本文主要是介绍MySQL:事务(事务的实现之undo、purge、group commit),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
asds事务(Transaction) 是数据库区别于文件系统的重要特性之一。在文件系统中,如果正在写文件,但是操作系统突然崩溃了,这个文件就很有可能被破坏。当然,有一些机制可以把文件恢复到某个时间点。不过,如果需要保证两个文件同步,这些文件系统可能就显得无能为力了。这正是数据库系统引入事务的主要目的:事务会把数据库从一种一致状态转换为另一种一致状态。在数据库提交工作时,可以确保要么所有修改都已经保存了,要么所有修改都不保存。
asdsInnoDB 存储引擎中的事务完全符合ACID 的特性。ACID 是以下4 个词的缩写:
ddss①、原子性(atomicity) asddss②、一致性(consistency) asddss③、隔离性(isolation) asddss④、持久性 (durability)
asdsadasdasdasdsadasdasdasdsadassdasdsadasdasdsadasdsadassadasdas————《MySQL技术内幕INNODB存储引擎》
- undo
- 基本概念
- undo 存储管理
- undo log 格式
- 查看undo 信息
- purge
- group commit (应放在redo log 中介绍)(一起读入到磁盘)
- 💖感谢各位的暴击三连~💖
undo
基本概念
ssdss 重做日志记录了事务的行为,可以很好地通过其 对页进行”重做“操作。但是事务有时还需要进行回滚操作,这时就需要undo 。因此在对数据库进行修改时, InnoDB 存储引擎不但会产生redo, 还会产生一定量的undo。这样如果用户执行的事务或语句由于某种原因失败了,又或者用户用一条ROLLBACK 语句请求回滚,就可以利用这些undo信息将数据回滚到修改之前的样子。
ssdsd 注 1:redo 存放在重做日志文件中,与redo 不同, undo 存放在数据库内部的一个特殊段(segment ) 中, 这个段称为undo 段( undo segment)。undo 段位于共享表空间内。可以通过py_innodb page_info.py 工具来查看当前共享表空间中undo 的数量。
ssd undo的特性分析:
ssdsd⒈(回滚)undo 并不是将数据库物理地恢复到执行语句或事务之前的样子。undo 是 逻辑日志,只是将数据库逻辑地恢复到原来的样子。所有修改都被逻辑地取消了,但是数据结构和页本身在回滚之后可能大不相同。
ssdsdsd①、为什么不是物理的恢复呢? 这是因为在多用户并发系统中,可能会有数十、数百甚至数千个并发事务。数据库的主要任务就是协调对数据记录的并发访问。比如, 一个事务在修改当前一个页中某几条记录,同时还有别的事务在对同一个页中另几条记录进行修改。因此, 不能将一个页回滚到事务开始的样子,因为这样会影响其他事务正在进行的工作。
ssdsdsd②、eg:用户执行了一个INSERT 1OW 条记录的事务,这个事务会导致分配一个新的段,即表空间会增大。在用户执行ROLLBACK 时,会将插入的事务进行回滚,但是表空间的大小并不会因此而收缩。因此,当InnoDB 存储引擎回滚时,它实际上做的是与先前相反的工作。对于每个INSERT, InnoDB 存储引擎会完成一个DELETE; 对于每个DELETE, InnoDB 存储引擎会执行一个INSERT: 对于每个UPDATE, InnoDB 存储引擎会执行一个相反的UPDATE, 将修改前的行放回去。
ssdsd⒉(非一致性读)undo 的另一个作用是MVCC, 即在InnoDB 存储引擎中MVCC 的实现是通过undo 来完成。当用户读取一行记录时,若该记录已经被其他事务占用,当前事务可以通过undo 读取之前的行版本信息,以此实现非锁定读取。
ssdsd⒊undo log 会产生redo log, 也就是undo log 的产生会伴随着redo log 的产生,这是因为undo log 也需要持久性的保护。
undo 存储管理
ssdss InnoDB 存储引擎对 undo 的管理同样采用段的方式。但是这个段和之前介绍的段有所不同。首先InnoDB 存储引擎有rollback segment, 每个回滚段中记录了1024 个undo log segment, 而在每个undo log segment 段中进行undo 页的申请。共享表空间偏移量为5 的页 (0, 5) 记录了所有rollback segment header 所在的页,这个页的类型为FIL_PAGE_TYP_SYS。
ssdsd 注 2:在InnoDBl.1 版本之前(不包括1.1 版本),只有一个rollback segment, 因此支持同时在线的事务限制为 1024。虽然对绝大多数的应用来说都已经够用,但不管怎么说这是一个瓶颈。从 1.1 版本开始InnoDB 支持 最大128 个rollback segment, 故其支持同时在线的事务限制提高到了128*1024。这些rollback segment 都存储于共享表空间中。
ssdsd 注 3:从InnoDBl.2 版本开始,可通过参数对 rollback segment 做进一步的设置。这些参数包括:
ssddsdsd①、innodb_undo_directory :用于设置rollback segment 文件所在的路径。这意味着 rollback segment 可以存放在共享表空间以外的位置,即可以设置为独立表空间。该参数的默认值为". " 表示当前InnoDB 存储引擎的目录。
