本文主要是介绍论文阅读-Uncertainty-aware Propagation Structure Reconstruction for Fake News Detection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文链接:https://aclanthology.org/2022.coling-1.243.pdf
目录
摘要
1 简介
2 相关工作
3 问题陈述
4 拟议模型
4.1 概述
4.2 原始传播建模
4.2.1 图的构建
4.2.2 在原始传播图中学习远程交互
4.3 重建传播模型
4.3.1 高斯传播估计
4.3.2 重建传播图中的重新学习潜在相互作用
4.4 假新闻检测和训练
5 实验
5.1 数据集
5.2 实验设置
5.3 比较方法
5.4 假新闻检测结果
6 讨论
6.1 消融研究
6.2 与不同原始传播建模模块的比较
6.3 参数分析
6.4 传播深度分析
6.5 案例研究
7 结论
摘要
假新闻的广泛传播具有有害的社会影响。最近的工作将信息传播建模为图结构,并从用户交互中聚合结构特征以进行假新闻检测。
gap: 然而,他们通常忽略了更广泛的传播不确定性问题,这是由实际传播过程中一些缺失和不可靠的相互作用引起的,并且受到学习准确和多样的结构特性的影响。
model: 在本文中,我们提出了一种新的基于双图的模型,不确定性感知传播结构重建(UPSR),用于改进假新闻检测。
具体来说,在原始传播建模之后,我们引入了传播结构重建,以充分探索实际传播中的潜在相互作用。
我们设计了一种新颖的高斯传播估计,以通过多个高斯分布改进原始确定性节点表示,并以多方面的方式在分布之间产生与 KL 散度的潜在交互。
efficiency: 在两个真实世界的数据集上进行的大量实验证明了我们模型的有效性和优越性。
1 简介
如今,假新闻已对个人和社会造成不利影响。例如,由于将 COVID-19 与 5G 技术联系起来的阴谋论,电信塔被烧毁(Ahmed 等人,2020 年)。为了帮助减轻假新闻造成的负面影响,开发自动检测假新闻的方法至关重要。
前人研究:
现有作品通常利用社交媒体对话线程中的用户交互(例如,转推)和共享内容来检测假新闻。此类工作背后的关键原则是社交媒体上的用户分享观点、猜想和证据,以检查假新闻。
最近的研究(Ruchansky et al., 2017; Ma et al., 2016) 按时间顺序扁平化对话以从传播序列中捕捉语言和时间特征,这并没有更好地利用网络属性。
一些作品(Ma 等人,2018 年;Kumar 和 Carley,2019 年;Khoo 等人,2020 年;Ma 和 Gao,2020 年)使用树结构构建对话线程,以捕获信息传播交互中的结构模式。
在图神经网络 (Kipf and Welling, 2017) 成功的推动下,最近的方法 (Bian et al., 2020; Hu et al., 2021; Lin et al., 2021) 将对话线程视为图结构和聚合信息丰富的邻居学习一个好的检测表示。
gap描述:
然而,大多数方法通常假设传播结构在某个点是确定的和完整的。在现实世界中,由于个人隐私保护和利益驱动的社交机器人等各种原因,通常每个样本都描述了一部分传播结构,其中包括一些缺失和不可靠的交互(Shao 等人, 2018)。这一事实导致传播不确定性问题,并使得发现用于假新闻检测的有效结构模式具有挑战性。
Wei等 (2021) 学习了关系偏差,以减轻不可靠交互的负面影响。但是他们只关注推文与其直接转发之间的相互作用。
因此,他们仍然忽略了一些不相关但可能具有相似立场的潜在交互,这些交互有助于揭穿虚假信息。社交媒体对话线程中这些重要但缺失的潜在交互也是驱动传播不确定性问题的关键。
因此,如何对传播不确定性问题进行建模并学习有效的结构-属性是增强假新闻检测的实际研究课题。
