本文主要是介绍Efficiently Learning Spatial Indices,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Efficiently Learning Spatial Indices (ICDE2023)
学习索引可以利用现代深度学习技术的高预测精度和效率。它们能够提供比一维数据上的传统索引更好的查询性能。最近的研究表明,我们也可以通过划分并随后将空间数据转换为一维值来实现空间数据的查询高效学习索引,之后可以应用现有技术。在实现高效查询的同时,有效地构建和重建已学习的空间索引在很大程度上仍未得到解决。由于学习空间索引所需的模型训练成本很高,因此通过模型训练和再训练的方式在大数据集上高效地构建和重建已学习的空间索引是一项挑战
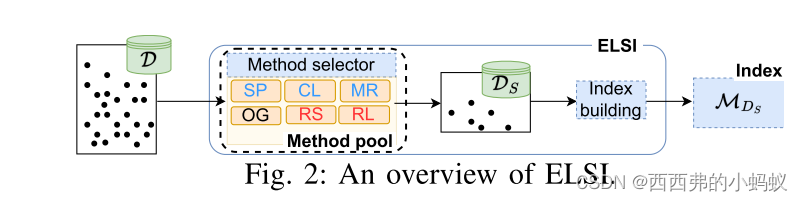
为了提高学习空间索引的实用性,我们提出了一个名为ELSI的系统,该系统能够有效地构建和重建一类遵循两个简单设计原则的学习空间索引。其核心思想是通过设计保留关键数据分布模式的简化训练集来减少模型(重新)构建时间。ELSI包含了一套从输入数据集构建小的和保持分布的训练集的方法。此外,在给定输入数据集的情况下,ELSI可以自适应地选择一种产生具有高查询效率的学习索引的方法。在超过1亿个点的真实数据集上的实验表明,ELSI可以在不影响查询效率的情况下,一致地减少四种不同的学习空间索引的构建时间(最多减少两个数量级)。
1.解决的问题
提高索引模型在大数据上的训练和重构时间和效率
2. 核心思想想法
在大数据集上进行采样,得到一个保留原始数据集分布的子数据,在该数据集上训练和重构索引模型
3. ELSI系统
1)ELSI提供了六种索引构建方法的方法集。其中五个用于生成(或获取预生成的)DS,另一个仅使用原始(OG)数据集D,作为备份选项。
2)提出了六种索引构建方法中的两种:代表集(RS)和强化学习(RL),以降低成本获得D的更好的近似DS。
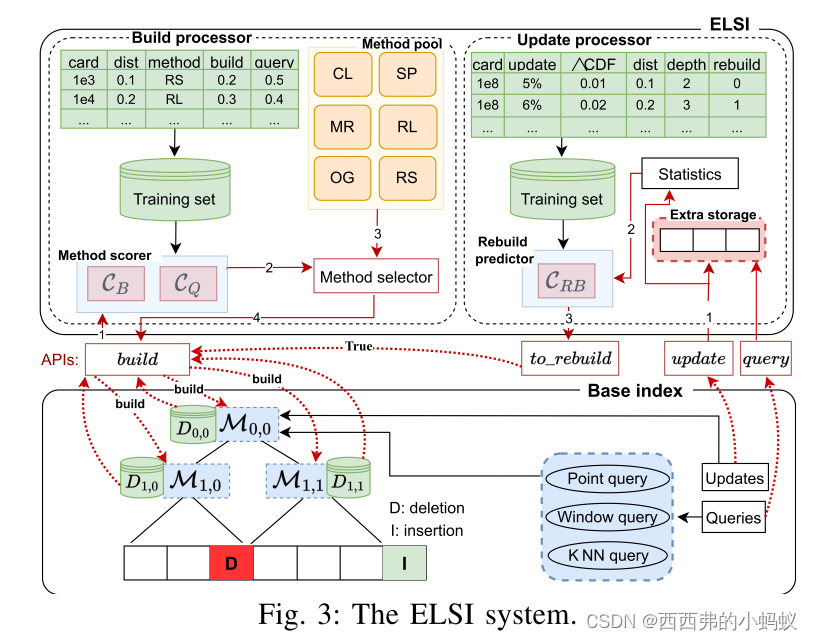
构建基本索引可以在D上训练单个索引模型,也可以对D进行分区并为每个分区训练索引模型。ELSI改善了每个索引模型的构建时间,同时不干扰分区
