本文主要是介绍TLAB、OOM、调优工具(实现原理)、调优实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、TLAB
新生代堆区独享的堆区。
因为并发情况下分配内存,会存在性能问题。所以为了解决这个问题,设计了一个在线程级别分配对象的功能,就是TLAB.
New对象与指针碰撞
new对象怎么就出问题了呢?
java中我们要创建一个对象,用关键字new就可以了。但是,在我们日常中,有很多生命周期很短的对象。比如:
public void dome(){User user=new user();user.sayhi();
}
这种对象的作用域都不会逃逸出方法外,也就是说该对象的生命周期会随着方法的调用开始而开始,方法的调用结束而结束。
假设JVM所有的对象都放在堆内存中(为什么用假设,因为JVM并不是这样)一旦方法结束,没有了指向该对象的引用,该对象就需要被GC回收,如果存在很多这样的情况,对GC来说压力山大呀。
那么什么又是指针碰撞呢?
假设JVM虚拟机上,堆内存都是规整的。堆内存被一个指针一分为二。指针的左边都被塞满了对象,指针的右变是未使用的区域。每一次有新的对象创建,指针就会向右移动一个对象size的距离。这就被称为指针碰撞。

好,问题来了。如果我们用多线程执行刚才的dome方法,一个线程正在给A对象分配内存,指针还没有来的及修改,同时为B对象分配内存的线程,仍引用这之前的指针指向。这样就出现毛病了。
(要注意的是,上面两种情况解决方案不止一个,我今天主要是讲TLAB,其他方案自行查询)
TLAB
TLAB的全称是Thread Local Allocation Buffer,即线程本地分配缓存区,这是一个线程专用的内存分配区域。
如果设置了虚拟机参数 -XX:UseTLAB,在线程初始化时,同时也会申请一块指定大小的内存,只给当前线程使用,这样每个线程都单独拥有一个空间,如果需要分配内存,就在自己的空间上分配,这样就不存在竞争的情况,可以大大提升分配效率。
TLAB空间的内存非常小,缺省情况下仅占有整个Eden空间的1%,也可以通过选项-XX:TLABWasteTargetPercent设置TLAB空间所占用Eden空间的百分比大小。
TLAB的本质其实是三个指针管理的区域:start,top 和 end,每个线程都会从Eden分配一块空间,例如说100KB,作为自己的TLAB,其中 start 和 end 是占位用的,标识出 eden 里被这个 TLAB 所管理的区域,卡住eden里的一块空间不让其它线程来这里分配。
TLAB只是让每个线程有私有的分配指针,但底下存对象的内存空间还是给所有线程访问的,只是其它线程无法在这个区域分配而已。从这一点看,它被翻译为 线程私有分配区 更为合理一点
当一个TLAB用满(分配指针top撞上分配极限end了),就新申请一个TLAB,而在老TLAB里的对象还留在原地什么都不用管——它们无法感知自己是否是曾经从TLAB分配出来的,而只关心自己是在eden里分配的。
TLAB的缺点
事务总不是完美的,TLAB也又自己的缺点。因为TLAB通常很小,所以放不下大对象。
-
1、TLAB空间大小是固定的,但是这时候一个大对象,我TLAB剩余的空间已经容不下它了。(比如100kb的TLAB,来了个110KB的对象)
-
2,TLAB空间还剩一点点没有用到,有点舍不得。(比如100kb的TLAB,装了80KB,又来了个30KB的对象)
所以JVM开发人员做了以下处理,设置了最大浪费空间。
当剩余的空间小于最大浪费空间,那该TLAB属于的线程在重新向Eden区申请一个TLAB空间。进行对象创建,还是空间不够,那你这个对象太大了,去Eden区直接创建吧!
当剩余的空间大于最大浪费空间,那这个大对象请你直接去Eden区创建,我TLAB放不下没有使用完的空间。当然,又回造成新的病垢。
-
3,Eden空间够的时候,你再次申请TLAB没问题,我不够了,Heap的Eden区要开始GC,
-
4,TLAB允许浪费空间,导致Eden区空间不连续,积少成多。以后还要人帮忙打理。
二、PLAB
老年代线程独享的堆区
可以看到和 TLAB 很像,PLAB 即 Promotion Local Allocation Buffers。
用在年轻代对象晋升到老年代时。
在多线程并行执行 YGC 时,可能有很多对象需要晋升到老年代,此时老年代的指针就“热”起来了,于是搞了个 PLAB。
先从老年代 freelist(空闲链表 申请一块空间,然后在这一块空间中就可以通过指针加法(bump the pointer)来分配内存,这样对 freelist 竞争也少了,分配空间也快了。