方法介绍:
一种直观的方法是重建原始传播结构以捕获发布节点之间所有可能的交互。我们认为,在传播中,许多转发会在潜意识中相互促进(例如相似的立场或情绪)。Hu等人 (2021); Lin等人 (2021) 已经显示了来自同一推文的兄弟转发之间的隐性交互的正收益。超出他们的假设,我们尝试调查传播结构中所有帖子的更多潜在交互,而不仅限于兄弟转推。此外,以前的工作(Wei et al., 2021; Hu et al., 2021; Lin et al., 2021)通常通过学习每条推文的确定性嵌入来测量交互,这可能不足以准确描述潜在的交互和全面的不确定传播。因此,需要研究来自多个潜在方面的潜在交互,这可以反映他们的模糊立场、情绪和其他因素。
在本文中,我们调查了由缺失和不可靠的交互引起的更广泛的传播不确定性问题。
针对这个问题,我们开发了一种新的基于双图的模型,称为不确定性感知传播结构重建(UPSR),以自适应地学习准确和多样化的结构特性。
具体来说,受 Chen (2020)等人的启发。我们首先利用深度图卷积网络对原始传播中的远程交互进行完全建模;
然后,我们设计了一种新颖的高斯传播估计来从多个高斯分布中采样节点表示,而不是直接使用确定性节点表示进行重建,其中协方差使模型能够减少噪声交互;
我们以多方面的方式测量分布之间的 Kullback-Leibler (KL) 散度,以更新传播结构。
基于重建的图,我们应用根感知图卷积网络来根据学习到的潜在交互来聚合特征。
UPSR 的双图结构不仅可以在原始传播中学习准确的结构信息,还可以在重建传播中捕获不同的结构模式。最后,我们利用双图表示来识别假新闻。
我们对两个真实世界的公共数据集进行了广泛的实验。实验结果表明,UPSR 明显优于最先进的模型,表明假新闻检测的有效性。本文的核心贡献总结如下:
为了处理由缺失和不可靠关系引起的更广泛的传播不确定性问题,我们提出了一种新的不确定性感知传播结构重建(UPSR),以学习准确和多样化的结构属性,用于假新闻检测。
我们设计了一个高斯传播估计(GPE)来通过测量转发的不同高斯分布之间的 KL 散度来重建潜在的传播结构。
我们在两个真实世界的基准数据集上评估模型。实验结果证明了所提模型的有效性和优越性。
2 相关工作
在文献中,一些作品(Jiang et al., 2019; Shu et al., 2019b; Mishra, 2020; Nguyen et al., 2020)利用用户特征来辅助检测。由于很多情况下不允许记录用户信息,我们主要关注基于文本和传播的假新闻检测。
基于文本的假新闻检测方法 (Mihalcea and Strapparava, 2009) 强调通过提取文本特征来调查新闻内容的真实性。早期的作品依靠特征工程来捕捉文本特征,例如主题特征(Castillo 等人,2011 年)、写作风格和一致性(Popat,2017 年;Potthast 等人,2018 年)。深度学习出现后,许多工作(Ma et al., 2016; Ruchansky et al., 2017; Karimi and Tang, 2019)应用各种神经网络自动从源新闻及其转发信息中学习丰富的语义或句法特征以检测假新闻。
基于传播的假新闻检测方法利用与新闻文章传播相关的信息。许多实证研究(Vosoughi et al., 2018; Jang et al., 2018)表明,与真实新闻相比,假新闻具有更深层次的传播结构,覆盖面更广。舒等 (2019a) 共同学习了评论的顺序效应以及源新闻与相应评论之间的相关性。为了捕捉结构传播模式,Ma 等人 (2016) 构建了一个树结构的神经网络来模拟传播结构。 Khoo 等人。 (2020) 采用 Transformer (Vaswani et al., 2017) 来学习长距离交互。最近,Bian 等人(2020) 将传播视为图,并应用两个图卷积网络 (GCN)(Kipf 和 Welling,2017)2761 从两个不同的有向图中学习结构模式。胡等 (2021);林等 (2021) 进一步探索了传播图中的多关系交互。魏等(2021, 2022) 专注于传播不确定性并学习鲁棒结构特征。
