本文主要是介绍结合ESA和OceanColor下载OLCI数据(解决需要下载大量Offline数据的问题),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.前言
2.oceancolor上的OLCI数据链接
3.从ESA上下载OLCI的快视图
4.根据快视图的名称从oceancolor下载OLCI数据
建了一个QQ群,大家可以在里边聊聊水色遥感数据下载和数据处理方面的事情:1087024529
1.前言
Sentinel-3卫星搭载的OLCI传感器,作为MERIS传感器的继承者,因其较好的数据质量,受到了广泛的关注。通常情况下,下载Sentinel数据的官方地址是:https://scihub.copernicus.eu/dhus/#/home。经常使用该网站的小伙伴会知道,ESA有个LTA政策,对该政策的简单理解就是一年前的数据被标记为offline,不能立刻下载。点击offline数据的下载按钮,去激活该数据,然后等待大约半个小时即可下载,但一个用户半个小时只能激活一景数据(千万不要重复点击)。当需要下载大量历史数据时变得十分不便(大批offline数据,半小时激活一景,这得到什么时候)。
其实在oceancolor上(https://oceandata.sci.gsfc.nasa.gov/)也有OLCI的L1级数据,且不存在offline数据的问题,但是在oceancolor上根据研究区域和研究时间选择OLCI数据十分不便。
那么是否有可能结合两个网站,实现快速批量下载OLCI的offline数据呢?答案是肯定的。
2.oceancolor上的OLCI数据链接
我们先观察ocean color上的OLCI数据的下载链接:
https://oceandata.sci.gsfc.nasa.gov/sentinel/getfile/S3A_OL_1_EFR____20190105T063307_20190105T063607_20190106T095636_0180_040_034_3780_LN1_O_NT_002.zip
通过观察可以发现,ocean color上的OLCI数据下载链接,除了最后的数据文件名不一样,其他地方一模一样。那现在思路就清晰了,只要在ESA上,检索出来所要数据的文件名,然后根据文件名就可以构建出OLCI的下载链接。构建出数据的下载链接后,将下载链接放入IDM就可以愉快下载了。
3.从ESA上下载OLCI的快视图
在ESA上可以方便地根据研究区域、时间范围等条件检索需要的OLCI数据。检索到数据之后,能够通过爬虫获取到数据的下载链接(当然直接在页面上粘贴复制数据下载链接和数据的文件名也是可以的)。