ssddsdsd②、innodb_undo_logs :用来设置rollback segment 的个数,默认值为128 。
ssddsdsd③、innodb_undo_tablespaces:用来设置构成rollback segment 文件的数量,这样rollback segment 可以较为平均地分布在多个文件中。设置该参数后,会在路径innodb_ undo_directory 看到 undo 为前缀的文件,该文件就代表rollback segment 文件,如下图,为3个。
myspl> SHOW VARIABLES LIKE ' innodb_undo%';
+--- - --------------------+-------+
| Variable name | Value |
+----- ------ - ------------+-------+
| innodb_undo_directory | • |
| innodb_undo_logs | 128 |
| innodb_undo_tablespaces | 3 |
+--------------- ---------+---- ---+
3 rows in set (0.00 sec)
mysql> SHOW VARIABLES LIKE 'datadir';
+- - ------ - - ----+------------ - - --- --------------+
| Variable name | Value |
+---------- ----+-------------------------------+
| datadir | / Users / david / mysql_data / data / |
+--------- -----+------------------------- ------+
1 row in set (0.00 sec )
mysql> system ls -lh / Users / david / mysql_data/ data / undo*
-rw-rw---- 1 david staff 1OM 11 22 16:55/ User s/ dav id / mysql_data / data/ undo OOl
-rw-rw---- 1 david s staff 1OM 11 22 16:51/Use r s/david/mysql —data / data / undo002
-rw- rw---- 1 david s staff 1OM 11 22 16:51/ Users / david/ mysql_data/ data/undo003
ssdss 事务在 undo log segment 分配页并写入undo log 的这个过程同样需要写入重做日志。当事务提交时, InnoDB 存储引擎会做以下两件事情:
ssdsdsd①、将 undo log 放入列表中,以供之后的 purge 操作。
ssdsdsd②、判断undo log 所在的页是否可以重用,若可以分配给下个事务使用。
ssdss 事务提交后并不能马上删除 undo log 及undo log 所在的页。这是因为可能还有其他事务需要通过undo log 来得到行记录之前的版本。故事务提交时将 undo log 放入一个链表中, 是否可以最终删除undo log 及undo log 所在页由 purge 线程来判断。
ssdsd 注 4:(undo log 为什么可以重用 ?purge操作的离散读为什么慢?) 若为每一个事务分配一个单独的 undo 页会非常浪费存储空间,特别是对于OLTP的应用类型。因为在事务提交时,可能并不能马上释放页。假设某应用的删除和更新操作的TPS (transaction per second) 为1000, 为每个事务分配一个undo 页,那么一分钟就需要1000*60 个页,大约需要的存储空间为1GB 。若每秒的purge 页的数量为20, 这样的设计对磁盘空间有着相当高的要求。因此,在InnoDB 存储引擎的设计中对undo 页可以进行重用。具体来说当事务提交时, 首先将undo log 放入链表中,然后判断undo 页的使用空间是否小于3/4, 若是则表示该undo 页可以被重用,之后新的undo log 记录在当前undo log 的后面。由于存放undo log 的列表是以记录进行组织的,而undo 页可能存放着不同事务的undo log,因此purge 操作需要涉及磁盘的离散读取操作,是一个比较缓慢的过程。
ssdsd eg:可以通过命令SHOW ENGINE INNODB STATUS 来查看链表中 undo log 的数量:
mysql> SHOW ENGINE INNODB STATUS\G ;
*************************** 1. row***************************
TRANSACTIONS
Trx id counter 3000
Purge done for trx ' s n:o< 2C03 undo n:o < O
History list length 12
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 0 , not started
MySQL thread id 1 , OS thread handle Ox1500f1000 , query id 4 localhost root
show engine innodb status
.....