三、OOM(Out of Memory )
为什么会发生OOM
回收的速度比不上用的速度
来不及回收
哪几个区会发生OOM
1、堆区
package com.jihu.test.oom;import java.util.ArrayList;
import java.util.List;public class HeapOverFlowTest {int[] intArr = new int[58];// -Xms15m -Xmx15m -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=E:/tmp/heapdump.hprofpublic static void main(String[] args) {List<HeapOverFlowTest> objs = new ArrayList<>();for (;;) {try {Thread.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}objs.add(new HeapOverFlowTest());}}
}

我们这里不停的创建对象,JVM会一直full GC.

GC overhead limit exceeded Eoor: 这里指的是频繁的full gc导致的OOM,这里还不是因为head overflow。
GC日志
GC日志
相关参数:
-XX:+PrintGC 输出GC日志
-XX:+PrintGCDetails 输出GC的详细日志
-XX:+PrintGCTimeStamps 输出GC的时间戳(以基准时间的形式)
-XX:+PrintGCDateStamps 输出GC的时间戳(以日期的形式,如 2013-05-04T21:53:59.234+0800)
-XX:+PrintHeapAtGC 在进行GC的前后打印出堆的信息
-Xloggc:…/logs/gc.log 日志文件的输出路径
–XX:+PrintFlagsFinal -version可以输出按字母排序的所有XX参数和值的表格
-XX:+HeapDumpOnOutOfMemoryError参数表示当JVM发生OOM时,自动生成DUMP文件。
日志内容:
1、gc类型:GC、Full GC
2、gc原因:Metadata GC Threshold、Last ditch collection……
3、gc前内存数据
4、gc后内存数据
5、花费的时间:用户态、内核态、实际用时
使用perfma查看dump出的堆区GC日志
1、寒泉子公司的:https://xpocket.perfma.com/
先点击社区讨论,然后点击控制台,上传dump出来的gc日志

然后我们点击本地上传:


然后我们点击到类视图中来分析:

我们可以看到int[]这个类占了很大的内存,我们总共设置了15m,它就占用了12m. 我们点进去分析,查看被引用对象列表:


然后我们查看这个列表,看看是被在哪里被创建出来的。

这里已经可以定位到具体的某一个类。
使用VisualVM分析日志
我们启动visualVM之后,选择文件,装入本地日志:



我们点击类,然后可以看到int占用了非常多的内存。

我们点进去查看发现很多引用是类HeapOverFlowTest.这样就能定位到具体的类了。
通过日志定位问题
1、找到内存占用比较多的实例
调优原则
1、通过日志找到具体的原因,到底是是否是程序的原因
2、如果不是程序的原因,那就调优堆区
full gc产生的原因
老年代满了
分析什么样的对象会进入老年代
2、方法区
CHLIB是字节码增强工具,可以直接操作字节码。
我们写一段程序,借助GCLIB,动态生成instanceKlass对象:
package com.jihu.test.oom;import net.sf.cglib.proxy.Enhancer;
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;import java.lang.reflect.Method;public class MetaSpaceOverFlowTest {/*** -XX:+PrintGCDetails -XX:MetaspaceSize=20m -XX:MaxMetaspaceSize=20m* * 需要CGLIB依赖:* <dependency>* <groupId>cglib</groupId>* <artifactId>cglib</artifactId>* <version>2.2.2</version>* </dependency>* <p>* 通过CGLIB模拟向元空间写入数据*/public static void main(final String[] args) {while (true) {try {Thread.sleep(20);} catch (InterruptedException e) {e.printStackTrace();}Enhancer enhancer = new Enhancer();enhancer.setSuperclass(MetaSpaceOverFlowTest.class);enhancer.setUseCache(false);enhancer.setCallback(new MethodInterceptor() {public Object intercept(Object obj, Method method, Object[] objects, MethodProxy proxy) throws Throwable {return proxy.invokeSuper(obj, args);}});System.out.println("running...");enhancer.create();}}
}