对于OLCI数据,并不提供云筛选功能,所以需要通过数据的快视图来判断该数据是否值得下载,而在网页上一景一景点开看快视图查看非常麻烦,不如把检索到的快视图全部下载下来,然后进行筛选,根据筛选后的快视图文件名,得到需要的OLCI数据文件名。
这里举一个例子:
1.我随便检索了某个区域,某段时间的OLCI数据

2.点开一景影像的快视图,把鼠标光标放在快视图上,浏览器的左下角会出现快视图的下载链接(标记2):
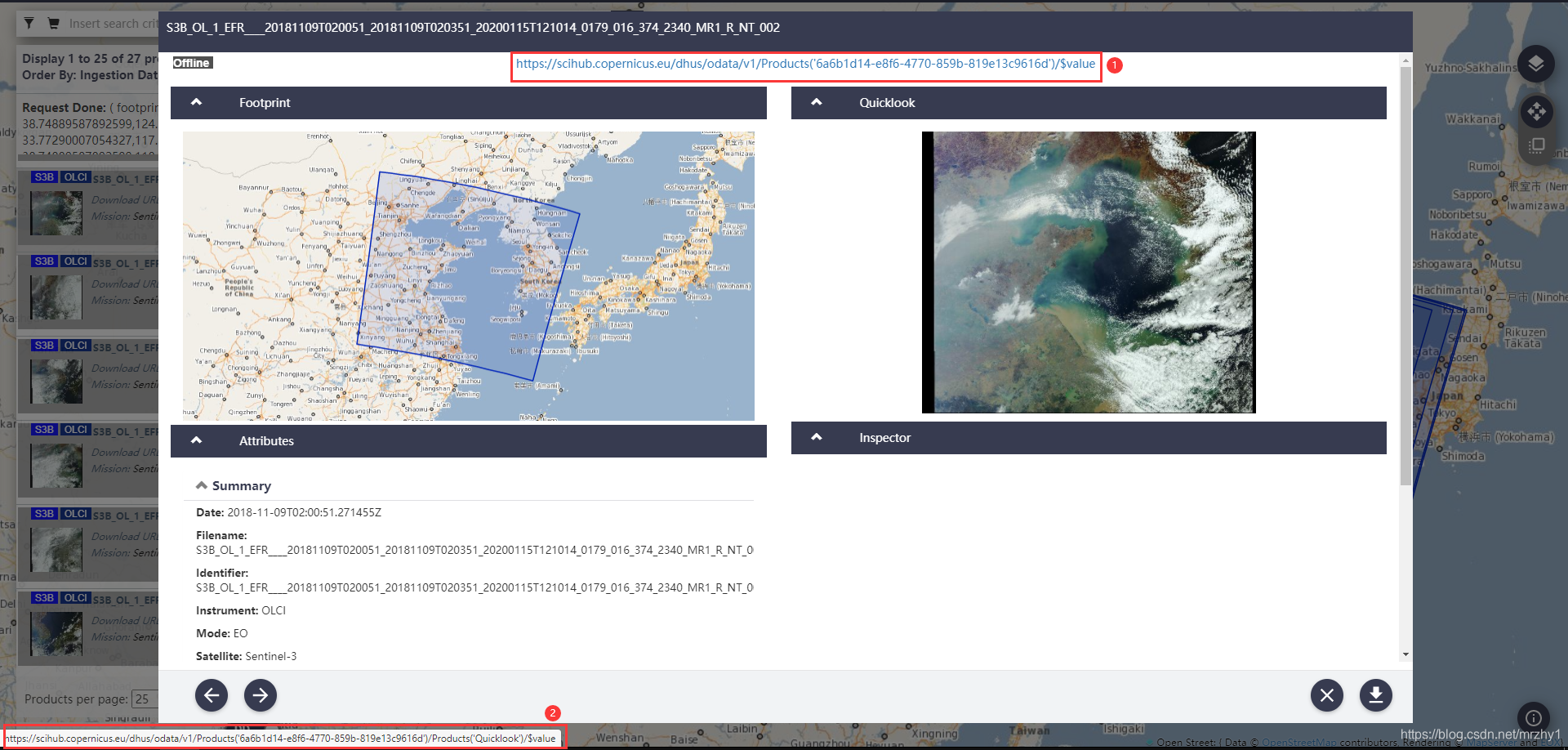
图中标记1是该数据的下载链接,通过对比标记1和标记2可以发现,快视图的下载链接比数据的下载链接多了:/Products(‘Quicklook’)
https://scihub.copernicus.eu/dhus/odata/v1/Products('6a6b1d14-e8f6-4770-859b-819e13c9616d')/$value
https://scihub.copernicus.eu/dhus/odata/v1/Products('6a6b1d14-e8f6-4770-859b-819e13c9616d')/Products('Quicklook')/$value
而我之前做过爬取检索到的数据链接,稍加就可以使用。下面描述具体步骤。
3.将检索到数据的网页保存下来,最好在红框处点击右键另存网页(如果检索的数据很多,最好调整每页数据数到最大):

在弹出另存网页对话框时,切记将保存类型选为:网页,完成
4.打开保存网页的HTML可以发现,数据的下载链接在一个class属性为list-link selectable的div标签下的a标签中。通过这些信息我们就可以找到数据的下载链接,并且构建出快视图的下载链接,代码如下(最后的快视图链接保存为一个txt文件):
from bs4 import BeautifulSoup
import time
import os
webPage=['F:/MyCSDN/ESA+oceancolor/Page1.html'] #构建保存文件的路径列表,保存多个网页也可以使用该方案
outFileName='F:/MyCSDN/ESA+oceancolor/quickLookLink.txt'nodeattrs={"class" :"list-link selectable"} with open(outFileName,'w+') as ofn:for wp in webPage:with open(wp,'rb') as