本文主要是介绍阅读《A Comprehensive Survey on Deep Learning Techniques in Educational Data Mining》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
教育数据挖掘中的深度学习技术综述
- 摘要
- 引言
- 方法
- 监督学习
- 无监督学习
- 强化学习
- 1) Value Function Approach(价值函数法)
- 2) Policy Search Method(策略搜索法)
- 3)Actor-Critic算法
- 教育场景和相应算法
- A.知识追踪
- 1)监督学习
- 2)无监督学习
- 3)强化学习
- B.发现不良学生
- 1)监督学习
- 2)无监督学习
- 3)强化学习
- C.成绩预测
- 1)监督学习
- 2)无监督学习
- 3)强化学习
- D.个性化推荐
- 1)监督学习
- 2)无监督学习
- 3)强化学习
- IV.数据集和处理工具
- A.数据集
- 1)用于比赛的数据集
- a) ASSISTments
- b) KDD Cup 2010
- 2)来自在线教育平台的数据集
- a)Junyi Academy online learning活动数据集
- b) Canvas Network Dataset
- c) Learn Moodle
- d) XuetangX
- e)EdNet
- 3)开放数据存储库
- a)MOOCCube
- b)xAPI-教育挖掘数据集
- B. Processing Tools
- V. 未来方向
- A.学习分析和干预
- B.社会网络分析和协作
- C. EDM中的可解释人工智能
- D.用于教育的大型语言模型
- E.多模态学习分析
- F.基准数据集和评估指标
- G.公平和隐私
- VI. CONCLUSION结论
摘要
教育数据挖掘(EDM)已成为一个重要的研究领域,它利用计算技术的力量来分析教育数据。随着教育数据的复杂性和多样性的增加,深度学习技术在解决与分析和建模这些数据相关的挑战方面显示出显着优势。本调查旨在通过深度学习系统地回顾EDM的最新技术。我们首先简要介绍EDM和深度学习,强调它们在现代教育背景下的相关性。接下来,我们详细回顾了深度学习技术在四种典型教育场景中的应用,包括知识追踪、不良学生检测、成绩预测和个性化推荐。此外,还全面概述了EDM的公共数据集和处理工具。最后,我们指出了该研究领域的新兴趋势和未来方向。
引言
近年来,深度学习经历了显著的进步,彻底改变了包括教育在内的各种主要领域。深度学习是机器学习的一种形式,它依靠人工神经网络来促进层次特征的发现,从而增强了识别模式的能力[1]。与需要手动特征工程的传统机器学习方法相比,深度学习允许机器通过使用多层抽象来自动发现大数据中的复杂结构。这种分层的特征学习过程使深度学习模型能够学习数据中的复杂模式,并在语音识别、图像分类和自然语言处理等领域实现最先进的性能[1]。一般来说,深度学习领域存在三种主要的算法类别:监督学习、无监督学习和强化学习[2]。应用适合不同应用场景的深度学习算法可以大大提高它们的性能。随着计算能力的提高,深度学习在许多领域都取得了重大突破和突出成果。
传统的机器学习和深度学习算法已经彻底改变了教育领域,探索以前的研究是理解其应用的关键。目前在教育中使用的主要术语有两个,教育数据挖掘(EDM)和学习分析(LA)[3]。这两个领域是典型的交叉复合型,包括但不限于信息检索、数据分析、心理教育学、认知心理学等。 EDM包括计算机化技术和工具,有助于从教育环境中获得的广泛数据集中自动识别和提取有意义的模式和有价值的信息[4,5]。另一方面,LA涉及系统的收集,检查,和介绍有关学习者和他们的学习环境的数据[6]。将深度学习整合到教育场景中是由利用人工智能和机器学习潜力的愿望驱动的,从而丰富教学经验[1,7]。深度学习模型具有非凡的能力,使它们能够有效地处理和分析大量教育数据。通过揭示有意义的模式和做出准确的预测,这些模型提供了有价值的见解,可以告知和增强教育实践[8,9,10]。教育工作者和研究人员可以利用这些见解来调整教学策略,个性化教学,并优化学习成果。通过利用深度学习的力量,教育界可以通过智能数据处理和自适应方法释放新的机会,提高教育的效率、有效性和适应性[11]。此外,深度学习在完成EDM中的特定场景任务方面也取得了重大成就。目前,EDM场景通常分为:知识追溯(knowledge tracing)、不良学生检测(undesirable student detection)、成绩预测(performance prediction)和个性化推荐(personalized recommendation)。每个子领域都有不同的特定数据输入模式和任务需求。基于深度学习的知识追踪算法分为深度知识追踪(DKT)及其变体,例如基于记忆网络的DKT、注意力机制和图结构[8]。复杂的神经网络模型可以应用于学生辍学预测(SDP),这是一项不受欢迎的学生检测任务[12]。同样,神经网络也可以在性能预测的EDM场景中提供相当可靠的准确性[13]。在个性化推荐领域,基于混合技术的推荐算法可能正在逐渐占据主导地位,但新兴的隐私问题也需要密切关注[14]。
事实上,研究人员也一直在利用不同的传统机器学习算法在不同的教育环境中进行教育数据挖掘[15]。例如,由人工神经网络(ANN)和支持向量机(SVM)构建的TLBO-ML模型[16]可用于预测学生期末考试的成绩。然而,传统的机器学习算法有一定的局限性。这些传统模型通常依赖于手动特征工程,需要该领域的专家知识来设计有效的特征。这个过程可能既费力又耗时。此外,处理复杂和高维的数据,如教育环境中普遍存在的自然语言文本和多媒体内容,可能会对传统的机器学习方法提出挑战。
当应用于教育场景时,深度学习技术比传统的机器学习方法有许多优势。一个显著的优势是从原始数据中自动学习分层表示,消除了手动特征工程的需要。这种特性使得深度学习模型非常适合分析各种类型的教育数据,包括学生成绩数据、教育视频和基于文本的学习材料。深度学习模型检测数据中复杂联系和复杂模式的能力导致了更准确的预测和个性化的建议。一项研究[7]显示了明显的差异,该研究显示,在所有进行的实验中,大约67%的论文报告深度学习证明了与“传统”机器学习基线相比的卓越性能。
Data Collection Methodology Followings are rules we applied to include or exclude papers:
• Search terms: Deep Learning and Educational Data Min- ing are the two keywords mainly involved in our survey. In order to access more related publications, we also used specific educational scenarios as our search terms (e.g., knowledge tracing, performance prediction etc.).
• Search Sources: We searched for articles containing the above keywords through Google Scholar and downloaded the articles that matched the requirements from the cor- responding major databases.
• The articles we have studied include only high-level pub- lications from international conferences and top journals based on the application of Deep Learning to educational scenarios.
我们将收集到的论文按照其发表年限和相应的应用场景进行绘制,如图1所示,为了保证研究的前沿,可以看出基于深度学习的EDM自2018年以来已经出现。
相关工作:Chen等人[17]全面分析了深度学习在教育大数据挖掘领域的应用。它提供了深度学习算法的详细描述,并探索了它们在教育大数据方面的进步。他们还列出了基于深度学习的教具和考试工具的开发。此外,文章展示了已经在教育实践中实施深度学习的机构列表。同时,Zhang等人[18]对教育数据栏进行了全面概述,涵盖了一系列经典的深度学习模型,如堆叠自动编码器(SAE)、深度信念网络(DBN)和各种深度神经网络(DNN)。它进一步研究了为不同类型的教育数据量身定制的不同深度学习技术,包括大规模、异构、实时和低质量的数据。通过研究这些主题,本文为深度学习在教育数据分析中的应用提供了宝贵的见解,有助于推进数据驱动的教育研究和实践。
我们的贡献:在之前工作的基础上,我们在研究中取得了改进和进步。这项调查涵盖了各种最先进的研究,根据深度学习算法在教育环境中的应用对其进行分类。这些文章分为三类:监督学习、无监督学习和强化学习。此外,这些文章根据使用深度学习技术的特定教育场景进一步分类。这些场景包括知识追踪、不良学生检测、表现预测和个性化推荐。通过采用这种系统的方法,我们对深度学习和教育交叉领域进行的广泛研究进行了结构化和深入的分析。
本调查不仅总结了最新的深度学习算法,还包括对相关数据集和数据工具的讨论。通过对数据集和数据工具的全面分析,本调查的主要目的是让读者彻底了解在EDM中实施深度学习解决方案时的考虑因素和挑战。此外,我们提出了一些有希望在基于深度学习的EDM中进一步研究的领域。潜在的方向包括学习分析和干预、社交网络分析和协作、EDM中的可解释人工智能、教育大语言模型、多模态学习分析、基准数据集和评估指标、公平和隐私。
总之,深度学习在教育中的应用有可能彻底改变传统教学和学习的方式。通过利用深度学习的优势,教育工作者可以获得有价值的见解,做出基于数据的决策,并创造个性化的学习体验。这项调查旨在提供深度学习在教育中应用的综合概述,涵盖各种算法和教育场景,同时考虑可用的数据集和数据工具。
方法
近年来,深度学习已经成为一种可以应用于各个领域的最先进的技术。神经网络通过学习数据的特征来提取更高级别抽象特征的能力使得深度学习成为一种非常成功的方法。
深度学习是一种源于机器学习的技术。它模仿人脑神经网络的结构和工作模式。通过模型训练实现识别和分类任务。与传统的机器学习算法相比,深度学习能够处理更复杂的任务和数据集,这将带来更高的呈现和概括能力。深度学习的发展经历了许多阶段,从最初的DBN[19]到随后新兴的多层感知器(MLP)、卷积神经网络(CNN)、循环神经网络(RNN)等,这导致了今天我们关心和使用的深度学习。随着深度学习算法和计算能力的进步,深度学习已经广泛应用于图像识别、语音识别等领域。在本次调查中,我们将主要关注深度学习算法,这些算法有助于课程推荐、学生行为检测和知识追踪等教育场景。
我们将这些模型分为三个部分,即监督学习、无监督学习和强化学习,如表一所示。
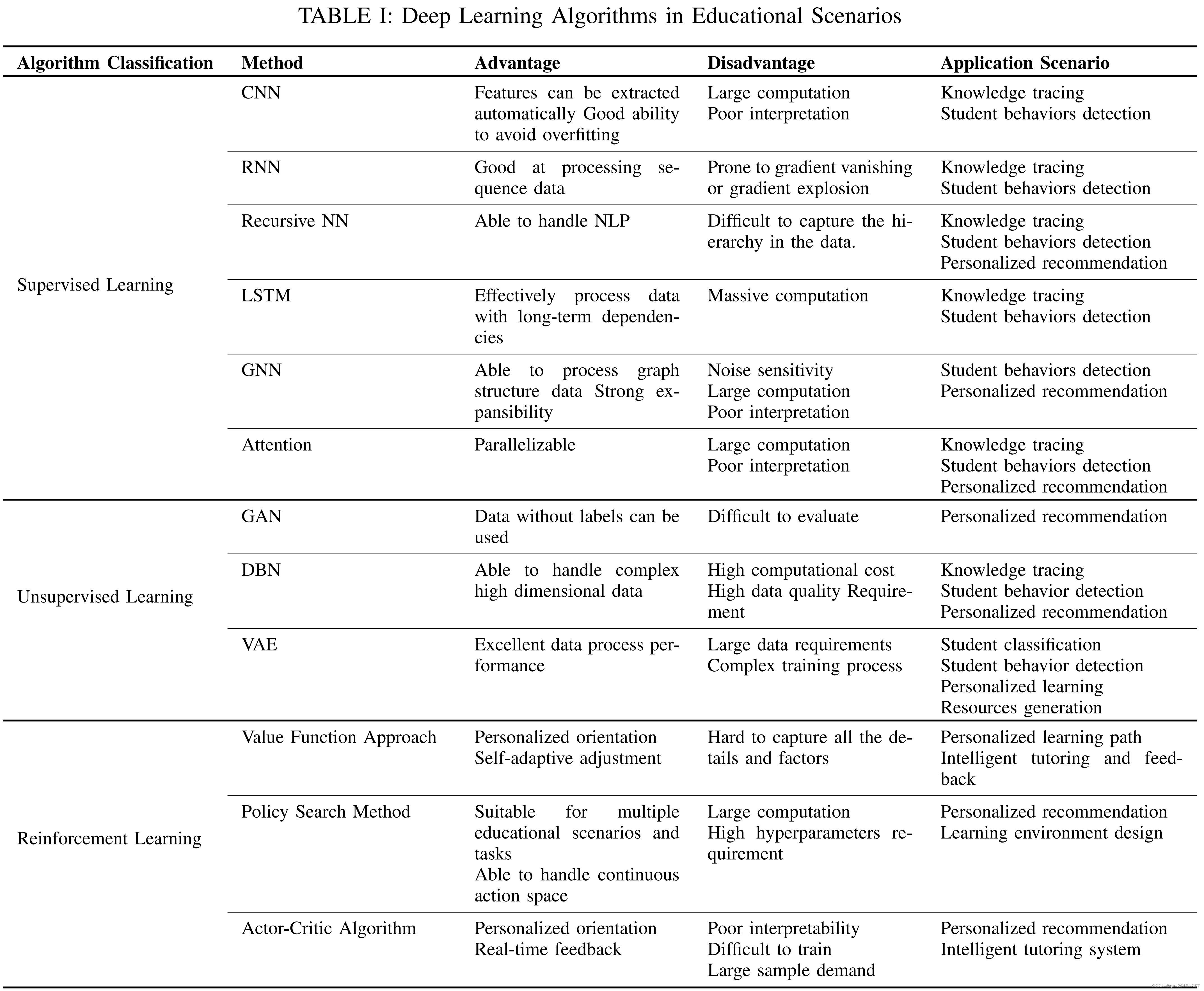
监督学习
大量标记历史数据的需求使得监督学习适合于knowledge tracing和 performance prediction,这些数据可用于训练监督学习模型,以建立输入和输出之间的映射,并预测学生的知识掌握和未来表现。
CNN是广泛应用于计算机视觉和图像处理领域的深度学习模型的代表性例子。CNN的理论是通过卷积和池化操作对图像进行提取、特征表示和降维。最后,将高维图像转换为一维向量数据,可用于分类和回归任务。值得一提的是,CNN的激活函数ReLU是一个非线性函数,有助于提高模型的非线性能力,帮助网络更好地学习特征。
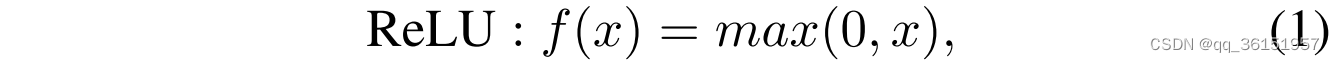
其中 x x x是指输入数据。在一定程度上,CNN可以用于知识追踪。Lyu等人[20]提出了一种基于时空深度表示学习的学习成绩预测深度知识追踪(DKT-STDRL)。在该模型中,CNN扮演着从学生练习序列中提取空间特征信息的角色。
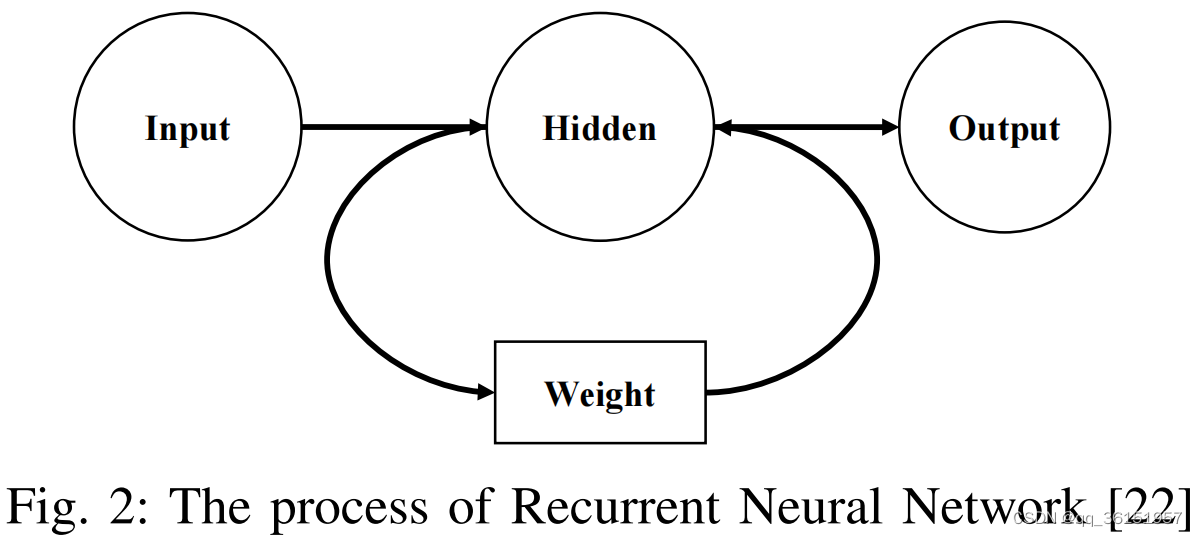
RNN主要用于处理各种应用中的顺序数据,例如文本和语音。RNN的神经节点能够接收以前的状态信息以实现记忆性。这一特殊属性允许RNN应用于知识跟踪、学生行为检测和类似的教育场景。以下是它能够实现循环的基本RNN方程:
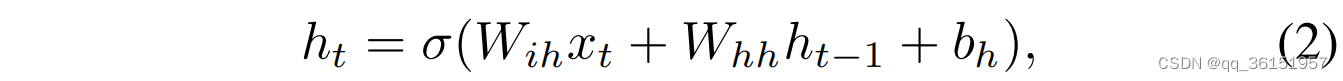 其中 x t x_t xt是输入向量, h t h_t ht是隐状态向量, W i h W_{ih} Wih和 W h h W_{hh} Whh是连接输入到隐状态和隐状态到隐状态的权重矩阵, b h b_h bh是偏置向量, σ σ σ是非线性激活函数。
其中 x t x_t xt是输入向量, h t h_t ht是隐状态向量, W i h W_{ih} Wih和 W h h W_{hh} Whh是连接输入到隐状态和隐状态到隐状态的权重矩阵, b h b_h bh是偏置向量, σ σ σ是非线性激活函数。