GC日志:
[GC (Metadata GC Threshold) // GC:表明此次是Minor GC// Metadata GC Threshold: 产生GC的原因
[PSYoungGen: 4337K->64K(335360K)] 7912K->3638K(2415616K), 0.0005997 secs] // PSYoungGen: 使用的新生代垃圾回收器, Parallel Scavenge// 4337K:GC之前新生代占用的内存大小// 64K:GC之后新生代占用的内存大小// 335360KK:新生代总内存大小// 7912K:GC之前堆占用的空间// 3638K: GC之后堆占用的空间// 2415616K:整个堆的空间大小// 0.0005997 secs:执行GC的时间
[Times: user=0.00 sys=0.00, real=0.00 secs]
// user=0.00:GC在用户态的耗时时间
// sys=0.00:GC在内核态的耗时时间
// real=0.00 secs GC阶段实际耗时[Full GC (Metadata GC Threshold) // Full GC:表明此次是full gc // Metadata GC Threshold:GC原因
[PSYoungGen: 64K->0K(335360K)] // PSYoungGen:新生代垃圾回收器, Parallel Scavenge// 64K:GC之前新生代占用内存大小// 0K: GC之后新生代占用内存大小
[ParOldGen: 3574K->3573K(2080256K)] 3638K->3573K(2415616K), // ParOldGen: 老年代垃圾回收器, Parallel Old// 3574K:GC之前老年代占用内存大小// 3573K:GC之后老年代占用内存大小// 2080256K:老年代占用的总内存大小// 3638K:GC之前整个堆占用的大小// 3573K: GC之后整个堆占用的大小// 2415616K:整个堆占用的总大小
[Metaspace: 19840K->19840K(1067008K)], 0.0174651 secs] // Metaspace:元空间// 19840K:GC之前元空间占用的内存大小// 19840K:GC之后元空间占用的内存大小// 1067008K:整个元空间占用的内存大小// 0.0174651 secs:GC执行时间
[Times: user=0.02 sys=0.00, real=0.02 secs] // user=0.00:GC在用户态的耗时时间// sys=0.00:GC在内核态的耗时时间// real=0.00 secs GC阶段实际耗时
我们来使用G1垃圾回收器,然后查看GC日志:
-XX:+PrintGCDetails -XX:MetaspaceSize=20m -XX:MaxMetaspaceSize=20m -XX:+UseG1GC
[GC pause (G1 Evacuation Pause) (young), 0.0094929 secs][Parallel Time: 2.3 ms, GC Workers: 4][GC Worker Start (ms): Min: 1572.1, Avg: 1572.1, Max: 1572.2, Diff: 0.0][Ext Root Scanning (ms): Min: 0.1, Avg: 0.4, Max: 0.6, Diff: 0.4, Sum: 1.7][Update RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0][Processed Buffers: Min: 0, Avg: 0.0, Max: 0, Diff: 0, Sum: 0][Scan RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0][Code Root Scanning (ms): Min: 0.0, Avg: 0.1, Max: 0.3, Diff: 0.3, Sum: 0.4][Object Copy (ms): Min: 1.5, Avg: 1.7, Max: 1.8, Diff: 0.2, Sum: 6.6][Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0][Termination Attempts: Min: 1, Avg: 3.0, Max: 5, Diff: 4, Sum: 12][GC Worker Other (ms): Min: 0.0, Avg: 0.1, Max: 0.3, Diff: 0.3, Sum: 0.4][GC Worker Total (ms): Min: 2.3, Avg: 2.3, Max: 2.3, Diff: 0.0, Sum: 9.1][GC Worker End (ms): Min: 1574.4, Avg: 1574.4, Max: 1574.4, Diff: 0.0][Code Root Fixup: 0.0 ms][Code Root Purge: 0.0 ms][Clear CT: 0.0 ms][Other: 7.1 ms][Choose CSet: 0.0 ms][Ref Proc: 0.5 ms][Ref Enq: 0.0 ms][Redirty Cards: 0.0 ms][Humongous Register: 0.0 ms][Humongous Reclaim: 0.0 ms][Free CSet: 0.0 ms][Eden: 9216.0K(9216.0K)->0.0B(14.0M) Survivors: 0.0B->2048.0K Heap: 9216.0K(192.0M)->1724.3K(192.0M)][Times: user=0.00 sys=0.00, real=0.01 secs] 然后我们来讲代码中的一个参数useCache设置成true再来看看:
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(MetaSpaceOverFlowTest.class);
enhancer.setUseCache(true);