现有模型的差异。 1)上述基于图的模型(Bian et al., 2020; Hu et al., 2021)是浅层结构,限制了探索更深层次传播中的潜在相互作用。受 Chen 等人的启发 (2020),我们堆叠更多的图层来探索传播中的远程交互。 2)大多数方法在静态传播树/图上学习潜在的结构特征。它们可能很容易被缺失和不可靠的行为所干扰,从而导致更广泛的传播不确定性问题。本文设计模块来重建原始传播并从多个方面探索更多潜在的交互。
3 问题陈述
形式上,设 G = (V, E) 是一个传播结构,其中 V = {r, c1, ..., cN} 是表示源新闻 r 及其转推 c1, ..., CN.E指的是一组明确的交互行为,例如转发。将源新闻 r 的嵌入定义为 r ∈ Rd0,转推 ci ∈ Rd0 的嵌入,其中 d0 是文本特征的维数。每个传播都用真实标签 yi ∈ {0, 1} 注释。
我们将假新闻检测问题表述为二元分类问题,即每个样本可以是真实的 (yi = 0) 或假的 (yi = 1)。假新闻检测任务可以看作是从标记集中学习分类器 f,即 f : G → y
4 拟议模型
在本节中,我们提出了一种新颖的基于双图的模型 UPSR,以完全模拟原始传播中的远程依赖关系,并在相应的重构传播中探索丰富的潜在依赖关系。
4.1 概述
UPSR 的总体架构如图 1 所示。首先,给定输入文本和传播结构,我们应用深度图卷积来学习原始传播中的远程交互。为了更好地缓解传播的不确定性问题,我们设计了一种高斯传播估计来重建传播,以发现更多潜在的相互作用。然后,基于重建的传播,我们进一步在潜在连接的指导下聚合节点特征。最后,连接原始传播和潜在传播中编码的节点表示以进行假新闻分类。
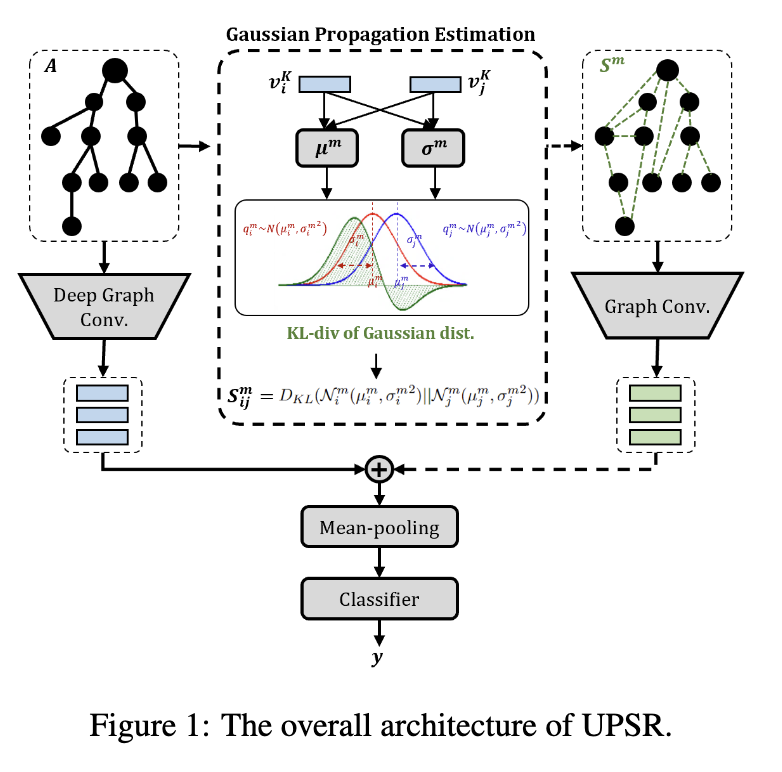
4.2 原始传播建模
Vosoughi 等人。(2018) 已经证实,假新闻比真相传播得更远、更深、更广。因此,对传播中的远程交互进行建模对于区分假新闻和真新闻至关重要。受 (Chen et al., 2020) 的启发,我们开发了一个深度图卷积网络来捕获原始传播中的远程交互。
4.2.1 图的构建
首先,我们为每个传播结构构建一个无向图,以全面聚合双向交互。形式上,传播结构可以表示为无向图 G = (V, E),其中 V 表示一组推文节点,包括源新闻 r 及其转推 c1, ..., cn。 E是一组传播行为。如果两个节点之间存在边,即 Aij = 1,则边权重设置为 1。
4.2.2 在原始传播图中学习远程交互
陈等 (2020) 通过引入初始残差连接和恒等映射来改进传统的图卷积网络,以启用堆叠多个图层,这在最近的下游应用程序中显示出有前途的性能(Hu et al., 2022。
对于信息传播,Vosoughi 等人 (2018);张等人 (2018) 表明,与真实新闻相比,假新闻具有更深层次的传播结构,覆盖范围更广。因此,我们在无向图上应用深度图卷积网络 (Chen et al., 2020),以充分捕获原始传播中两个节点之间的这种远程依赖关系。
给定无向图 G = (V, E),第 k 层的图卷积定义为等式(1)。
第一层 的残差连接被添加来表示
并且恒等映射
被添加到权重矩阵
。
使用输入嵌入进行初始化,即
。
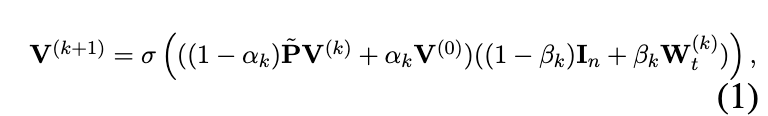
其中 是重归一化图拉普拉斯矩阵(Kipf 和 Welling,2017)。
A是图G的原始邻接矩阵。D是对角度矩阵,I是单位矩阵。αk, βk 是两个超参数。
在实验中,αk = 0.1 使节点表示至少包含输入特征的一部分,即使我们堆叠了很多层。