f:ss=f.read()soup=BeautifulSoup(ss,'html.parser') divfind=soup.find_all('div',attrs=nodeattrs)dataLinkList=[]for df in divfind:link=df.find('a').stringid=link.split('\'')[1]qklink="https://scihub.copernicus.eu/dhus/odata/v1/Products('"+id+"')/Products('Quicklook')/$value"#print(qklink)ofn.writelines(qklink+'\n')
保存的结果:
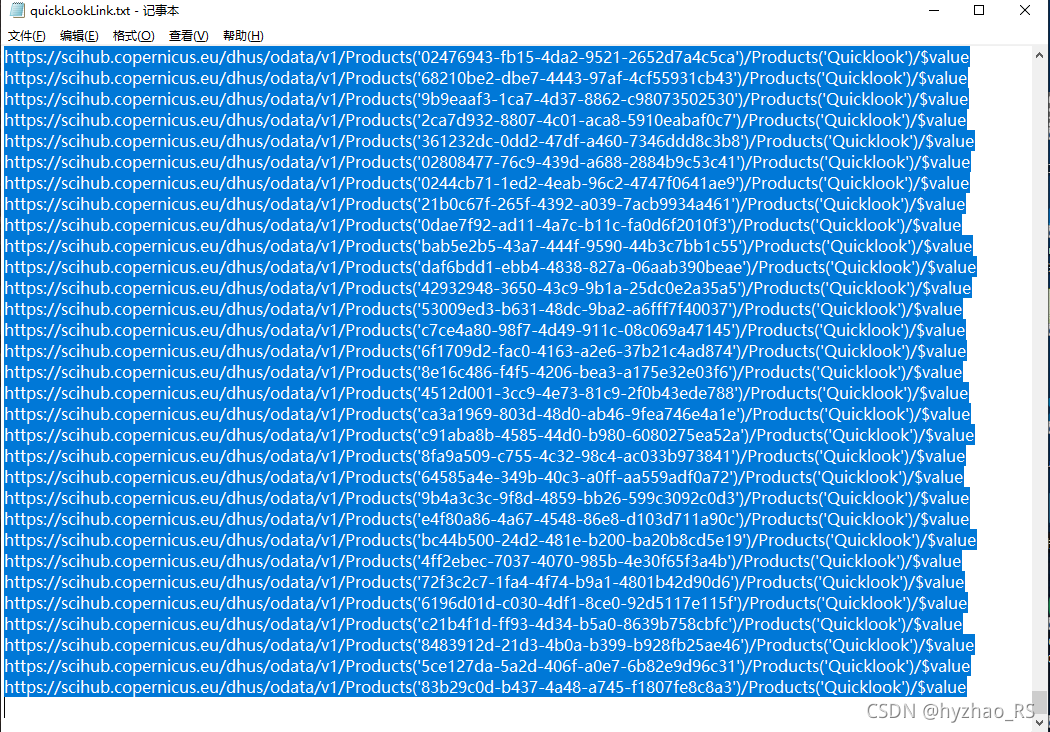
5.将这些链接导入IDM中,就可以批量进行下载。下载的结果如图所示,可以看到,下载的快视图中包括了数据的文件名。

4.根据快视图的名称从oceancolor下载OLCI数据
1.根据上一步下载到的快视图文件名(这里可以通过快视图判断影像质量,做一个筛选,把不用的数据删除掉。想不想筛选都随你),构建oceancolor上的OLCI数据下载链接。
import os
qkFileDir='F:/MyCSDN/ESA+oceancolor/QucikLook/'
fileList=os.listdir(qkFileDir)
OLCILink='F:/MyCSDN/ESA+oceancolor/olcilink.txt'
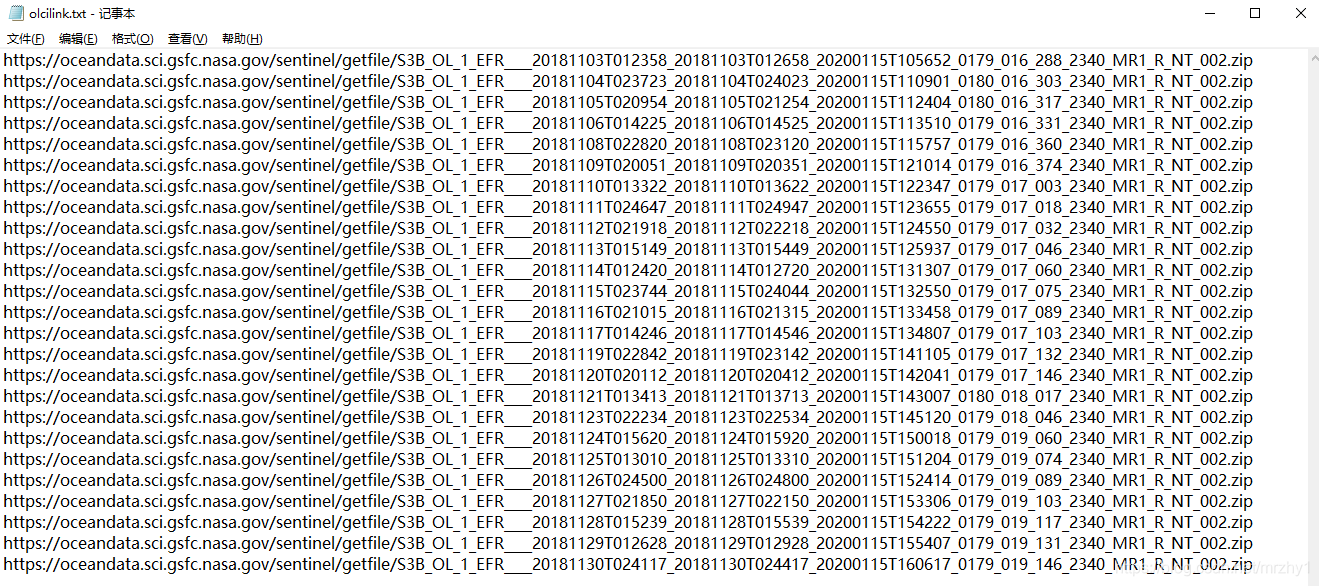
with open(OLCILink,'w') as ol:for fl in fileList:fileName=fl[:-7]dataLink='https://oceandata.sci.gsfc.nasa.gov/sentinel/getfile/'+fileName+'.zip'ol.writelines(dataLink+'\n')
生成的文件结果:
然后就可以将数据下载链接加入IDM进行批量下载了。
2.将数据加入到IDM之前,需要对IDM进行配置,在(通过菜单栏:下载->选项->站点管理)站点管理器中,加入你的账号名和密码。注意服务器路径写入urs.earthdata.nasa.gov,而不是oceancolor.gsfc.nasa.gov

这篇关于结合ESA和OceanColor下载OLCI数据(解决需要下载大量Offline数据的问题)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




