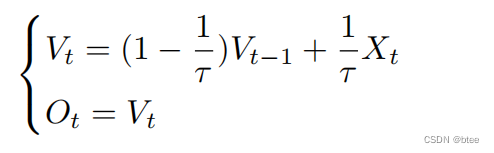
膜电位的输出由这一时刻的输入和上一时刻的电位状态加权组合而成
代码
class MpLIFNode(MpNode):def __init__(self, tau: float = 2., v_threshold: float = 1.,v_reset: float = 0., surrogate_function: Callable = surrogate.Sigmoid(),detach_reset: bool = False):assert isinstance(tau, float) and tau > 1.super().__init__(v_threshold, v_reset, surrogate_function, detach_reset)self.tau = taudef extra_repr(self):return super().extra_repr() + f', tau={self.tau}'def neuronal_charge(self, x: torch.Tensor):if self.v_reset is None:self.v = self.v + (x - self.v) / self.tauelse:if isinstance(self.v_reset, float) and self.v_reset == 0.:self.v = self.v + (x - self.v) / self.tauelse:self.v = self.v + (x - (self.v - self.v_reset)) / self.tau
网络架构
第一种:EVSNN

第二种:PA-EVSNN
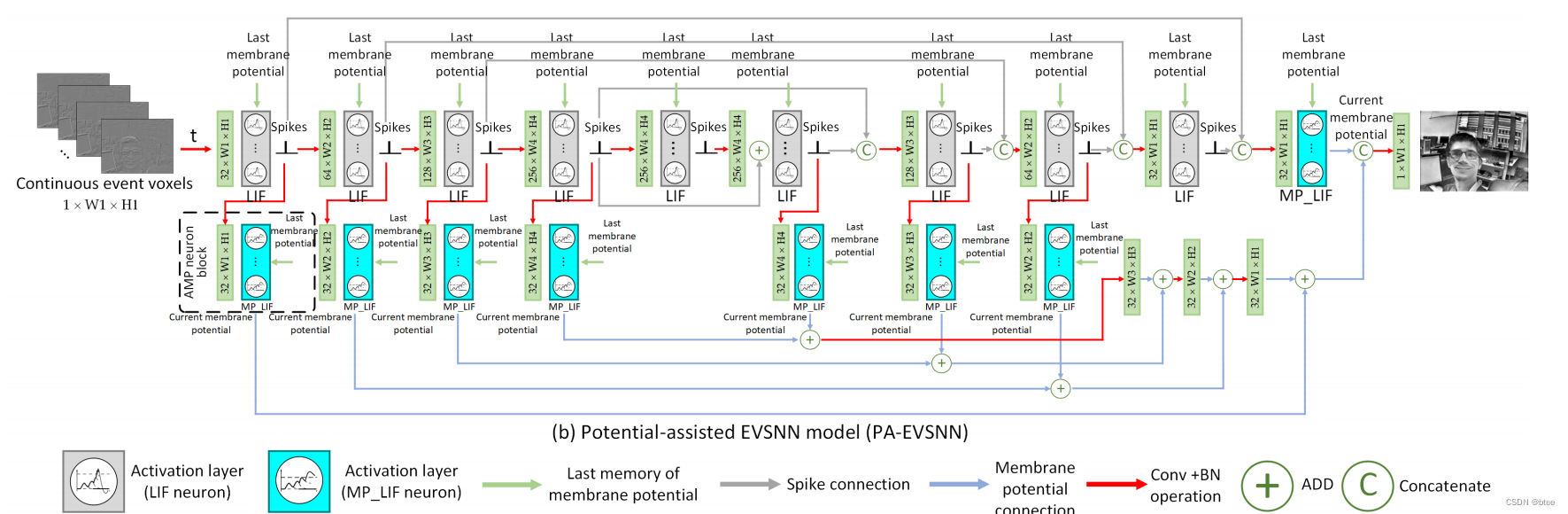
其中,每一层的SNN神经元网络
可以由构成
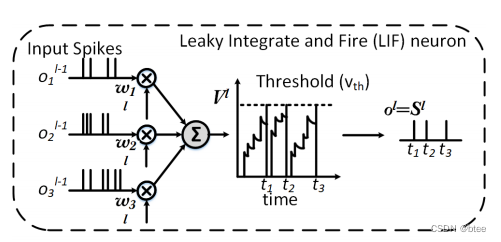
其代码层的组成为一层卷积,一层batchnorm归一化和一层LIFNode,实现局部连接的神经元
self.static_conv = nn.Sequential(nn.Conv2d(1, 32, kernel_size=5, padding=2, bias=False),nn.BatchNorm2d(32),LIFNode(v_threshold=v_threshold, tau = tau, v_reset=v_reset, surrogate_function=surrogate.ATan()),)
为了扩大感受野,网络设计了三层降采样,在更小的感受野区域与领域神经元进行连接,因此实现全局连接
实验
对比实验
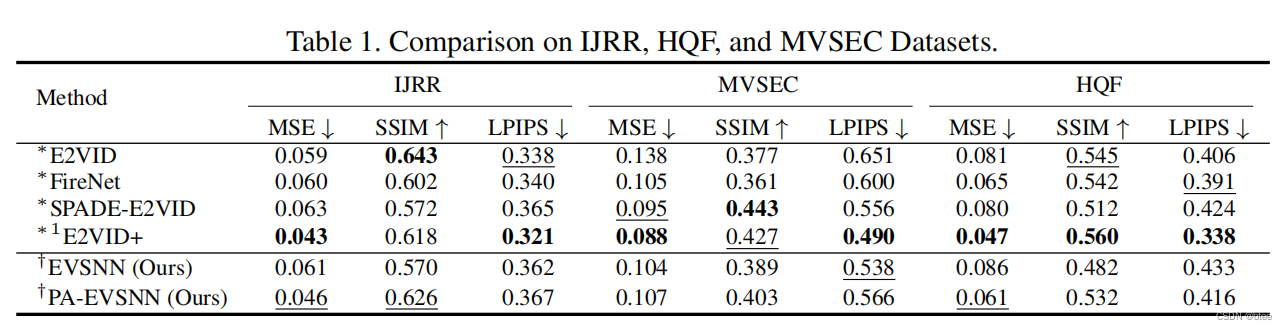
该网络与ANN相比,能达到和ANN网络差不多的效果
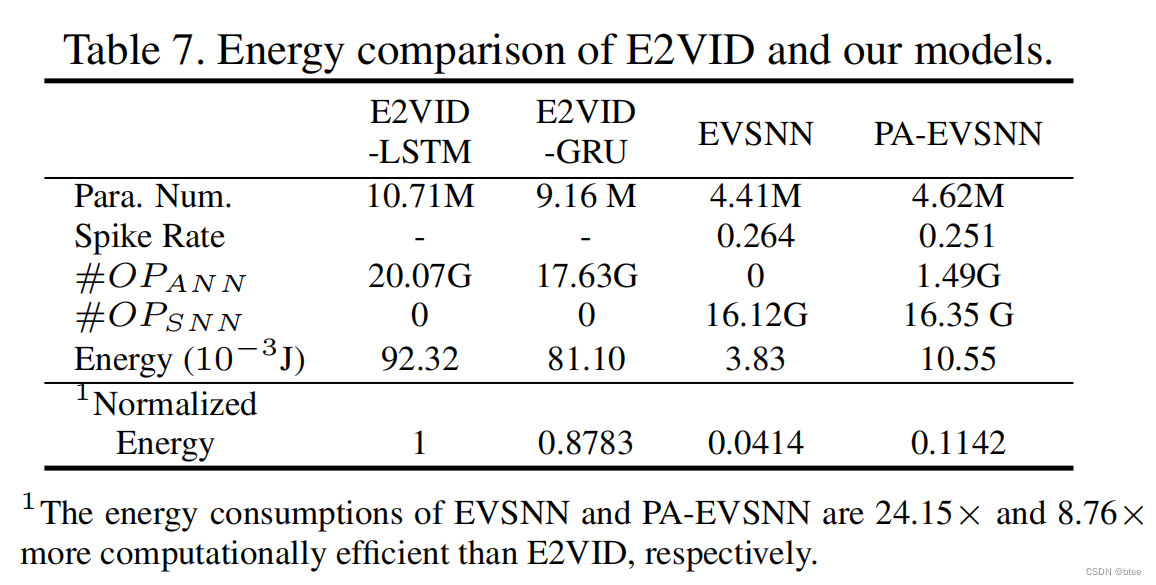
功耗对比
参数量有明显下降
总结
是第一篇用SNN做重建的文章,用SNN神经元构建卷积网络学权重的思想以及代码部分都很值得学习,但是在功耗和性能上优势不太能体现出来
这篇关于论文阅读 | Event-based Video Reconstruction via Potential-assisted Spiking Neural Network的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