图2简单地展示了RNN的工作过程。同样由于RNN的特殊性质,当隐藏数据不断积累时,很难获得早期信息。在此基础上,Piech等人提出了一个用RNN实现的深度知识追踪模型(DKT)[21]该DKT模型采用了大量的人工神经元向量来表示潜在的知识状态和时间动态,最终证明与之前的知识跟踪基准中的最优结果相比,准确率提高了25%。
长短期记忆(LSTM)是一种特殊的RNN,它包含三个门单元和一个存储单元。顺序数据的存储和处理是通过门控单元对信息流的控制来实现的。遗忘门是LSTM控制前一刻的存储单元状态是否被遗忘的关键部件,如公式3[23]所示。
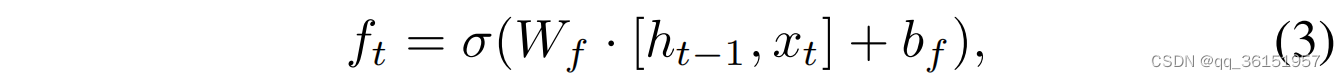
其中 f t f_t ft表示遗忘门的状态, W f W_f Wf是权重矩阵, [ h t − 1 , x t ] [h_{t−1}, x_t] [ht−1,xt]表示前一个时刻的输出和当前时刻的输入之间的连接, b f b_f bf是偏置向量, σ σ σ是 s i g m o i d sigmoid sigmoid函数。
图神经网络(GNN)是一种用于处理图像数据的深度学习模型。GNN经常被应用于检测学生行为和推荐课程,因为它利用图结构中节点和边的信息进行计算,最终学习和推导节点和边的特征。以递归GNN为例,节点隐藏状态的递归更新公式可以通过[24]
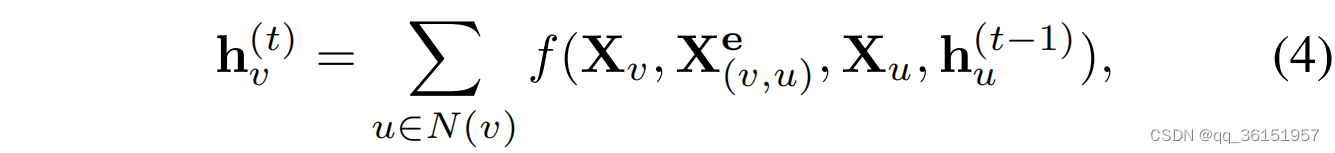
其中 f f f表示参数函数, h u ( t − 1 ) h^{(t−1)}_u hu(t−1)随机初始化。 X v X_v Xv表示节点 v v v的特征向量, X ( v , u ) e X^e_{(v, u)} X(v,u)e表示节点 ( v , u ) (v, u) (v,u)的边向量。
知识增强用户表示(KAUR)[25]模型由于其出色的图处理能力,应用GNN获得协作知识图谱(CKG)中特定节点的初始表示,用于消息聚合和传播。
递归神经网络(Recursive NN)是一种能够对自然语言进行建模的神经网络。它使用自下而上的方法将输入句子表示为向量,可用于情感分析和语言翻译等各种任务。Recursive NN的核心原理是基于树形结构的递归计算。这种结构允许将学习组件表示为树,节点包含多个概念或知识点。通过对这些节点的迭代计算,网络能够以持续的方式更新其知识状态。
注意力主要用于增强模型的专注度和对关键信息的理解,核心思想是根据任务需求为输入的不同部分分配权重,让模型有选择地关注特定信息。典型的自注意机制可以用以下公式表示: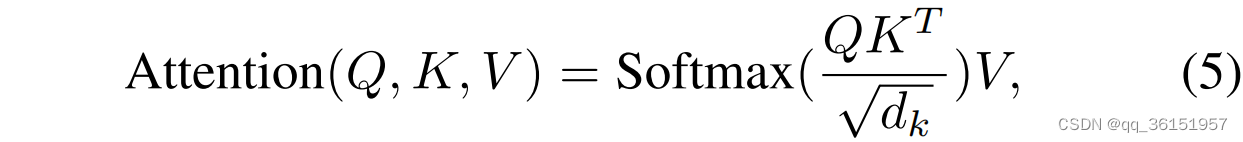
其中 Q Q Q表示从查询打包的矩阵, K K K表示键, V V V表示值, d k d_k dk是键维。通过计算查询和键之间的相似度并对其进行归一化,计算注意力权重分布并最终用于对总和值进行加权以获得最终表示。基于注意力的网络[26],省去了递归和卷积操作。它可以并行训练并获得更好的性能。
无监督学习
无监督学习是解决不良学生检测的好方法,因为这项任务更多地依赖于发现学生行为数据中的潜在模式和聚类结构,而不需要显式标记。无监督学习可以通过聚类、降维等技术识别学生群体之间的差异,发现行为异常的学生。
生成对抗网络(GAN)是生成神经网络和判别神经网络的结合。GAN的目标是学习和生成类似于真实数据的样本,并且具有高度的多样性。判别器的损失函数如下所列: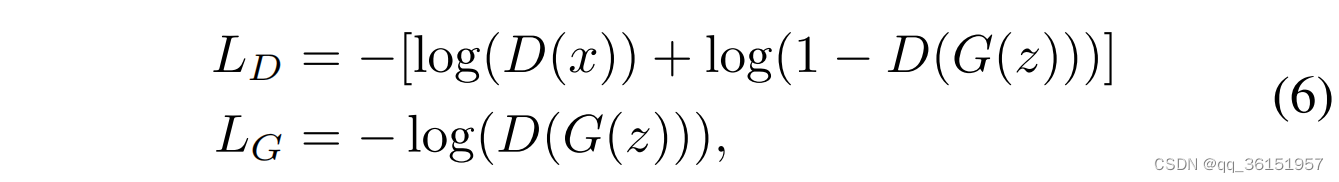
其中 x x x表示真实样本, D ( x ) D(x) D(x)是判别器对真实样本的输出, G ( z ) G(z) G(z)是生成器生成的样本, 1 − D ( G ( z ) ) 1-D(G(z)) 1−D(G(z))是判别器对生成样本的输出。同样,生成器的损失函数如下, z z z是从噪声分布中得到的随机样本, G ( z ) G(z) G(z)是生成器生成的样本, D ( x ) D(x) D(x)是判别器对样本 x x x的输出。
GAN在教育场景中最常见的用途是个性化推荐,因为它能够生成样本。例如,Bharadhwaj等人[27]引入了一个循环生成对抗网络(RecGAN),该网络利用定制的GRU从短期/长期时间配置文件中获取用户和项目的潜在特征。通过评估,这种方法提高了推荐项目的相关性。
DBN是由多个受限玻尔兹曼机(RBM)组成的DNN。变分自动编码器(VAE)也是一种无监督学习模型。它是基于自动编码器的生成模型。它们都可以应用于实现知识跟踪、学生行为检测、个性化推荐等。玻尔兹曼分布公式[28]是DBN中用于计算描述隐藏层和可见层之间联合分布关系的条件概率分布的核心公式: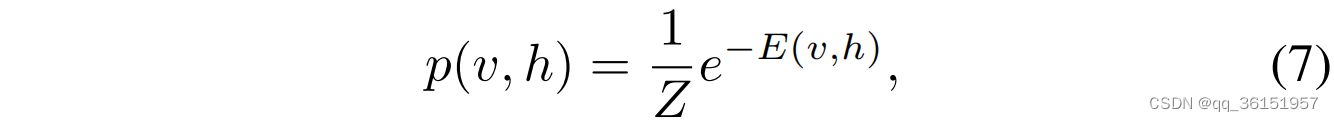
其中 v v v表示可见层的状态, h h h表示隐藏层的状态, E ( v , h ) E(v,h) E(v,h)表示能量函数, Z Z Z是归一化常数。
在VAE中,基于小批量的边际似然下界估计[29]可以表示为: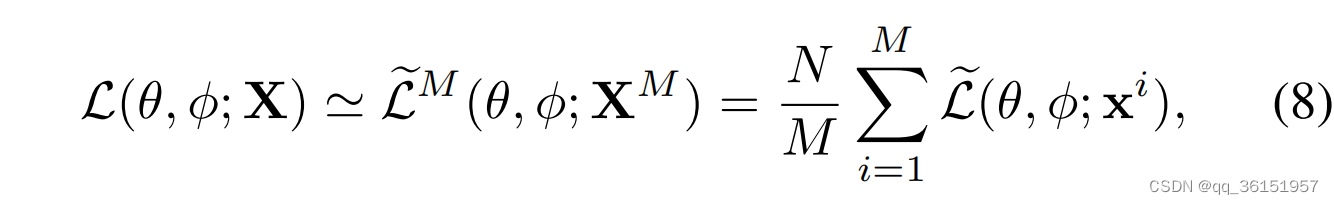
其中 θ θ θ和 φ φ φ是VAE模型中的两组参数,分别控制编码器和解码器的结构和参数。 X X X为训练集,其中每个样本 x i x^i xi为 D D D维向量, i i i为样本的索引, N N N为数据集中样本的总数, M M M为VAE中使用的小批量大小,即一次从数据集中随机选择的样本数。
此外,DBN更适合分类任务,而VAE更适合生成任务。例如,Zhang等人[30]提出了一种用于大规模在线教育的深度信念网络(DBNLS)模型,用于识别和分类学生之间的各种学习风格。该模型结合DBN来检测和学习个别学生的学习风格,并借助反向传播神经网络(BPNN)对其进行微调。
强化学习
与有监督和无监督学习相比,强化学习中使用的训练数据传统上是通过智能体与其环境的交互生成的。因此,强化学习适用于个性化推荐,这是一项智能辅导任务,它允许模型动态交互并持续调整推荐策略以最大化长期奖励。它可以根据实时用户反馈优化推荐有效性。
在强化学习[31]中,智能体通过观察环境的状态来采取特定的行动,并根据环境给予的奖励或惩罚来评估其行为,智能体的目标是优化累积奖励。
1) Value Function Approach(价值函数法)
