本文主要是介绍悦影科技—脑影像数据MVPA和机器学习分析服务,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
近些年来,机器学习及大数据成为各行各业的热门。如今机器学习及python的编程已经出现在很多小学生的课本中,甚至成为一些学校的必修课程。目前,由谷歌公司开发的深度学习模型,能够对糖尿病视网膜病变做出快速准确的诊断,其诊断能力等于甚至超过了有经验的眼科医生[https://jamanetwork.com/journals/jama/fullarticle/2588763]。由国内的开发者开发的中枢神经系统肿瘤的诊断模型,其对常见的中枢神经系统肿瘤的诊断能力无论是速度还是准确度都远远超出了人类。
回到神经影像领域,不管是task-based fMRI所说的多体素/变量模式识别(MVPA)还是resting-state fMRI所说的机器学习逐渐成为各自研究领域的前沿。不同于传统的单变量的分析,机器学习或者多变量的分析能同时考虑到多个变量的高级的、交互的信息。训练出的模型可以应用与新的被试或新的scan。为此河南悦影医药科技有限公司(简称悦影科技)特推出脑影像数据机器学习分析业务。 我们团队由多年从事MRI、EEG数据处理和机器学习技术研究的博士和高校老师组成,“专业,诚信,合作,共赢”是我们一直恪守的服务理念,悦影科技竭诚为您提供高质量、精准的数据处理服务。
脑影像数据MVPA和机器学习分析具体业务如下:
一、静息态fMRI或者结构MRI的机器学习分析
计算得到的各种功能、结构磁共振指标都可以作为机器学习的特征。应用机器学习的目的一般为疾病的预测、诊断、鉴别诊断、表型(如症状)预测、疗效预测、疾病分型、神经机制解码等。具体分为:
1.分类:支持的算法包括但不限于支持向量机(SVM)、逻辑回归、L2正则分类、随机森林、高斯过程分类、Adaboost等。另外,我们也特别推出基于深度卷积神经网络的分类,其接受全脑功能连接网络(2D卷积)或者3D脑影像(3D卷积)作为特征。
2.回归:支持的算法包括但不限于最小二乘法线性回归、Lasso回归(L1正则),Ridge回归(L2正则)、Elastic-Net回归(L1+L2正则)、支持向量机回归(SVM)、高斯过程回归、随机森林回归、稀疏典型回归等。同样我们也可以定制基于深度学习的回归。
3.聚类:支持的算法包括但不限于K-means 聚类、层次聚类、谱聚类、基于密度的聚类(DBSCAN)。
二、任务态fMRI的MVPA分析
经过预处理后,每个被试的数据是一个4D时间序列数据,每一帧图像都是一个3D脑影像。无论您是block设计、event设计还是混合设计,只要您的的数据的每一个scan有对应的标签(比如面孔或者房子),而且数据是nifti或者常用的格式,我们在了解您的需求后能帮您完成任务态fMRI的MVPA分析。
Figure 1. 人工智能,机器学习以及深度学习的关系
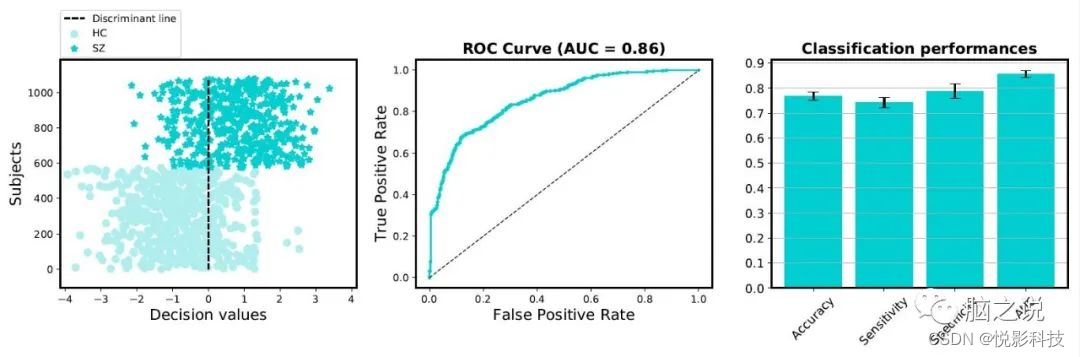
Figure 2. 基于功能连接精神分裂症诊断结果示意图
三、个性化的分析项目
本团队老师有多年编程以及科研经验,能根据客户需求迅速找到科研突破口,实现文献中的核心技术难题。除了上述的分析指标之外,我们还可以为您提供以下服务:
1.已有具体研究思路和参考文献,但不知道怎么实现文献方法:我们可以为您复现文献的方法。
2.尚未有具体研究思路,但是有一定研究目的:我们根据您的研究目的,提供合适的方法。
注:由于个性化分析内容复杂多样,有意向的可以先找我们洽谈商议。
这篇关于悦影科技—脑影像数据MVPA和机器学习分析服务的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