令 βk = log( η/k + 1) 以确保权重矩阵的衰减在堆叠更多层时自适应增加。
η 也是一个超参数。 是第 k 个权重矩阵。 σ 表示激活函数。
基于上述修改,我们可以堆叠许多图层来捕获原始传播中的远距离连接,并为后续重建的传播建模提供更准确的节点表示。 我们将图层数表示为 K,将最终节点表示表示为
4.3 重建传播模型
为了探索不同的结构模式,我们重建原始传播以寻找更多潜在的相互作用,然后对重建的传播图进行编码以改进检测。
4.3.1 高斯传播估计
我们设计了一个高斯传播估计(GPE)来从多个方面重建原始传播。GPE模块不是直接测量每个推文的原始确定性嵌入,而是从多个高斯分布生成样本随机节点表示。它可以准确、全面地描述不确定传播的潜在相互作用。
形式上,给定每个节点 vi 的确定性嵌入 ,不确定性感知节点表示被定义为估计均值
和估计方差
参数化的分布估计,
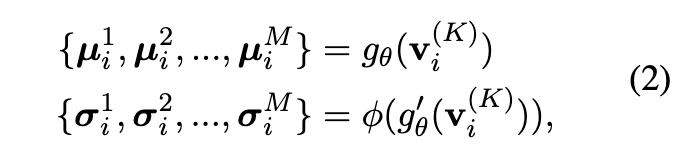
其中 M 是一个参数,表示用于估计节点不确定影响的方面的数量。 gθ 和 g′ θ 是两个可训练的神经网络,例如多层感知 (MLP)。
φ 是非线性激活函数。 {σ1, σ2, ..., σM } 表示以多方面方式影响他人的推文的不确定性。
然后,节点表示 在第 m 个视图潜在传播可以从
中采样,
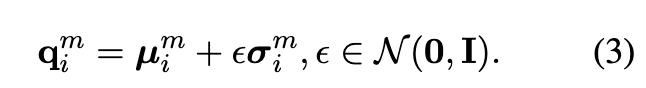
然后,GPE 测量节点之间的潜在交互,以及来自多个底层方面的分布之间的 KL 散度。第 m 个视图重建图上节点 vi 和节点 vj 之间的边权重计算为,
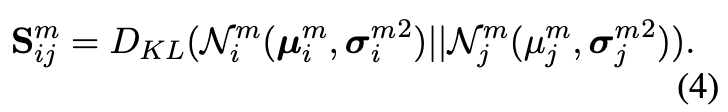
根据以上计算,我们可以得到多视图细化节点表示{Q1,Q2,...,QM}和对应的邻接矩阵{S1,S2,...,SM}。它们使模型能够学习多个重建有向图中节点的不确定影响。
4.3.2 重建传播图中的重新学习潜在相互作用
基于这些重建图,我们进一步应用双层图卷积来捕获两条推文之间的不同潜在交互。消息传递定义为,
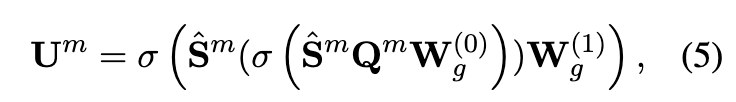
其中 表示邻接矩阵 S 的归一化。
和
是第一和第二图层中的可学习参数矩阵。
受 Bian 等人的启发。 (2020),我们在每次图卷积操作后将每个节点的隐藏特征向量与根节点的隐藏特征向量连接起来,以强调源新闻在传播中的重要作用。然后,重构图中节点的最终表示被计算为,
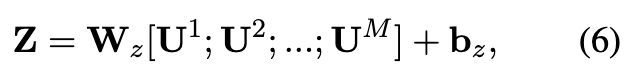
通过上述双图结构,我们不仅可以学习原始传播中的远程交互,还可以捕获不确定推文之间的潜在交互。
我们聚合图中的节点表示以形成图表示。给定原始传播中的节点表示 V 和重建图中的节点表示 Z,图表示计算为:
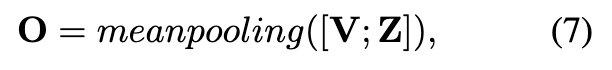
4.4 假新闻检测和训练
基于两个不同图形表示的连接,所有类别的标签概率可以由全连接层和 softmax 函数定义,即,
![]()
其中 和
是可学习的参数矩阵。我们优化了由交叉熵准则计算的假新闻分类损失函数,即
![]()
5 实验
在本节中,我们通过实验评估我们提出的假新闻检测模型的性能。
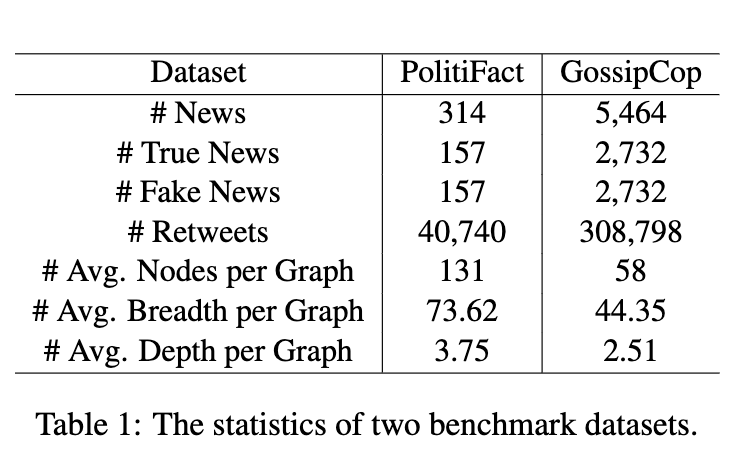
5.1 数据集
数据集统计数据如表 1 所示。Politi-Fact 和 GossipCop 数据集由 Fake-NewsNet (Shu et al., 2020) 发布。样本分别来自PolitiFact和GossipCop,这两个网站分别用于对政治和名人新闻进行事实核查。我们遵循与 Shu 等人相同的程序 (2019a) 拆分每个数据集,即随机选择 75% 的新闻作为训练数据,同时保留其余的作为测试数据.