Value Function Approaches是指算法通过获得最佳动作来实现全局最优收益的能力。即最优增益是通过最优策略 π ∗ \pi ^ * π∗下的最优动作 a ∗ a^* a∗产生的,该策略可以用Bellman最优性方程表示: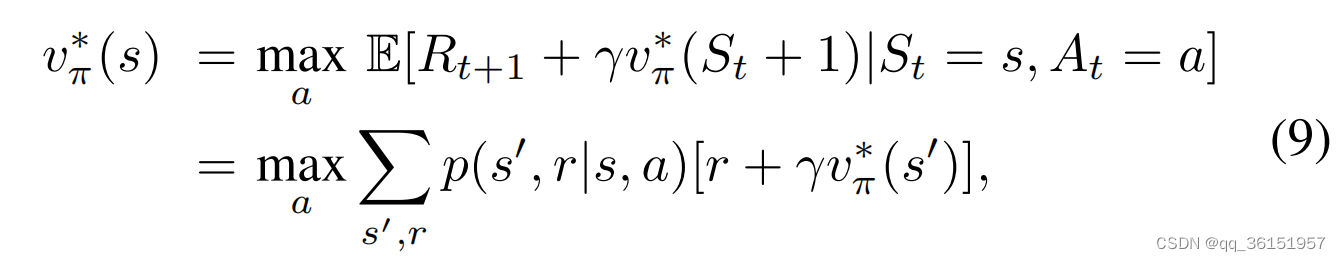
其中 E [ ⋅ ] E[·] E[⋅]表示在当前状态 s s s和采取行动 a a a的情况下,对下一个状态的奖励 R t + 1 R_{t+1} Rt+1和值函数 γ v π ∗ ( S t + 1 ) γv^{ *}_{π}(S_t+1) γvπ∗(St+1)的期望。
value function考虑长期利益的能力允许模型做出更明智的决策,而不仅仅是局部的即时奖励。然而,某些value function方法的解决可能需要更长的时间才能达到收敛。特别是在复杂的环境或大规模问题中,可能需要更多的迭代和样本来获得准确的value function估计和最优策略。
2) Policy Search Method(策略搜索法)
策略搜索方法在受一组策略参数 θ t θ_t θt影响的策略直接优化中最大化理论收益。例如,基于梯度的策略搜索方法使用梯度上升法,该方法通过迭代更新策略参数来最大化相对于参数 θ θ θ的策略性能 J J J,该方程可以简单地表示为: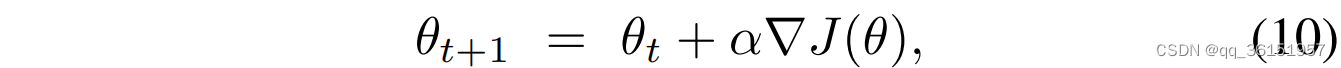
其中 θ t + 1 θ_{t+1} θt+1是指在时间 t + 1 t+1 t+1时的策略参数, ∇ J ( θ ) \nabla J(θ) ∇J(θ)是基于 θ t θ_t θt的策略性能的梯度。 α α α是控制每个参数更新步长的学习率。
除了基于梯度的策略搜索算法,还有一种基于蒙特卡罗策略梯度的方法称为RE-INFORCE,用于优化强化学习中的策略。它通过蒙特卡罗采样估计策略梯度,并使用梯度上升方法更新策略参数。具体而言,REINFORCE算法可以通过以下等式实现: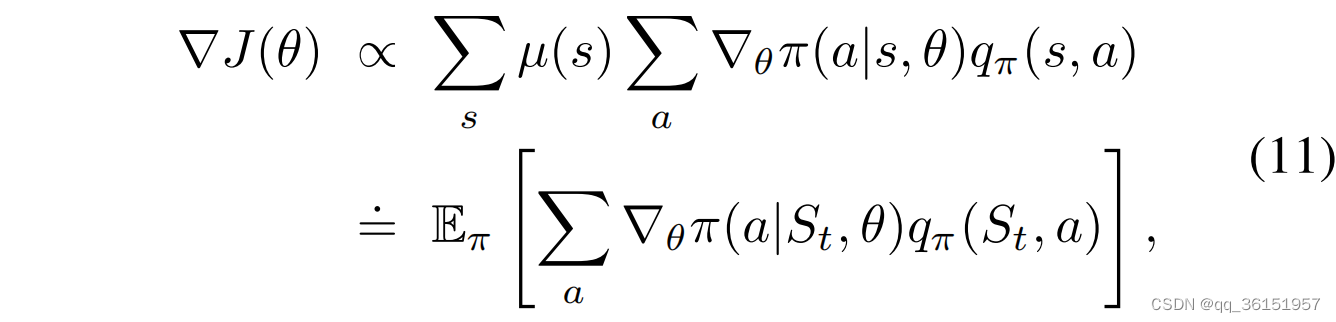
∝ ∝ ∝表示“与成比例”, μ ( s ) μ(s) μ(s)在策略 π π π下称为”on-policy”。 q π ( s , a ) q_π(s,a) qπ(s,a)是指策略 π π π在状态 s s s中选择动作 a a a的value function。
3)Actor-Critic算法
Actor-Critic算法是一种强化学习算法,用于解决未知环境下学习最优策略的问题。Actor-Critic算法的核心思想是通过Critic提供的价值函数估计来指导Actor的策略改进,而Critic根据当前策略和环境交互数据估计状态或状态动作对的价值,然后根据当前策略和环境交互数据评估策略的优劣。以一步Actor-Critic算法为例, θ θ θ更新的方程可以表示为: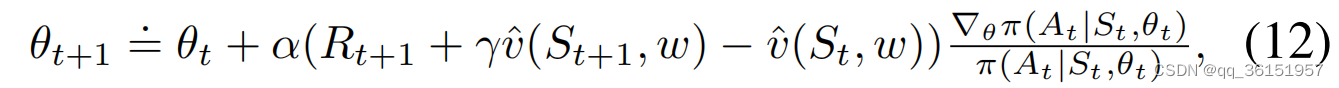
其中 R t + 1 R_{t+1} Rt+1表示时间 t + 1 t+1 t+1的奖励。 γ γ γ是控制未来奖励重要性的折扣因子。 v ^ ( S t , w ) \hat{v}(St, w) v^(St,w)指Critic了解到的状态value function,将作为基线。
教育场景和相应算法
为了全面概述不同应用场景的DL文献,我们在表II中包含了每篇论文中针对四个教育场景使用的算法和模型的信息。该表还列出了每项研究中采用的评估指标和数据集。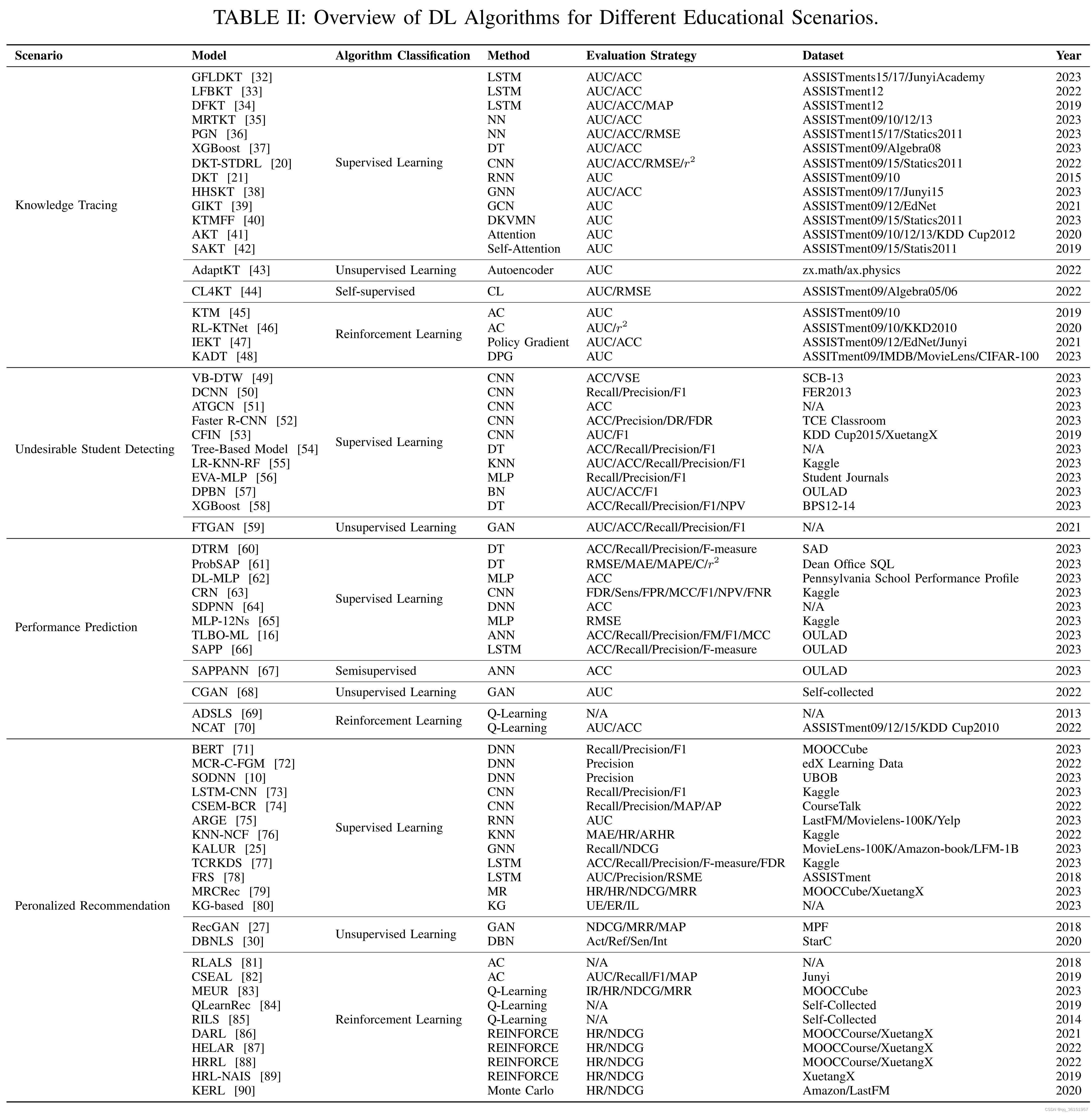
A.知识追踪
知识追踪是一种跟踪学生学习过程并预测其知识点数量的教育评估技术。在知识追踪场景中,通常记录学生的学习过程,包括学习时间、答案状态、作业完成情况等。
根据Song等人[8]在先前的研究中提出,智能教育系统中的知识追踪问题涉及三个主要元素:学生 S S S、练习 E E E和相应的知识概念 C C C。这些元素之间的交互 X X X是此类系统中的主要活动。具体来说,给定一个学生的历史练习交互 s ∈ S s \in S s∈S,其中每个交互 X t ∈ X X_t \in X Xt∈X对应一个练习 e ∈ E e \in E e∈E,并表示在步骤 t t t得到的结果的正确性 a t ∈ { 0 , 1 } a_t \in \{ 0,1\} at∈{0,1},知识追踪任务旨在预测特定概念 c ∈ C c \in C c∈C[8]的下一个交互 X t + 1 X_ {t+1} Xt+1。
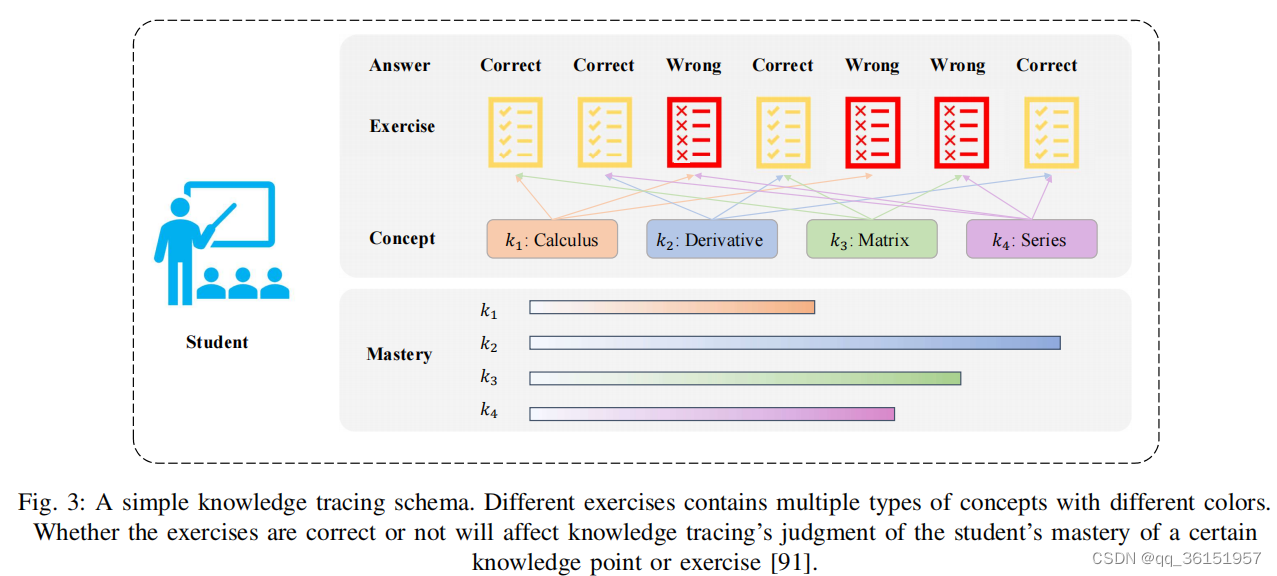
一个简单的知识追溯图式如图3所示,学生在某一习题中对某一特定知识点的正确率,可以影响模型对学生对该知识点熟练程度的判断,如图3中,学生对衍生知识点的正确率为100%,因此他/她对该知识点的掌握程度远高于其他知识点。
1)监督学习
监督学习在知边跟踪领域的应用主要集中在各种神经网络上,如LSTM、CNN、GNN和RNN。
其中,LSTM主要通过管理学生的遗忘和学习行为来更新知识状态,从而实现知识追踪。赵等人[32]提出了一种基于LSTM的GFLDKT模型,该模型采用门控遗忘和学习机制来有效更新知识状态,并促进对后续学生反应的准确预测。
此外,Nagatani等人[34]提出了考虑学生遗忘过程的DFKT模型。具体而言,DFKT应用LSTM和神经分解机(NFM),前者用于将学生的知识状态表示为低维密集向量,后者结合学生的知识状态和其他相关信息,包括相关的遗忘数据,来预测学生的表现。
Lyu等人[20]引入了DKT-STDRL模型,利用CNN从学生的学习序列中提取空间特征,LSTM处理时间特征。
知识图谱(KG)是知识边缘追踪的重要组成部分,因为它解释了学生的学习历史和特定专业领域之间的相互作用。通过利用KG的力量,模型可以更准确地捕捉不同知识点之间的学习轨迹和相互作用。Yang等人[39]提出了一种基于图的知识追踪交互模型(GIKT),该模型利用高阶问题-技能相关性解决了数据稀疏性和多技能挑战,从而提高了模型性能。
此外,Ni等人[38]提出了一种基于异构图的HHKST算法,该算法利用基于GNN的基特征提取器(BFE)从异构图中提取交互和知识结构特征。
作为一种为处理顺序数据而设计的神经网络架构,RNN在知识追踪领域也占有重要地位。DKT[21]利用大量来自RNN的人工神经元来构建知边跟踪模型。主要贡献是引入了一种将学生交互编码为RNN输入的新方法,并将AUC改进到一定水平。