ssdsd History list length 就代表了undo log 的数最,这里为12 。purge 操作会减少该值。然而由于undo log 所在的页可以被重用,因此即使操作发生, History list length 的值也可以不为 0 。
undo log 格式
ssdss 在InnoDB 存储引擎中,undo log 分为:
ssdsdsdsd①、insert undo log : 指在insert 操作中产生的undo log 。因为insert 操作的记录,只对事务本身可见,对其他事务不可见(这是事务隔离性的要求),故该 undo log 可以在事务提交后直接删除,不需要进行purge 操作。
ssdsdsdsd②、update undo log: 记录的是对delete 和update 操作产生的undo log 。该undo log 可能需要提供MVCC 机制,因此不能在事务提交时就进行删除。提交时放入undo log 链表,等待purge 线程进行最后的删除。
ssdss 结构如下:
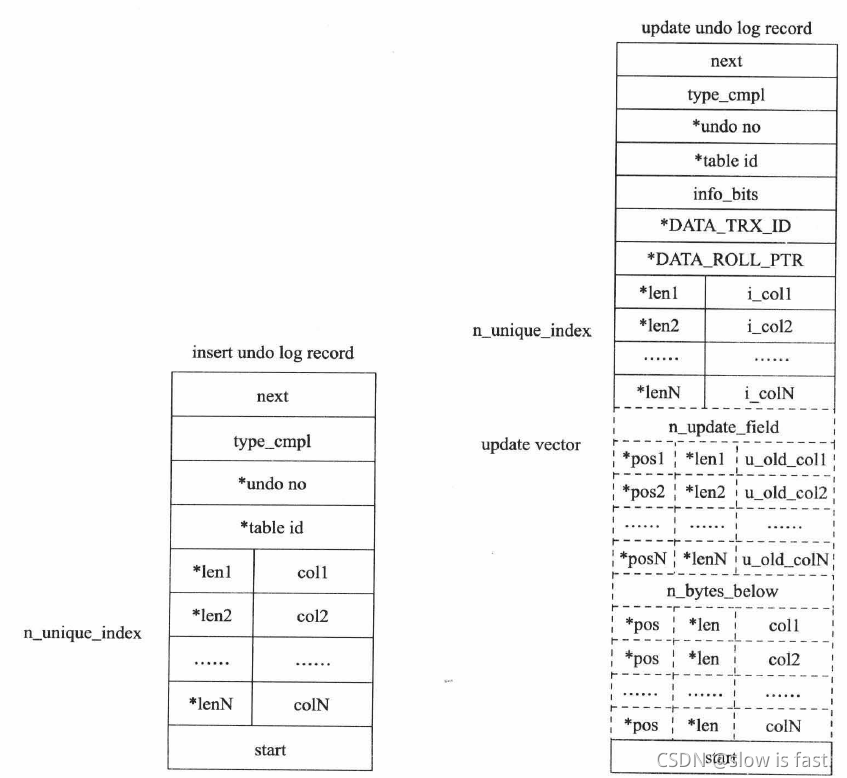
ssdsd 注 5:*表示对存储的字段进行了 压缩。insert undo log 开始的前两个字节next 记录的是 下一个undo log 的位置,通过该next 的字节可以知道一个undo log 所占的空间字节数。类似地,尾部的两个字节记录的是undo log 的开始位置。type_cmpl 占用一个字节,记录的是undo 的类型,对于insert undo log, 该值总是为11 。undo_no 记录事务的ID, table_id 记录undo log 所对应的表对象。这两个值都是在压缩后保存的。接着的部分记录了所有主键的列和值。在进行rollback 操作时,根据这些值可以定位到具体的记录,然后进行删除即可。update undo log 相对于之前介绍的insert undo log, 记录的内容更多,所需占用的空间也更大。next 、start 、undo_no 、table_id 与之前介绍的insert undo log 部分相同。这里的type_cmpl, 由于update undo log 本身还有分类,故其可能的值如下:
ssdsd ①、 TRX_UNDO_ UP_EXIST_ REC 更新non-delete-mark 的记录
ssdsd ②、TRX_UNDO_UPD_DEL_REC 将delete 的记录标记为not delete
ssdsd ③、TRX_UNDO_DEL_MARK_REC 将记录标记为delete
ssd接着的部分记录update_vector 信息, update_vector 表示update 操作导致发生改变的列。每个修改的列信息都要记录的undo log 中。对于不同的undo log 类型,可能还需要记录对索引列所做的修改。
查看undo 信息
ssdss Oracle 和Microsoft SQL Server 数据库都由内部的数据字典来观察当前undo 的信息,InnoDB 存储引擎在这方面做得还不, DBA 只能通过原理和经验来进行判断。InnoSQL对information_schema 进行了扩展, 添加了两张数据字典表,这样用户可以非常方便和快捷地查看undo 的信息。
ssdss①、首先增加的数据字典表为INNODB_ TRX ROLLBACK_ SEGMENT:
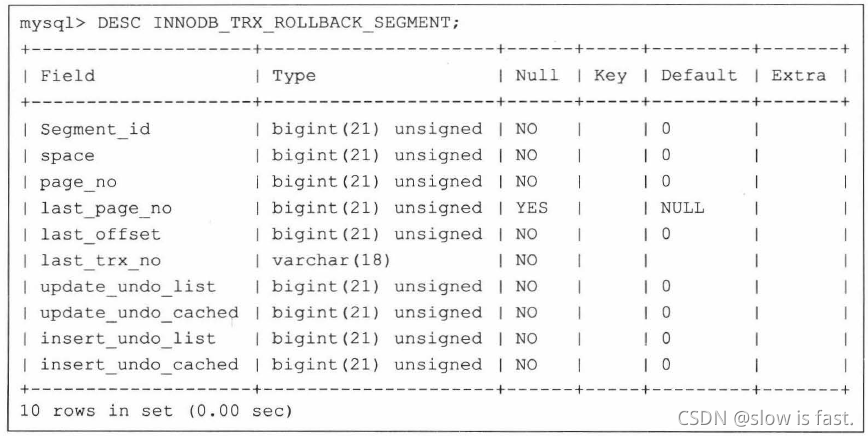
ssdss②、另一张数据字典表为INNODB_TRX_UNDO, 用来记录事务对应的undo log.
ssdsd 注 6:delete 操作并不直接删除记录,而只是将记录标记为已删除,也就是将记录的delete flag 设置为 1 。而记录最终的删除是在purge 操作中完成的。 update 主键的操作其实分两步完成。首先将原主键记录标记为巳删除,因此需要产生一个类型为TRX_ UNDO_DEL_MARK_REC 的undo log, 之后插入一条新的记录, 因此需要产生一个类型为TRX_UNDO_ INSERT_REC 的undo log 。undo_rec_no 显示了产生日志的步骤。
purge
ssdss delete 和 update 操作可能并不直接删除原有的数据。
ssdsd eg:SQL 语句:DELETE FROM t WHERE a=1; 表t 上列a 有聚集索引,列b 上有辅助索引。对于上述的delete 操作,仅是将主键列等于1 的记录delete flag 设置为1, 记录并没有被删除,即记录还是存在于B+ 树中。其次,对辅助索引上a 等于1 b 等于1 的记录同样没有做任何处理,甚至没有产生undo log 。而真正删除这行记录的操作其实被“延时“了,最终在purge 操作中完成。
ssdsspurge 用于最终完成delete 和update 操作。这样设计是因为InnoDB 存储引擎支持MVCC, 所以记录不能在事务提交时立即进行处理。这时其他事物可能正在引用这行,故InnoDB 存储引擎需要保存记录之前的版本。而是否可以删除该条记录通过purge 来进行判断。若该行记录已不被任何其他事务引用,那么就可以进行真正的delete 操作。可见, purge 操作是清理之前的delete 和update 操作,将上述操作“最终“完成。而实际执行的操作为delete 操作,清理之前行记录的版本。
ssdss此外,为了节省存储空间, InnoDB 存储引擎的undo log 设计是这样的:
ssdssddss一个页上允许多个事务的undo log 存在。虽然这不代表事务在全局过程中提交的顺序,但是后面的事务产生的undo log 总在最后。此外, InnoDB 存储引擎还有一个history 列表,它根据事务提交的顺序,将undo log 进行链接。undolog 与 history 列表的关系如下图:
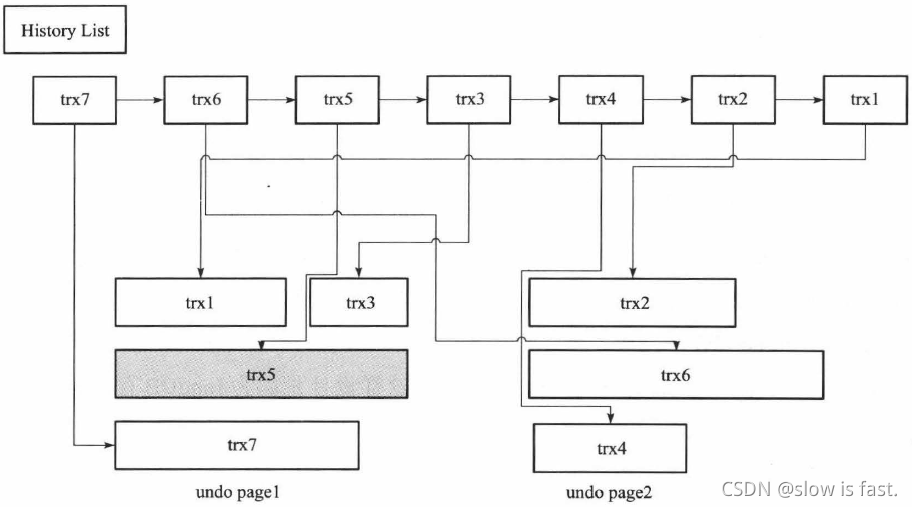
ssdssddsshistory list 表示按照事务提交的顺序将undo log 进行组织。在 InnoDB 存储引擎的设计中,先提交的事务总在尾端。undo page 存放了undo log, 由于可以重用,因此一个undo page 中可能存放了多个不同事务的undo log 。trx.5 的灰色阴影表示该undo log 还被其他事务引用。
ssdssddss在执行purge 的过程中, InnoDB 存储引擎首先从history list 中找到第一个需要被清理的记录,这里为trx1, 清理之后InnoDB 存储引擎会在trx1 的undo log 所在的页中继续寻找是否存在可以被清理的记录,这里会找到事务trx.3, 接着找到trx5, 但是发现trx5 被其他事务所引用而不能清理,故再次去history list 中查找,发现这时最尾端的记录为trx.2, 接着找到trx.2 所在的页,然后依次再把事务trx.6 、trx.4 的记录进行清理。由于undo page2 中所有的页都被清理了,因此该undo page 可以被重用。