4. ELSI Modules
ELSI有两个主要模块:构建处理器和更新处理器。
1)构建处理器:构建处理器使用索引构建方法选择器从方法池P中选择方法P来学习索引。
目的是为D现高效的索引构建和查询处理。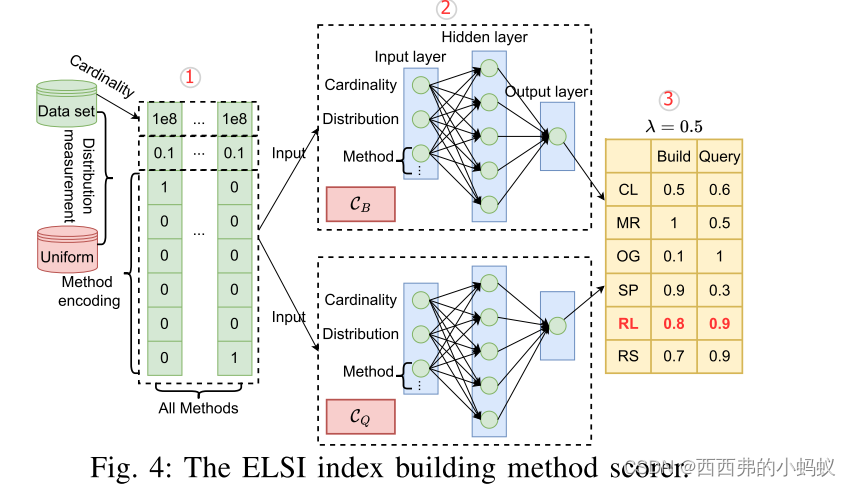
使用一个方法计分员,并选择得分最高的方法。方法scorer的关键元素是两个ffn(图4中的组件2),一个估计方法P的索引构建成本,用CB(·)表示,另一个估计方法P构建索引的查询成本,用CQ(·)表示。
2)更新处理器: 更新处理器提供默认的更新过程(基索引也可以使用其内置的更新过程)。它使用一个单独的列表来存储新插入的点和删除的现有点(或者在基本索引允许的情况下将这些点标记为已删除)。
5. INDEX BUILDING METHODS
这些方法并不构建新的索引类型,而是构建(或找到)类似于输入数据集D的小数据集。
A. Adapted Methods
1) Sampling: Random sampling
2)聚类:为了保持数据的分布模式,聚类方法(CL)将原始空间中的D聚为C(一个系统参数)聚类,并将聚类质心集作为小数据集。我们使用k-means算法是因为它很简单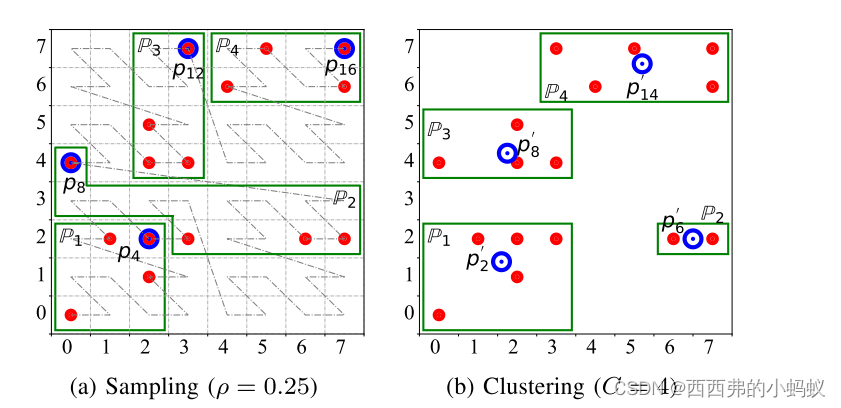
3) Model Reuse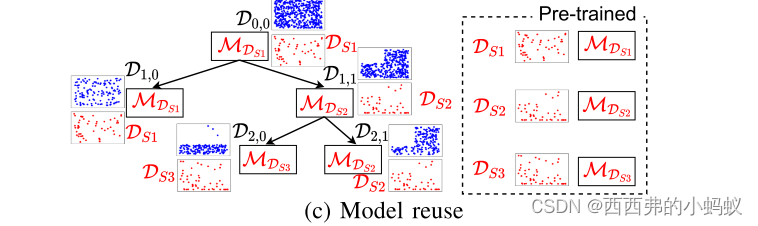
为了解决这些方法在索引建立效率(CL)或查询效率(SP和MR)方面的局限性,1) Representative Set:
2) Reinforcement Learning
6实验
数据集。我们使用四个真实数据集,OSM1, OSM2, TPC-H和NYC,以及两个合成数据集,Uniform和歪斜。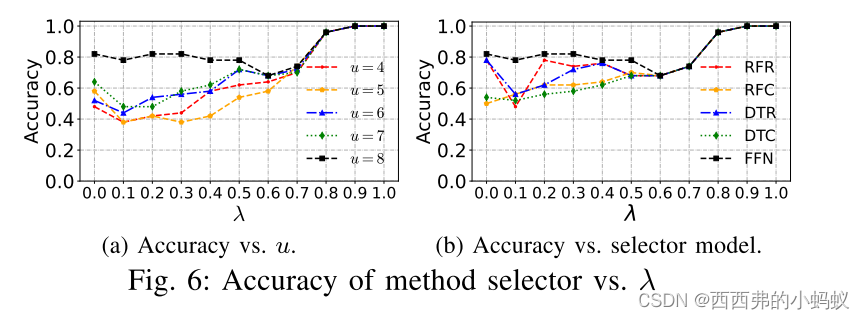
这篇关于Efficiently Learning Spatial Indices的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