在知识追踪中,探索了注意力机制的应用。Ghosh等人[41]引入了一种称为上下文感知注意知识跟踪(AKT)的方法,该方法将灵活的DNN与启发式认知和心理测量模型相结合。所提出的注意力机制用于根据学习者的上下文信息动态调整预测。这种注意力的集成允许模型根据每个学习者的特定背景调整其预测。
此外,Pandey和Karypis[42]提出了自我关注知识追踪模型(SAKT),该模型利用自我关注机制来识别和预测学生对特定知识点的掌握水平。经验结果表明,SAKT优于传统方法和基于RNN的模型,在一个数量级上实现了显着更快的性能。
2)无监督学习
事实上,无监督学习在该领域的应用相对较少。他的是因为无监督学习需要处理大量的未标记数据,而在知识追踪中通常只有有限数量的标记数据,使得使用无监督学习方法训练准确的模型变得困难。然而,近年来,随着深度学习的快速发展,一些研究人员开始探索无监督学习在知识追踪中的使用。
例如,Cheng等人[43]提出了一种基于自动编码器的DKT,它结合了知识追踪和迁移学习。这里的自动编码器用于将问题文本转换为高级语义嵌入。此外,该模型还应用LSTM和注意力机制来捕捉学生的知识状态,并通过Softmax预测学习者的下一个答案。
3)强化学习
强化学习是在没有预先标记数据的情况下,通过学生做出的决策和行为进行奖励或惩罚来学习学生的知识状况和水平。知识追溯中的学习过程可以被认为是一个顺序决策问题,学生需要根据不同的知识点做出不同的决策,这可能会影响未来的学习过程。
Ding等人[46]考虑到一些监督学习,如LSTM或GRU,受NLP的影响很大,不是专门为知识追踪而设计的。因此,作者设计了一种RL-KTNet算法,采用强化学习自动生成用于知识追踪的循环神经网络单元。它在性能方面优于使用LSTM单元的模型。
此外,Long等人[47]提出了一种名为个体估计知识追踪(IEKT)的模型,该模型结合了强化学习进行辅助模型训练。具体来说,Long等人使用策略梯度和ε-贪心来更新模型参数。此外,强化学习被用来估计学生的知识状态和对知识获取的敏感性。
B.发现不良学生
在当今时代,传统和在线教育系统都产生了大量数据。从这些海量数据中提取有用的知识和潜在模式可以使决策者通过识别不利的学生行为[12]和预测学生表现来加强教学。这些教育数据可以被认为是一个宝贵的信息来源,可以促进数据驱动的教育研究和创新。
目标是识别不良学生的行为,如低动机、低参与度、作弊、辍学和拖延[92]。图4显示了一个简单的不良学生检测过程。
1)监督学习
监督学习在该领域的应用相对多样,除了神经网络如CNN,决策树、K-最近邻(KNN)和贝叶斯网络也有应用。
受益于CNN优越的图像处理能力,邱等人[51]提出了一种基于CNN的ATGCN模型来检测学生在课堂上的不良行为,例如午睡等。
此外,song等人[54]介绍了一种基于树的模型,该模型应用if-then-else规则来检测学生辍学的概率。该论文采用三种分类器模型,即决策树、逻辑回归和SVM。
在分类模型方面,Chi等人[55]提出了一个包含Logistic回归、KNN和随机森林的LR-KNN-RF模型。从学习者自身特征和学习行为分析MOOC的辍学率。实验结果是随机森林在三种分类算法中表现最好。
此外,史等人[57]提出了一种基于贝叶斯网络(BN)的DPBN模型。该模型通过可变信息和剪枝构建,还通过最大似然估计(MLE)生成参数。模型是相对可解释的,因为它可以证明单个特征对辍学率的影响。
冯等人[53]提出了一种上下文感知特征交互网络(CFIN)模型,用于预测MOOC中的用户辍学行为。CFIN模型结合了上下文平滑技术来增强不同上下文中的特征值,并采用注意力机制在建模框架内整合用户和课程信息。随后,作者展示了该模型的非凡性能。
2)无监督学习
除了类似于上述分类模型并通过聚类行为检测学生不当行为的K-means算法之外,还有一种无监督学习可以应用于该领域。
Stenton等人[59]引入了FTGAN,即Fine-TuningGAN来预测学生的流失率。作者证明,GAN分类器模型训练的时间越多,其准确性就越显示出一定程度的提高。
3)强化学习
强化学习可能不是预测学生辍学率或检测不良行为的最合适方法,原因有两个:
- 学生的行为往往受到许多因素的影响,如社会文化背景、家庭环境和个人情况,这些因素很难用简单的状态和行为来描述。
- 导致辍学结果的学生行为的奖惩难以界定,例如,不良学生行为可能在短期内受到某种奖励,但在长期内导致辍学,这使得强化学习难以有效处理。
因此,本文没有收集强化学习检测学生不良行为的文献。
C.成绩预测
成绩预测[13]是指使用各种数据和分析技术来预测学生在特定任务或领域的表现,如考试成绩、学习成绩、课程完成率等。它与知识跟踪任务的区别在于,成绩预测侧重于根据历史学习数据预测学生未来的整体任务或考试成绩,而知识跟踪侧重于学生在学习过程中对特定知识概念的理解和掌握。
通过预测学生的表现,教师和教育机构可以更好地了解学生的学习和需求,以便提供更有效的支持和指导。预测还可以帮助学生了解他们的表现和潜在困难,并采取措施改善学习成果。
此外,认知诊断[93]是一个相关的概念,其目的是通过分析学生在练习记录上的表现来确定他们在特定知识领域的掌握水平。这种分析有助于为他们的后续学习提供量身定制的指导[94,95]。相比之下,表现预测更侧重于预测学生在考试中的总分。前者分析知识维度,而后者强调一般能力。认知诊断输出概念熟练程度,而表现预测直接预测总分。
1)监督学习
监督学习算法可以为教师和学生提供有用的信息,帮助他们更好地理解学生的表现和需求。除了支持向量机等经典算法之外,深度学习模型如MLP、有线电视新闻网、循环神经网络、LSTM和DNN已经被应用于预测学生在各种教育环境中的表现。
Nayani等人[63]引入了一种称为CRN的混合模型,该模型结合了CNN和Recurrent NN来预测学生的成绩,并通过银河骑士群优化(GRSO)算法调整超参数来提高性能。
决策树作为预测模型的鲁棒性归因于其决策机制,即只有当超过一半的决策树(DT)产生不正确的判断时,输出预测才被认为是错误的。陈和丁[60]对七个不同模型的预测性能进行了比较分析,这使他们得出结论,决策树在所有评估数据集中表现出值得称赞的泛化水平。
此外,Neha等人[64]提出了一个SDPNN模型,应用基于DNN的线性分类器来预测学生的学业成绩。有两个隐藏层,定义了300个神经元。激活函数是ReLU和Softmax。
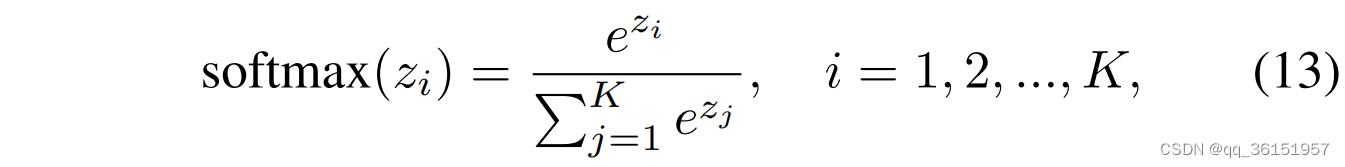
其中 z i z_i zi表示输入向量的第 i i i个元素, K K K是类别的数量。