此时我们看到元空间的内存占用很平稳。
enhancer.setUseCache(true); 设置成true,此时生成的类比较少。
会根据类的全限定名去判断,如果已经存在了,就不会再去创建了。
方法区调优
1、参数
-XX:MetaspaceSize=10m
-XX:MaxMetaspaceSize=10m
2、调优原则
1、最大、最小设置成一样大
2、程序运行起来后,通过visualVM、arthas查看占用了多少内存,向上调优,预留20%以上的空间
3、栈
问题:一个栈帧占多少内存?
我们测试的时候会发现,栈的深度是一直在变化的。
栈上分配
多大的对象会在栈上分配
栈溢出测试
package com.jihu.test.oom;public class StackOverFlowTest {private int val = 1;public void test() {val++;test();}public static void main(String[] args) {StackOverFlowTest stackOverFlowTest = new StackOverFlowTest();try {Thread.sleep(10000);} catch (InterruptedException e) {e.printStackTrace();}try {stackOverFlowTest.test();} catch (Throwable t) {t.printStackTrace();System.out.println(stackOverFlowTest.val);}}}
-------------------
第一次结果:
20540at com.jihu.test.oom.StackOverFlowTest.test(StackOverFlowTest.java:10)
----------------
第二次结果:at com.jihu.test.oom.StackOverFlowTest.test(StackOverFlowTest.java:10)
19219
从结果上我们可以看到,每次运行的结果都是不同的,这是因为有栈上分配存在的原因。
我们调整一下,将栈大小设置为250k. 继续测试:
-Xss250k------------------
栈深度: 2763
每个栈帧占多少字节:250 * 1024 / 2763Process finished with exit code 0四、调优工具
jps
1、jps
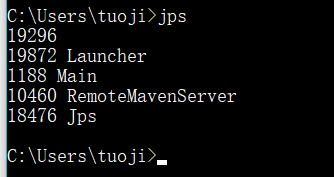
可以列出java进程和进程id,但是只有类名。
2、jps -l
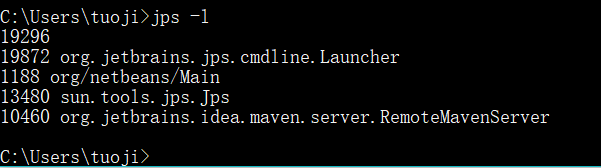
列出java进程,此时是类的权限定名。
3、jps -lmv

会列出更多的调优参数。
jps 实现原理
Java进程在创建的时候,会生成相应的文件,进程相关的信息会写入到该文件中。Windows下默认路径是C:\Users\username\AppData\Local\Temp\hsperfdata_username(注意,AppData是隐藏目录),Linux下默认路径是/tem/hsperfdata_username.
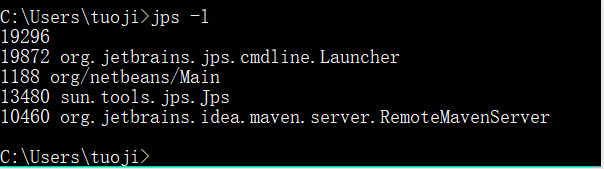

所以我们有时候命名kill了一个进程,但是使用jps命令依然可以查到,原因就是kill了之后非正常退出,文件没有被删掉。
jstat
Jstat是JDK自带的一个轻量级小工具。全称“Java Virtual Machine statistics monitoring tool”,它位于java的bin目录下,主要利用JVM内建的指令对Java应用程序的资源和性能进行实时的命令行的监控,包括了对Heap size和垃圾回收状况的监控。可见,Jstat是轻量级的、专门针对JVM的工具
使用时,需加上查看进程的进程id,和所选参数。参考格式如下:
jstat -options
可以列出当前JVM版本支持的选项,常见的有:
- l class (类加载器)
- l compiler (JIT)
- l gc (GC堆状态)
- l gccapacity (各区大小)
- l gccause (最近一次GC统计和原因)
- l gcnew (新区统计)
- l gcnewcapacity (新区大小)
- l gcold (老区统计)
- l gcoldcapacity (老区大小)
- l gcpermcapacity (永久区大小)
- l gcutil (GC统计汇总)
- l printcompilation (HotSpot编译统计)