ssdssInnoDB 存储引擎这种先从 history list 中找undo log, 然后再从undo page 中找undo log 的设计模式是为了避免大量的随机读取操作,从而提高purge 的效率。
ssdss 参数 ① :innodb_purge_batch_size:用来设置每次purge 操作需要清理的 undo page 数量。在lnnoDB l.2 之前, 该参数的默认值为20 。而从1.2 版本开始,该参数的默认值为300。 这个值不能设置的过大,则每次需要 purge 处理更多的 undo page, 从而导致CPU 和磁盘IO 过于集中于对 undo log 的处理,使性能下降。
ssdss参数 ② :innodb_max_purge_lag : 当InnoDB 存储引擎的压力非常大时,并不能高效地进行purge 操作。那么history list 的长度会变得越来越长。全局动态参数innodb_max_purge_lag 用来控制 history list 的长度, 若长度大于该参数时,其会“延缓" DML 的操作。该参数默认值为 0 , 表示不对 history list 做任何限制。当大于 0 时,就会延缓DML 的操作,其延缓的算法为:
ssdsdsdsddsdssdsdsdsdsdelay = ((length ( history_list ) - innodb_max_ purge_ lag ) * 10 ) - 5
ssdss delay 的单位是毫秒。此外, 需要特别注意的是, delay 的对象是行,而不是一个DML 操作。例如当一个update 操作需要更新5 行数据时,每行数据的操作都会被 delay, 故总的延时时间为5*delay 。而delay 的统计会在每一次purge 操作完成后,重新进行计算。
ssdss参数 ③ :innodb_ max purge_ lag_ delay: InnoDB 1.2 版本引入了新的全局动态参数,其用来控制 delay 的最大毫秒数。也就是当上述计算得到的 delay 值大于该参数时,将 delay 设置为 innodb_max_purge_ lag_delay, 避免由于purge 操作缓慢导致其他SQL 线程出现无限制的等待。
group commit (应放在redo log 中介绍)(一起读入到磁盘)
ssdss 若事务为非只读事务,则每次事务提交时需要进行一次fsync 操作,以此保证重做日志都已经写入磁盘。当数据库发生宥机时,可以通过重做日志进行恢复。虽然固态硬盘的出现提高了磁盘的性能,然而磁盘的fsync 性能是有限的。为了提高磁盘fsync 的效率,当前数据库都提供了group commit 的功能,即一次 fsync 可以刷新确保多个事务日志被写入文件。 对于InnoDB 存储引擎来说,事务提交时会进行两个阶段的操作:
ssdss①、 修改内存中事务对应的信息,并且将日志写入重做日志缓冲。
ssdss②、 调用fsync 将确保日志都从重做日志缓冲写入磁盘。