Kukkar等人[66]提出了一种利用四层堆叠LSTM、随机森林和梯度提升的SAPP系统。这里的LSTM用于提取特征,而随机森林和梯度提升用于预测。所提出的系统具有96%的准确率,并且在一定程度上表现良好。
2)无监督学习
虽然成绩预测通常依赖于标记数据集进行监督学习,但一些无监督学习算法(如GAN)也可以用于成绩预测任务。GAN可以通过以学生的历史成绩为输入,使用生成器和判别器生成未来成绩的预测值来进行成绩预测。生成器可以使用学生以前的成绩和其他相关因素来生成未来成绩的预测,判别器用于确定生成的预测是否与真实成绩相似。
Sarwat等人[68]提出了一种结合条件GAN(CGAN)和基于深层的SVM的模型,根据学校或家庭辅导来预测学生的成绩。CGAN用于生成成绩分数数据以解决数据集规模小的问题,实验表明使用CGAN和SVM组合的模型对预测结果有积极影响。
3)强化学习
一般来说,强化学习不适合学生成绩预测。然而,强化学习可以根据学生行为设置奖励策略来优化学生的学习路径。在这种情况下,强化学习还需要评估学生当前的表现,并以预测优化的表现为目的。
Dorcça等人[69]提出了一个自动检测和精确调整学生学习风格的ADSLS模型。其中一个重要部分是该模型预测和评估学生在某一点上的表现,并在更新学习策略的同时奖励表现。结果证明了所提出方法的有效性和效率。
庄等人[70]介绍了一个利用强化学习来提高电子测试系统有效性的NCAT模型。NCAT模型采用深度强化学习,根据给定条件动态优化测试术语。通过所提出的算法,电子测试系统可以提供更全面、更准确的性能预测。
D.个性化推荐
在当前在线信息爆炸式增长的时代,推荐系统[14]无疑提供了一种有效的手段来解决这个问题并为个人用户提供必要的帮助。即使在教育领域之外,推荐系统仍然是研究最广泛的技术方法之一。 Zhang等人[96]给出了推荐系统的详细定义,即:假设存在 M M M个用户和 N N N个项目,我们将交互矩阵和预测交互矩阵分别表示为 R R R和 R ^ \hat{R} R^。用户对项目 i i i的偏好表示为 r u i r_{ui} rui,而预测分数表示为 r ^ u i \hat{r}_{ui} r^ui。还会有两个部分观察到的向量,一个代表特定用户 u u u,即 r ( u ) = { r u 1 , … , r u N } r^{(u)}= \{r^{u1},…, r^{uN} \} r(u)={ru1,…,ruN}。另一个代表一个特定的项目 i i i,即 r ( i ) = { r 1 i , … , r M i } r^{(i)}= \{r^{1i},…, r^{Mi} \} r(i)={r1i,…,rMi}
在教育场景中,项目被替换为教育资源,如课程。课程推荐系统的主要目标是在时间 t + 1 t+1 t+1向用户推荐最合适的课程,考虑到他们过去的学习活动和时间t之前的学习者概况。这种推荐系统面临的主要挑战是通过分析用户数据精确描述和概念化用户倾向来提供个性化推荐[97]。图5展示了个性化推荐的简单模式。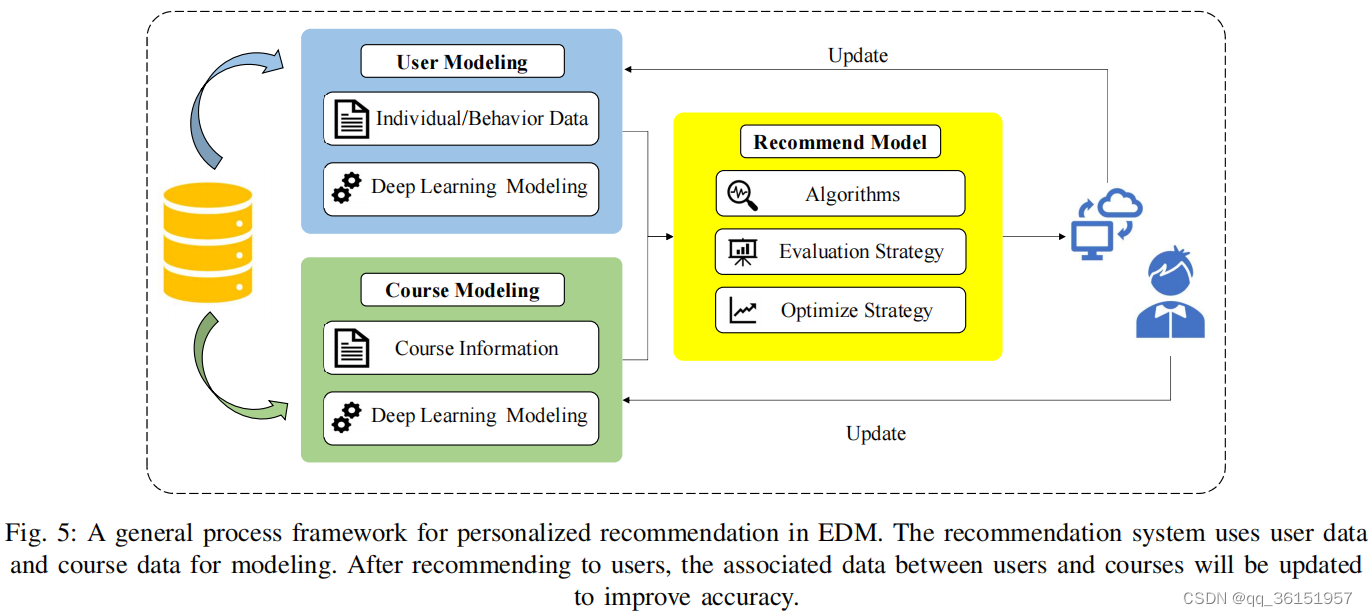
1)监督学习
监督学习在课程推荐中的应用[72]集中在各种各样的神经网络模型上,由于神经网络具有更大的灵活性和表现力,可以更好地处理用户行为序列和非线性特征。同时,神经网络可以自动从数据中提取特征,以更准确地预测用户在推荐过程中的兴趣。
一些优化的神经网络模型在个性化推荐领域发挥作用,SODNN,一种由同步序列、异构特征和DNN组成的新颖模型已被Safarov等人[10]引入,同时,为了解决冷启动问题,即推荐系统初始化过程中由于缺少用户数据而导致的大错误,作者尝试通过连接附加特征来克服。
此外,经典神经网络也可以应用于推荐系统。与传统的正序建模方法相比,高等人[74]提出了一种采用负序建模的新型CSEM-BCR模型。具体而言,该模型将课程学习序列构建为负序模式,其中负序项是指学生不应不当选择或操作课程的原则。然后使用CNN对负序模式进行特征学习处理,为每个用户生成推荐课程列表。该方法为个性化推荐提供了一个全新的视角,并为向具有不同需求和偏好的学习者推荐课程的问题提供了一个潜在的解决方案。
KG是个性化推荐的重要组成部分。它可以有效解决推荐系统中的稀疏问题。赵等人[75]提出了一种基于多路径RNN编码器的ARGE模型。该模型解决了传统RNN不考虑路径之间关联进行编码的问题,实验结果中的AUC和精度证明了该模型能够有效解决用户和项目之间稀疏交互的问题。
GNN作为一种专门用于处理图结构的神经网络模型,也被许多学者应用于处理推荐系统。Ma等人[25]提出了一个KAUR模型,该模型应用GNN来学习协作KG中每个节点的节点表示。该模型将传播的节点信息及其相邻节点信息视为正对比对,然后利用对比学习来提高节点表示的质量。
周等人[78]提出了基于LSTM的全路径推荐系统(FRS)和聚类算法。聚类算法用于根据学习者相似的学习特征对学习者进行分类,这反过来又有助于根据先前的结果对学习路径进行分类。因此,这种方法有效地解决了冷启动问题。LSTM用于预测学习性能,如果结果不令人满意,系统将根据用户的个人学习特征为用户选择最相关的学习路径。
除了不同种类的神经网络,其他监督算法也可以用于个性化推荐,例如,Jena等人[76]引入了基于KNN的KNN-NCF模型。KNN在这里用于对具有不同注释的课程进行聚类,以优化输出。
2)无监督学习
在推荐系统中,用户偏好和行为往往是不完整和不准确的,标记数据收集起来非常困难和昂贵。在此基础上,无监督学习是实现个性化推荐的重要手段。无监督学习可以从用户的历史行为中提取潜在的兴趣和偏好,并通过聚类推断用户的相似性和兴趣相关性,特征学习来实现个性化推荐。
Bharadhwaj等人[27]引入了基于GAN和Recurrent NN的混合RecGAN模型。生成器和鉴别器都是用基于GRU的Recurrent NN构造的。然后允许生成器与鉴别器玩一个Mini-Max博弈,即在时间索引 t t t中存在一个真实的分布 D r e a l ∣ t D_{real|t} Dreal∣t,以及生成器 D g e n ∣ t D_{gen|t} Dgen∣t生成的概率分布。这个minimal-maximization博弈的目标是最小化生成器的生成误差,同时最大化鉴别器区分虚假评级和真实评级的能力。
无监督学习还可以应用于对不同类型的学习风格进行分类,以便向不同的群体推荐最合适的教育资源。张等人[30]提出的基于DBN的DBNLS模型用于检测和分类学习风格。DBNLS的核心组件是多层RBM和反向传播网络层,其中反向传播用于拟合DBNLS模型并对DBN进行微调和训练。