5.2 实验设置
由于假新闻检测是一项分类任务,我们选择准确性 (Acc)、预测 (P)、召回 (R) 和宏观平均 F1 分数 (F1) 来衡量每个模型的性能。
所有实验均在单个 GeForce RTX 3080Ti 上进行。对于文本内容的输入特征,我们遵循 (Dou et al., 2021) 并考虑 300 维的 word2vec 向量 (Mikolov et al., 2013),这些向量由 spaCy (Honnibal) 在包含 680k 词的大型语料库上进行预训练and Montani, 2017),即 d0 = 300。隐藏向量的维数设置为 64。我们通过反向传播和广泛使用的名为 Adam 的随机梯度下降训练所有模型(Kingma 和 Ba,2015)。 PolitiFact 和 GossipCop 的学习率分别设置为 0.001 和 0.0005。训练过程迭代 200 个时期,当验证损失停止减少 10 个时期时,应用早期停止(Yuan 等人,2007)。最终结果是 5 次重复的平均表现。
5.3 比较方法
基于文本的假新闻检测方法包括:mGRU (Ma et al., 2016) 使用 RNN 来捕获从转发序列中识别的时间语言模式。 CSI (Ruchansky et al., 2017) 通过使用 LSTM 学习顺序转发特征。
基于传播的假新闻检测方法包括:GCNFN (Monti et al., 2019)将传播结构建模为图,并使用GCN对传播图进行编码。
我们通过删除配置文件信息来实现模型以进行公平比较。 GAT (Velickovic et al., 2018) 应用图形注意力网络对传播结构进行编码。 PLAN (Khoo et al., 2020) 使用多头注意机制来模拟传播结构中的长距离交互。 BiGCN (Bian et al., 2020) 使用两个 GCN 对传播图和散播图进行建模。 RumorGCN (Hu et al., 2021) 通过使用关系 GCN 从传播中学习多关系依赖。 EBGCN (Wei et al., 2021) 是一种基于图的模型,从概率的角度关注传播结构中的不确定性问题。
5.4 假新闻检测结果
表 2 报告了假新闻检测的整体性能。从中,我们有以下主要观察结果:
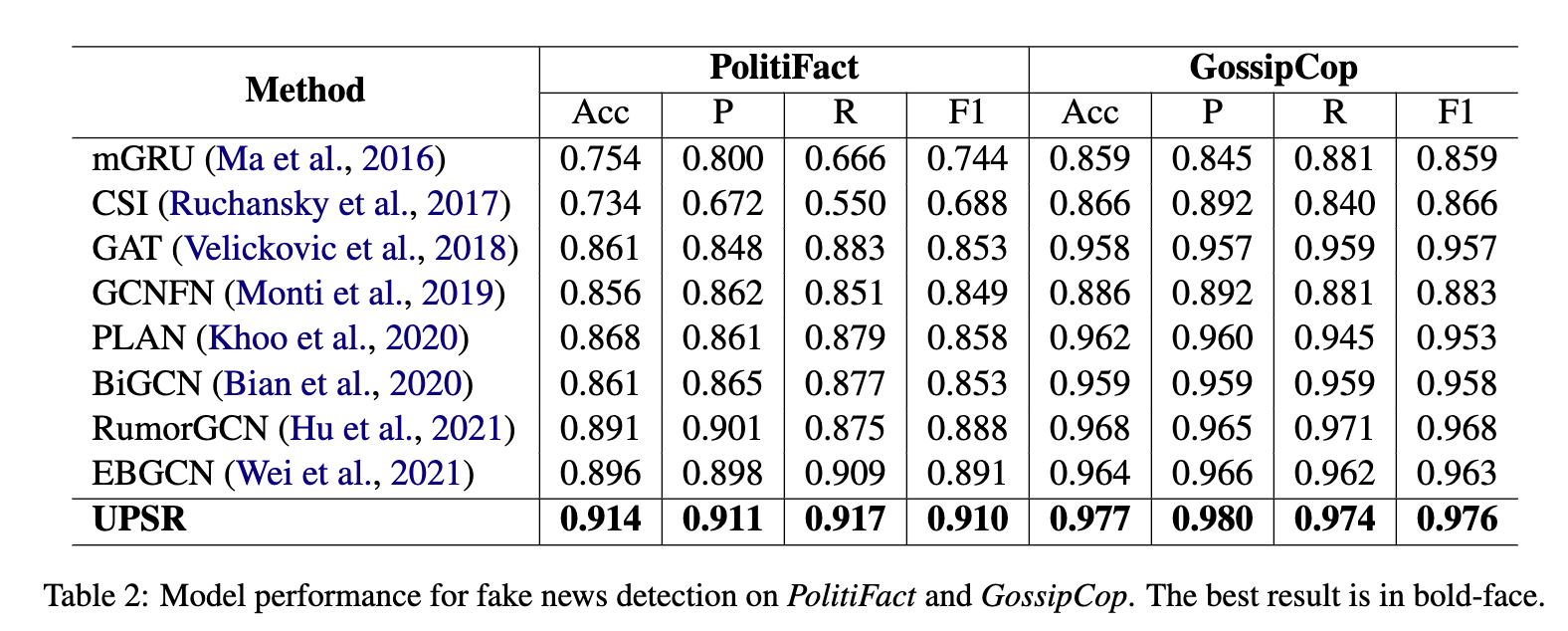
1)基于文本的方法比基于传播的方法性能差。这表明传播模式更有利于检测假新闻,因为假新闻发布者总是故意扭曲新闻的文本内容。
2)PLAN 用注意力模块捕获传播序列中的远程交互,并获得适度的结果,甚至优于一些基于图的浅层模型。然而,他们仍然无法有效地提取隐藏在传播序列中的潜在相互作用,从而获得有限的性能。
3) EBGCN 和 RumorGCN 分别在 PolitiFact 和 GossipCop 上实现了次优性能。这是有意义的,因为RumorGCN考虑了来自兄弟节点的潜在交互;EBGCN则通过调整后的传播树探索鲁棒相互作用,为检测提供更有效的结构信息。
然而,它们的浅层网络使得难以对传播中的长距离交互进行建模,因此它们不能适应具有更深传播结构的新闻。
4)我们的 UPSR 产生的性能始终优于两个数据集上的所有基线。好处主要有两方面。首先,深度图卷积使模型能够专注于原始传播建模中的远程交互。其次,UPSR 进一步对基于不确定性感知节点表示的重构传播进行编码,这可以有效地捕获转推之间更多潜在的交互,并学习不同的结构模式以进行检测。
6 讨论
在本节中,我们进行更多的实验以进一步了解 UPSR 的性能。
6.1 消融研究
· 我们进行了一项消融研究,以评估UPSR中的关键成分。1) w/o Root表示对重构的传播图进行编码时没有明确考虑源新闻的影响。2) w/o GPE 移除高斯传播估计模块并测量两个节点嵌入之间的余弦相似度。3) w/o OPM是指去掉原有的传播模型,直接根据输入的文本特征重构传播。 4) w/o RPM 正在移除整个重建的传播模型。
消融研究的结果显示在表 3 的第一块中。
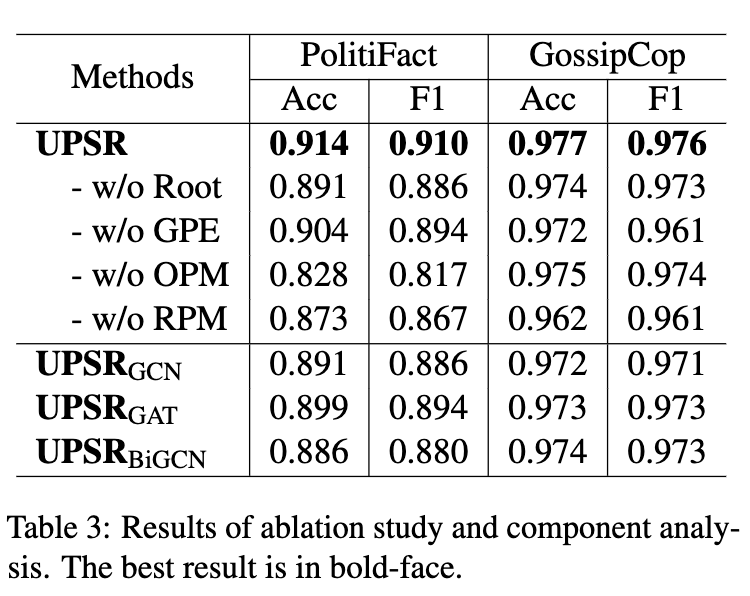
完整模型在准确性和 F1 分数方面产生最佳性能。 1)在重建传播模型中不考虑源新闻的影响,w/o Root 的性能在两个数据集上都略有下降,显示了源新闻在传播中的重要作用。2)w/o GPE 明显不如完整模型,验证了估计具有多个方面的传播结构可以成功地适应转推的不确定影响,并能够得出准确的潜在交互。3)当移除完全重建的传播模型时,w/o RPM 在两个评估指标方面获得较差的性能,这证明了传播重建的有效性。 4)去除原始传播模型后,w/o OPM 的性能也显着下降。这是直观的,因为从原始传播中转推之间的显式交互中学习可能会导致相对全面的表示,这使 GPE 能够探索更有效的交互。