jstat实现原理和jps是一样的,也会生成对应的文件。
这些命令工具我们熟悉一下即可,主要将工具VisualVM搞清楚。因为即使是线上,我们也是dump出gc日志,然后使用VisualVM来进行分析的。
Jstat实现原理
jstat输出的这些值从哪来的
PerfData文件
Windows下默认理解是C:\Users\username\AppData\Local\Temp\hsperfdata_username
Linux下默认路径是/tmp/hsperfdata_username
PerfData文件
1、文件创建
取决于两个参数
-XX:-/+UsePerfData
默认是开启的
关闭方式:-XX:-UsePerfData。如果关闭了,就不会创建PerfData文件
-XX:-/+PerfDisableSharedMem(禁用共享内存)
默认是关闭的,即支持内存共享。如果禁用了,依赖于PerfData文件的工具就无法正常工作了
2、文件删除
默认情况下随Java进程的结束而销毁
3、文件更新
-XX:PerfDataSamplingInterval = 50ms
即内存与PerfData文件的数据延迟为50ms
纯Java编写
\openjdk\jdk\src\share\classes\sun\tools\jstat\Jstat.java
Java Agent
其实就是进程attach,有两种实现方式:
1、命令行
程序没有启动时可以通过在命令行上指定javaagent的方式来启动代理
-javaagent:jarpath[=options]#如:
java -javaagent:xxx-agent.jar -cp xxx.jar com.wwh.xxxx
通过命令行的方式可以指定多个代理,并且支持参数。初始化Java虚拟机(JVM)之后,将按照指定代理的顺序调用每个premain方法,然后调用真正的应用程序main方法。每个premain方法必须返回,以便继续启动程序。
2、启动后attach
程序已经启动后可以通过VirtualMachine 来加载启动代理:
VirtualMachine vm = VirtualMachine.attach("2177");
vm.loadAgent(jar);
vm.detach();
注意:
代理JAR的manifest中必须包含属性 Agent-Class。此属性的值是代理类的名称。
代理类必须实现一个公共静态的 agentmain 方法,如下所示。
Java Agent(JVMTI Agent)是调优工具可以调试java进程的本质
五、实战
统计线程数
jstack -l 6972 | grep ‘java.lang.Thread.State’ | wc -l
死锁
可使用jstack、jconsle、visualVM
package com.jihu.test.oom;public class DeadLock implements Runnable {/*** 定义两个Object对象,模拟两个线程占有的共享资源* 此处需要注意的是,o1和o2 需要有static修饰,定义为静态对象,这样o1和o2才能在多个线程之间调用,才属于共享资源,* 没有static修饰的话,DeadLock的每个实例对象中的 o1和o2 都将是独立存在,相互隔离的,*/public static Object o1 = new Object();public static Object o2 = new Object();public int flag; // 属性,又叫成员变量public DeadLock(int flag) {super();this.flag = flag;}@Overridepublic void run() {if (flag == 1) {// 代码块1synchronized (o1) {System.out.println("one-1");try {Thread.sleep(1000);} catch (Exception e) {e.printStackTrace();}synchronized (o2) {System.out.println("one-2");}}} else {// 代码块2synchronized (o2) {System.out.println("two-1");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}synchronized (o1) {System.out.println("two-2");}}}}public static void main(String[] args) {//创建线程1,flag 属性值为1DeadLock deadLock1 = new DeadLock(1);//创建线程1,flag 属性值为2DeadLock deadLock2 = new DeadLock(2);//启动线程1和线程2/*** 线程1启动之后,调用顺序是* (1)执行代码块1,同时获取到o1对象锁,开始执行,线程沉睡1秒* (2)接着去获取o2的对象锁,由于第二个线程先获取的是o2的对象锁,所以需要等待代码块2执行完毕,才能获取到o2的对象锁*/new Thread(deadLock1).start();/*** 线程2启动之后,调用顺序是* (1)执行代码块2,同时获取到o2对象锁,开始执行,线程沉睡1秒* (2)接着去获取o1的对象锁,由于第一个线程先获取的是o1的对象锁,所以需要等待代码块1执行完毕,才能获取到o1的对象锁*/new Thread(deadLock2).start();/** 以上分析可得,线程一和线程二共用了对象o1和o2,各自都想要获取对方的锁,从而形成阻塞,一直等待下去,这种现象就是死锁。*/while (true);}}
使用VisualVM查看:


CPU占用过高
排查思路
1、找到进程
2、找到线程
3、分析代码
package com.jihu.test.oom;public class CPUHigh {public static void main(String[] args) {new Thread(new Runnable() {@Overridepublic void run() {while (true) {System.out.println("hi");}}}, "thread-couhigh").start();}
}可以使用top(linux)命令查看占用CPU较高的进程。类似于windows的任务管理器一样。

2、定位到目前占用CPU最高的线程ID
top -H -p 6290

线程ID由十进制转成十六进制
3、定位线程
jstack 6290(进程ID)|grep 18a1(线程ID,十六进制) -A 30
参考文章:https://www.jianshu.com/p/8be816cbb5ed
参考文章:https://www.jianshu.com/p/f5efc53ced5d
这篇关于TLAB、OOM、调优工具(实现原理)、调优实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