3)强化学习
强化学习在个性化推荐中的应用具有很高的研究价值和发展前景,强化学习算法可以根据学生的反馈学习最优推荐策略以提高推荐效果,并且可以基于不同的评价指标进行优化,如推荐准确率、召回率、覆盖率等。
Liu等人[82]提出了一种自适应教育的认知结构增强框架CSEAL,以实现个性化的学习路径推荐。该框架将学习路径视为马尔可夫决策过程(MDP),并应用actor-critic为个体学习者识别合适的学习项目。CSEAL综合考虑了学习者的知识水平和学习项目的知识结构。实验结果表明,与当前的自适应教育方法相比,CSEAL可以提高学习者的效率。
梁等人[83]提出了一种基于图卷积网络和强化学习的MEUR模型。作者将学习过程视为一个MDP。应用以用户为中心的推理方法,通过actor-critic算法最大化累积奖励 G G G, G G G定义如下: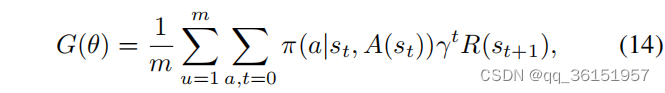
其中 θ θ θ是Actor网络的参数, m m m是样本数, u u u是样本指数, a a a和 t t t是时间步长和动作指数, π ( a ∣ s t , A ( s t ) ) π(a|s_t,A(s_t)) π(a∣st,A(st))是在状态 s t s_t st中选择动作 a a a的概率, R s t + 1 R_{s_t+1} Rst+1是在状态 s t + 1 s_{t+1} st+1中获得的即时奖励, γ γ γ是调谐参数。
值得一提的是,用户的学习过程是动态的,这也假设了该用户对课程的兴趣可能随着认知水平的提高而改变,基于此,Lin等人[86]提出了一种能够在交互中自动捕捉用户偏好并更新相应课程的注意力权重的DARL,具体而言,在模型中加入了动态注意力机制,实验结果展示了该方法的有效性、适应性和时间成本优势。
注意力机制也有其他用途。例如,当用户注册了多个课程时,识别最相关的历史课程以帮助预测用户真正感兴趣的课程变得很有挑战性。为了解决这个问题,Lin等人[88]引入了一种HRRL算法,该算法应用了基于注意力的推荐系统和循环强化学习(RRL)。通过在训练期间共享用户配置文件的嵌入,该模型能够重建用户配置文件,从而提高推荐系统的准确性。
然而,注意力机制也有缺点,例如当用户同时对多个课程感兴趣时,推荐模型的准确性会下降。因此,Zhang等人[89]提出了一种用于修改用户配置文件的HRL-NAIS算法。具体来说,该模型分析和识别历史课程,并去除嘈杂的历史课程以修改用户配置文件。之后,代理从环境中获取延迟奖励并相应地修改策略以实现更准确的推荐。
Wang等人[90]提出了一种KG强化学习课程推荐算法KERL,该算法将顺序推荐任务形式化为MDP,并提供复合奖励函数。该模型已在四个真实世界数据集上被证明是有效的。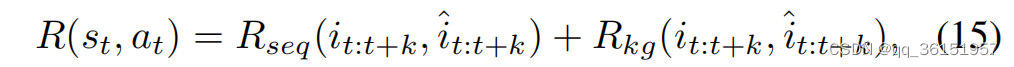
其中函数 R s e q ( ⋅ , ⋅ ) R_{seq} (·, ·) Rseq(⋅,⋅)和 R k g ( ⋅ , ⋅ ) R_{kg} (·, ·) Rkg(⋅,⋅)分别用于计算序列级和知识级的奖励。这些函数将基本事实子序列 i t : t + k i_{t:t+k} it:t+k和推荐子序列 i ^ t : t + k \hat{i}_{t:t+k} i^t:t+k作为输入,并近似 k k k步周期内的整体性能。
IV.数据集和处理工具
A.数据集
为了更全面地概述教育环境中常用的公共数据集,我们精选了一些数据集,如表III所示。该表改编自Romero等人的论文[114]和Mihaescu等人的论文[116]。这些数据集已广泛用于各种教育研究,并为该领域的进步做出了重大贡献。表III提供了关于每个数据集的基本信息,包括其名称、URL、描述、应用场景和应用文献。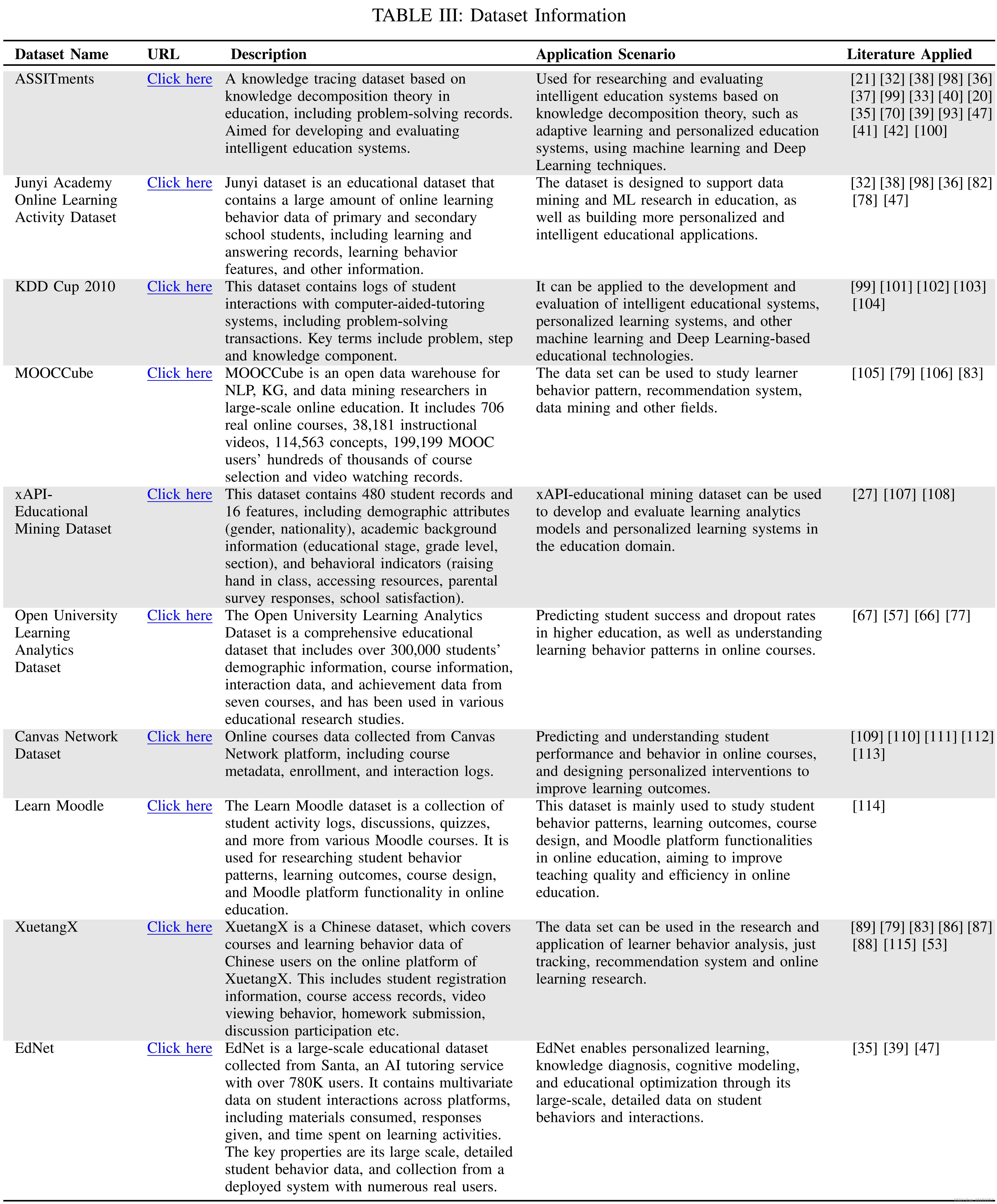
我们将收集的数据集按来源分为三类:用于比赛的数据集、来自在线教育平台的数据集和开放数据存储库。
1)用于比赛的数据集
a) ASSISTments
ASSISTments数据集有许多版本,如Assis ment 2009、2012和2017,这些版本已被用于多个教育数据挖掘竞赛,以促进教育技术和学习分析的研发。最著名的竞赛之一是ASSISTments数据挖掘竞赛。
b) KDD Cup 2010
该数据集用于KDD杯2010教育数据挖掘挑战赛,该挑战赛要求参与者使用所提供数据集中包含的学生交互日志来训练新的学习模型,并最终根据他们的模型预测学生对新问题的反应的准确性来判断结果。因此,该数据集也被广泛用于知识跟踪等问题。
2)来自在线教育平台的数据集
a)Junyi Academy online learning活动数据集
该数据集来自Junyi Academy online learning平台,该平台为学生提供个性化的学习资源和支持。该数据集包括2018年8月至2019年7月一年内超过72,000名学生在平台上超过1600万次练习尝试的记录。
b) Canvas Network Dataset
Canvas Network数据集源自Canvas Network平台,该平台为教育机构和教育工作者提供创建和交付在线课程的工具和资源。数据集包含大量课程信息以及用户交互日志等。
c) Learn Moodle
Learn Moodle源自Moodle学习管理系统,这是一个广泛使用的开源在线学习平台,支持教育机构和教师创建、管理和提供在线课程。
d) XuetangX
XuetangX数据集来源于在线教育平台XuetangX。它是中国著名的在线教育平台形式,成立于2013年,提供MOOC等在线学习资源、视频观看行为、作业提交和讨论参与等。
e)EdNet
EdNet是一个由Santa收集的广泛教育数据集,Santa是一个基于人工智能的在线教学平台,在韩国拥有780,000名用户群。它包含了两年的学生学习行为数据,并提供了大量关于学生-系统交互的信息,包括知识边缘跟踪、认知过程、学习分析数据和学生在线学习活动的全面记录。
3)开放数据存储库
a)MOOCCube
MOOCCube是面向大规模在线教育相关的自然语言处理、KG、数据挖掘研究人员的开放数据存储库,包含706门真实在线课程、38181个教学视频、114563个概念、199199名MOOC用户的数十万次课程选择、视频观看记录,以及包含数十万与课内概念相关的学术论文资源的补充存储库,概念描述数据来自百度和维基百科,课程数据和学生行为数据来自XuetangX,学术论文数据来自大型学术搜索引擎Aminer.