6.2 与不同原始传播建模模块的比较
我们进一步用以下替代方案替换了原始传播模型中的深度图卷积网络。 1) UPSR_GCN 采用普通的两层 GCNs (Kipf and Welling, 2017) 来模拟原始传播。 2) UPSR_GAT 用普通的两层 GAT 代替 (Velickovic et al., 2018)。 3) UPSR_BiGCN 遵循 (Bian et al., 2020) 应用双向 GCN。
结果报告在表 3 的第二块中。这些变体的退化性能表明我们模型的优越性,它可以通过堆叠多个图卷积来捕获传播中的远程交互。
此外,UPSR及其变体UPSRGCN, UPSRGAT, UPSRBiGCN在两个数据集上的表现始终优于相应的单图模型。原因是双图框架不仅可以学习原始传播中的交互,还可以捕获不确定推文之间的潜在交互。
6.3 参数分析
图 2 探讨了 UPSR 针对两个重要参数的性能,即原始传播建模 (OPM) 中的不同层数,以及重建传播建模 (RPM) 中的不同面数。
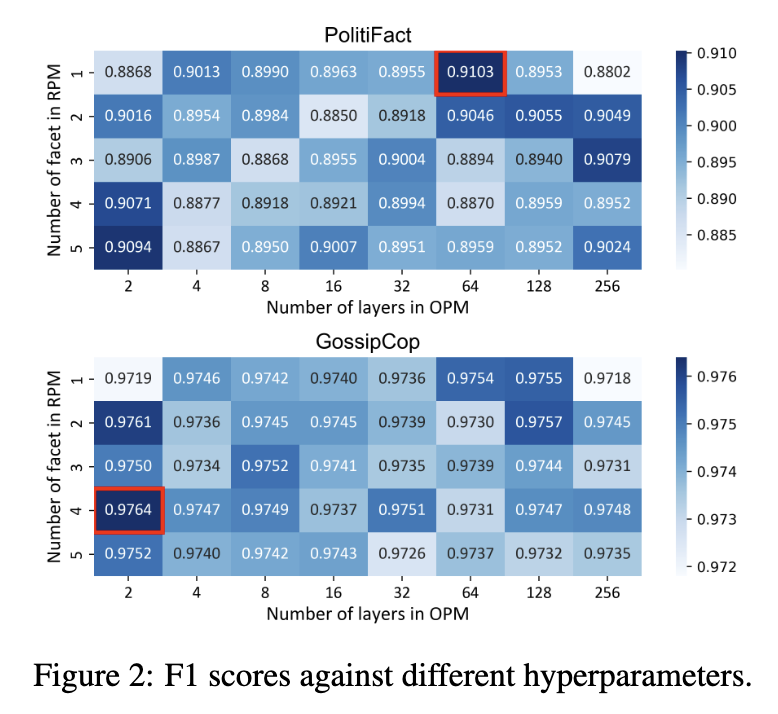
图层在原始传播建模中的影响。为了研究我们的模型是否可以从原始传播建模中的多层传播中受益,我们在 {2, 4, 8, 16, 32, 64, 128, 256} 范围内改变图卷积层的数量。 PolitiFact 和 GossipCop 的最佳设置分别为 64 和 2。 PolitiFact 上的传播结构更深,因此需要更多的图形层来捕获节点之间的远程交互。层数的不断增加甚至会损害性能。这可能是由过度拟合问题引起的。
重构传播模型中面数的影响。为了研究我们的模型是否可以从不确定性的多方面估计中受益,我们在 {1, 2, 3, 4, 5} 范围内改变方面的数量。 PolitiFact 和 GossipCop 数据集的最佳设置分别为 1 和 4。这些结果表明,从多个方面估计节点对于检测与名人相关的假新闻更有利可图,这可以促进充分捕获两个节点之间的潜在交互。此外,名人新闻下转发之间的依赖关系可能更复杂,需要考虑更多方面。
6.4 传播深度分析
