本文主要是介绍再次理解苏神的CoSENT损失函数的pytorch代码实现(终于搞懂了),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
-
最近学习深度学习关于自然语言处理的有关内容时,看到了苏神关于在解决文本相似任务时提出的新的计算损失的方式:CoSENT损失。原文链接:CoSENT损失计算方式及原理。然后就想看看代码是怎么实现的。刚开始看属实是有点难,但还是给弄明白了,这里记录一下,供大家参考。
-
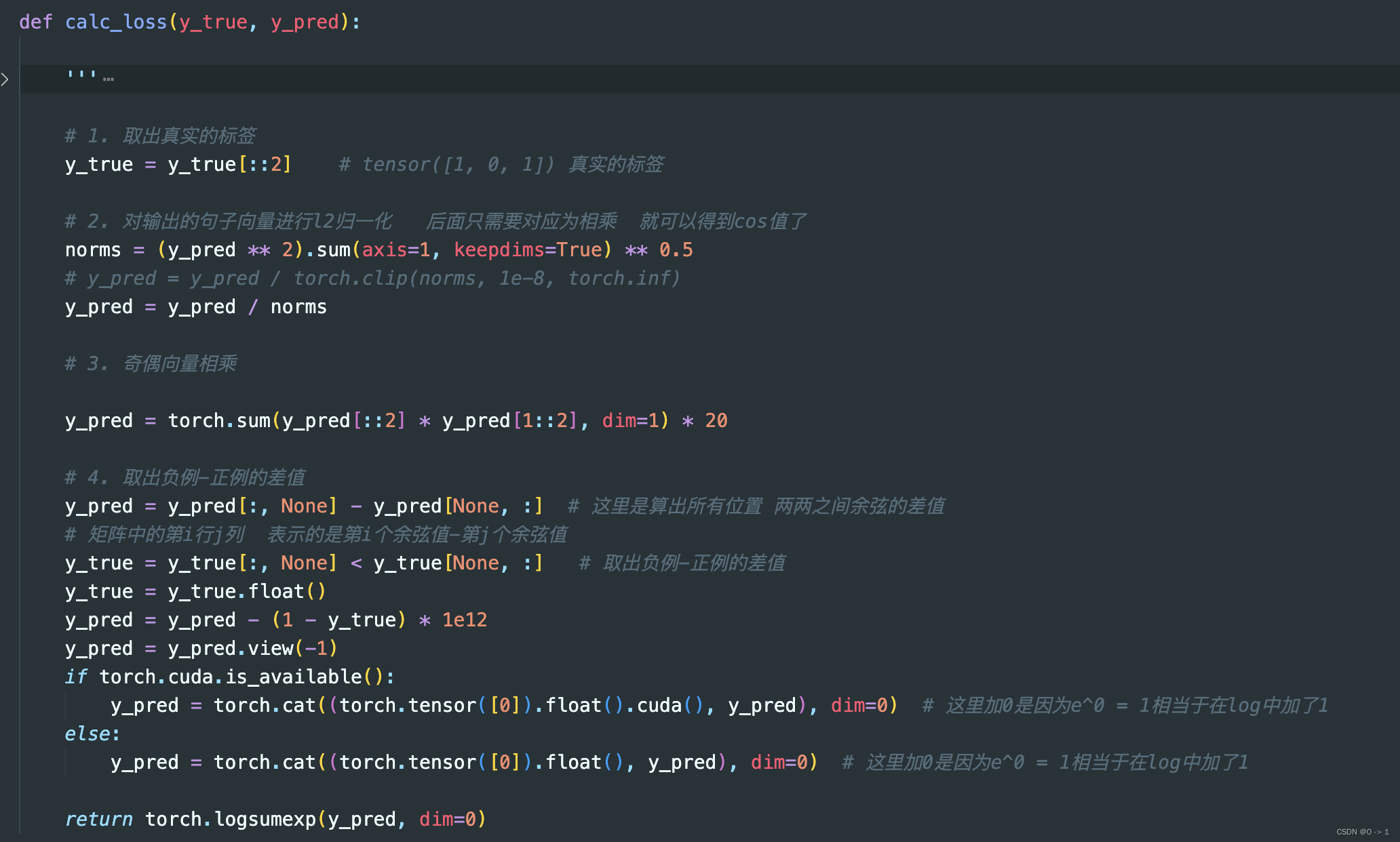
先看pytorch的代码实现,如下图:
-
那么在这里主要给大家解释实现方式中的前三步:取出真实的标签、句子向量归一化、奇偶向量相乘(注:一定要先看CoSENT损失的表达式,理解之后再来看代码实现)。
step1-取出真实的标签: 取真实标签:在最开始加载数据的时候,是逐个加载句子的,而不是以句子对的形式进行加载。例如: 进行相似度计算的句子对有1000对,那么加载数据到列表是有2000个句子的,相对应的真实标签也由原来的1000个变为2000个,所以再取标签时label要跳2取值。这也就是
y_true = y_true[::2]的含义表达。step2-向量归一化: 向量归一化挺好理解的,即输出向量进行归一化,方便后续计算。
step3-奇偶向量相乘: 奇偶向量相乘:前面说过,我们是要计算句子对之间的相似值的,但是现在是句子对以前后顺序进行存放,所以要分别取索引为奇数和偶数的向量输出,然后在相乘。例如: 现在有句子顺序是[1,2,3,4],我们是要[1,2]相乘,[3,4]相乘的。那么取奇数就是[1,3],偶数就是[2,4],然后对应索引相乘就是[1,2]、[3,4]相乘了。也就得到了每个句子对的相似值。这也就是代码
y_pred = torch.sum(y_pred[::2] * y_pred[1::2],dim=1)的含义。后续的实现只要理解了损失函数怎么计算,代码理解就问题不大了。 -
以上就是我个人对CoSENT损失函数的理解。希望能帮助到你
这篇关于再次理解苏神的CoSENT损失函数的pytorch代码实现(终于搞懂了)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