b)xAPI-教育挖掘数据集
xAPI-教育挖掘数据集是指基于体验应用编程接口(xAPI)标准的数据集。xAPI是一种开放的学习技术规范,用于记录各种学习环境中的学习者行为和交互数据。表中的链接指向存储在Kaggle上的公开xAPI兼容数据库学生学业成绩数据集,其中包含480个样本,具有16个特征。
B. Processing Tools
在教育场景中处理和分析教育数据的常用工具有很多,为教育研究人员和教师提供有力的支持和洞察力。本节将重点介绍几种具有代表性的工具,包括LOCO-Analyst、Datashop、SNAPP、GISMO和Meerkat-ED等。这些工具在教育数据处理中具有独特的功能和特点,可以帮助教育从业者更好地理解学习过程并优化教学设计和实践。通过使用这些工具的组合,教育研究人员和教师可以深入分析学生学习行为、参与度和学习成果的数据,并从中获得有价值的见解。表IV中提供了这些工具的名称、链接和详细描述。该表改编自Romero等人的论文“教育数据挖掘和学习分析:更新调查”[114]和Romero等人的论文“教育中的数据挖掘”[117]。
V. 未来方向
深度学习在EDM中显示出巨大的前景。基于深度学习的EDM中成功的技术可以为改进教学、学习和评估提供有价值的见解。以下是使用深度学习的EDM成功技术的几个潜在见解:
A.学习分析和干预
现有的EDM方法通常涉及离线分析。未来的工作可以研究实时学习算法的使用,例如深度强化学习[118]或实时重新当前学习算法[119],为响应更快的教育环境提供及时的见解和干预。此外,我们可以将多任务学习[120]与注意力机制相结合,分析来自学习管理系统或其他教育平台的学生交互数据,提供知识跟踪和选项跟踪[121]到管理和学习模式中。多任务学习还可以用于识别有学业困难和辍学风险的学习者,从而允许早期干预和支持。
B.社会网络分析和协作
通过直接从图结构和节点特征中学习,GCN可以捕捉社交网络中的复杂模式,帮助分析教育环境中的社交网络,揭示学生之间的协作和交流模式。这些见解可以帮助教育工作者更有效地设计小组活动和作业,或者识别可能从额外支持或社会参与机会中受益的学生。此外,未来的工作应该鼓励计算机科学家、教育工作者和心理学家之间的合作。虽然这个方向并不关注特定的算法,但它强调了跨学科知识在改进现有算法或为EDM开发新算法方面的重要性。例如,为了在教育环境中为用户提供跨领域的建议,我们可以使用偏好感知图注意力网络[122],它利用协作KG来捕捉域内和跨域的用户偏好。
C. EDM中的可解释人工智能
鉴于与深度学习模型相关的“黑匣子”问题,应努力创建更透明和可解释的模型。.尤其是在EDM中,使这些模型可解释和透明变得越来越重要,因为教育通常非常强调事物的科学性和因果关系。未来的研究可能旨在开发或改进生成模型预测的可理解解释的方法,例如,用于学生成绩预测中使用的可解释模型的深度学习重要特征(DeepLIFT)[123],以及用于可解释推荐系统的局部可解释模型无关解释(LIME)[124]或KG。此外,对于涉及顺序数据的应用程序,例如随着时间的推移研究学生与学习管理系统的交互,LSTM或GRU等模型可以通过可解释性功能得到增强。为此,序列解释方法,例如分层相关传播(LRP)[125],可用于解释顺序学习模式。
D.用于教育的大型语言模型
大型语言模型(LLM)[126]正在改变包括EDM在内的许多领域。它们理解、生成和完成文本的能力使它们成为教育中有价值的工具。例如,LLM可以用来生成针对每个学习者需求、兴趣和熟练程度的个性化教育内容。为此,我们可以专注于在特定教育数据集上微调LLM,如GPT-4,以在这些任务中获得更好的性能。此外,LLM可以帮助创建先进的智能辅导系统(ITS)[127],该系统可以理解并以适合上下文的方式响应学生的查询。未来的工作应该将LLM整合到现有的ITS中,并检查它们对学生学习成果的影响。有趣的是,基于GPT的架构[128,129]被用于自动评分学生论文或评估书面答复,这可以减少教育工作者的工作量并提供一致的评估。这样的架构也有能力分析和理解学生的语言使用,使教育工作者能够识别学生甚至教师在理解或交流方面遇到困难的领域。
E.多模态学习分析
许多当前的EDM方法主要依赖于结构化数据。然而,教育经验产生了大量的非结构化和半结构化数据(例如,图像、音频、视频,甚至生物特征数据),这些数据提供了对学生学习经历更全面的理解。深度多模态学习算法[130]结合了图像/视频数据的CNN、时间数据的RNN或LSTM以及文本数据的变形金刚,可以用来利用这些丰富的信息。这些见解可以为多模态学习环境和干预措施的设计提供信息,适应不同的学习风格和偏好。
基于多模态学习的上述表示,多模态情感计算和情感识别可能是EDM的一个有前途的方向。为此,我们需要精心设计的模型来分析学生的面部表情、言语或生理信号,以推断学习活动中的情绪状态和参与度。通过这种方式,他们帮助教育者调整他们的教学策略,以更好地满足学生的情感需求,并提高整体学习体验。例如,混合对比学习[131]可用于多模态情感分析,其中半对比学习和模态内/模态间对比学习从跨模态交互中学习多种关系。
F.基准数据集和评估指标
目前,EDM缺乏普遍接受的基准数据集。未来的工作应侧重于创建涵盖教育过程各个方面的大型、多样化和有代表性的数据集。这项任务可能涉及数据采集和预处理、数据匿名化(出于隐私考虑)甚至合成数据生成方法等技术。生成模型(例如GAN)可能有助于创建合成教育数据,从而在确保学生隐私的同时保持真实世界数据的统计属性。此外,EDM的不同研究通常采用不同的评估指标,因此很难比较不同研究的结果。未来的工作应该旨在定义和标准化评估指标,以有效反映EDM深度学习模型的性能。例如,深度元学习[132]可用于评估和比较不同算法在EDM任务上的性能。自动搜索给定任务的最佳机器学习基准的AutoML框架[133]也可用于识别EDM中特定数据集或任务的最合适算法。
G.公平和隐私
处理学生数据将伦理考虑和隐私问题置于首位。首先,确保EDM模型不会延续或放大偏见是一个巨大的挑战。未来的工作可以集中在开发和实施公平算法上,例如监督学习中的机会平等[134],这有助于识别和纠正预测模型中的偏差。此外,研究可以旨在改进训练数据和结果中的偏差检测技术。其次,为了保护学生的隐私,隐私保护数据挖掘技术的开发和应用应该是一个重点。Differential privacy[135]是一种为数据或查询结果添加噪声以确保无法重新识别单个记录的框架,它提供了一种有前途的方法。例如,我们可以采用Differential Privacy Stochastic Gradient Descent (DP-SGD)[136]或Private Aggregation of Teacher Ensembles(PATE)[137]来训练模型,而无需直接访问敏感数据。最后,未来的工作可以探索联邦学习算法[138]在EDM的实施和优化。它可以在本地数据上进行模型训练,而无需与中央服务器共享,从而保护学生信息。
综上所述,虽然深度学习已经在EDM展示了其潜力,但仍有大量令人兴奋的进一步探索和创新的机会。通过关注上述未来方向,我们希望促进该领域的巨大进步,为教育实践的转变和教育体验的改善做出贡献。
VI. CONCLUSION结论
深度学习算法已广泛应用于各个领域,它们在EDM辅助提高现代教育质量方面显示出巨大潜力。在本次调查中,我们首先对基于深度学习的EDM的现状进行了广泛的概述,重点介绍了应用于四种主要教育场景的三类深度学习(即无监督学习、监督学习和强化学习)。此外,我们还设计了知识跟踪模式、不良学生检测模式和个性化推荐框架,直观地展示了它们的原理。其次,详细介绍了EDM的公共数据集和处理工具。最后,为了在这一领域提供创新和改进的新机会,我们提出了一些有希望的未来方向。这项调查旨在激发进一步的研究、合作和进展,以扩大深度学习EDM的应用范围。
这篇关于阅读《A Comprehensive Survey on Deep Learning Techniques in Educational Data Mining》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