图 4 显示了不同深度的传播结构的性能。从图中可以看出,BiGCN 检测深度传播的性能在两个数据集上都明显下降。
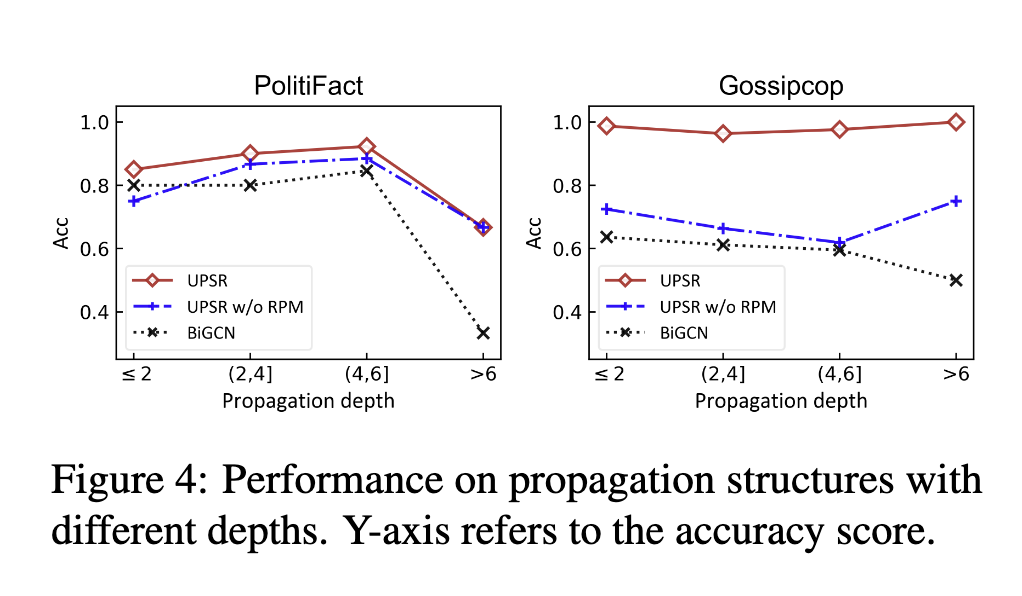
这表明假新闻检测随着更深层次的传播而更具挑战性,这通常反映了用户之间重要的潜在互动。与 BiGCN 相比,UPSR 及其变体在识别更深的传播方面获得了更好的性能。这表明原始传播建模可以有效地捕获原始传播中的远程交互以进行假新闻检测。此外,UPSR 在几乎任何传播深度范围内都实现了相当大的改进。我们推测,通过估计转推对重建原始传播的不确定影响,UPSR 可以进一步捕获两个节点之间更多潜在的交互,并学习更好的检测表示。因此,UPSR 对传播深度不敏感,可以适应浅层和深层传播。
6.5 案例研究
图 3 可视化了一条来自 PolitiFact 的假新闻的传播结构。该新闻被 BiGCN 和 EBGCN 错误分类,但被我们的模型成功检测到。

以前的浅层图网络(例如 BiGCN、EBGCN)会忽略远距离连接,例如节点 3 和 28 之间的交互,只能捕获局部结构传播信息。
通过重构原始传播,UPSR 在一定程度上缓解了这个问题,并通过两个远距离节点之间的重构边在图中聚合了更多有效信息。
此外,与图 3(b)和 3(c)相比,EBGCN 通过自适应调整显式边的权重来处理噪声边缘。然而,它们只关注显式边缘并限制图中的消息传递。与他们的模型不同,UPSR 不仅对这些嘈杂的边具有鲁棒性,而且还捕获节点之间更有价值的潜在交互以改进检测。
7 结论
本文研究了假新闻检测中更广泛的传播不确定性问题。我们提出了一种新的不确定性感知传播结构重建(UPSR)来联合模拟不确定传播中的远程和潜在相互作用。开发高斯传播估计 (GPE) 以通过适应传播中转推的固有不确定性影响来重建潜在传播。在两个真实世界基准上进行的实验表明,UPSR 优于最近的检测方法。
未来,我们将专注于提高模型在训练传播数据有限的情况下的检测性能。
这篇关于论文阅读-Uncertainty-aware Propagation Structure Reconstruction for Fake News Detection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