ssdsd注 7: 步骤 ② 相对于步骤 ① 是一个较慢的过程,这是因为存储引擎 需要与磁盘打交道。但当有事务进行这个过程时,其他事务可以进行 步骤 ① 的操作,正在提交的事物完成提交操作后,再次进行步骤 ② 时,可以将多个事务的重做日志通过一次fsync 刷新到磁盘,这样就大大地减少了磁盘的压力,从而提高了数据库的整体性能。对于写入或更新较为频繁的操作, group commit 的效果尤为明显。
ssdsd 注 8:在 InnoDBl.2 版本之前,在开启二进制日志后, InnoDB 存储引擎的 group commit 功能会失效,从而导致性能的下降。并且在线环境多使用 replication 环境,二进制日志的选项基本都为开启状态,因此这个问题尤为显著。导致这个问题的原因是在开启二进制日志后,为了保证存储引擎层中的事务和二进制日志的一致性, 二者之间使用了两阶段事务,其步骤如下:
s323sdss①、 当事务提交时 InnoDB 存储引擎进行prepare 操作。
ss322dss②、 MySQL 数据库上层写入二进制日志。
ss322dss③、 InnoDB 存储引擎层将日志写入重做日志文件:
ss322dssddssⅰ 修改内存中事务对应的信息,并且将日志写入重做日志缓冲。
ss322dssddssⅱ 调用fsync 将确保日志都从重做日志缓冲写入磁盘。
ssdsd 一旦步骤 ② 中的操作完成,就确保了事务的提交,即使在执行步骤 ③ 时数据库发生了宕机。此外需要注意的是,每个步骤都需要进行一次fsync 操作才能保证上下两层数据的一致性。 步骤 ② 的 fsync 由参数sync_binlog 控制,步骤 ③ 的 fsync 由参数 innodb flush_ log_ at_trx_commit 控制。
ssdsd 注 8 问题的解决方法:在这种情况下,不但MySQL 数据库上层的二进制日志写入是 group commit 的, InnoDB 存储引擎层也是 group commit 的。此外还移除了原先的锁 prepare_commit_ mutex, 从而大大提高了数据库的整体性。MySQL5.6 采用了类似的实现方式,并将其称为Binary Log Group Commit (BLGC) 。
ssdsdMySQL 5.6 BLGC 的实现方式是将事务提交的过程分为几个步骤来完成,如下图。

ssdsd在MySQL 数据库上层进行提交时首先按顺序将其放入一个队列中,队列中的第一个事务称为leader, 其他事务称为follower, leader 控制着follower 的行为。BLGC 的步骤分为以下三个阶段:
ssdsdd①、Flush 阶段,将每个事务的二进制日志写入内存中。
ssdsdd②、Sync 阶段,将内存中的二进制日志刷新到磁盘,若队列中有多个事务,那么仅一次fsync 操作就完成了二进制日志的写入,这就是BLGC 。
ssdsdd③、Commit 阶段, leader 根据顺序调用存储引擎层事务的提交, InnoDB 存储引擎本就支持group commit, 因此修复了原先由于锁 prepare_commit_mutex 导致 group commit 失效的问题。
ssdsd当有一组事务在进行Commit 阶段时,其他新事物可以进行 Flush 阶段,从而使 group commit 不断生效。当然group commit 的效果由队列中事务的数量决定,若每次队列中仅有一个事务,那么可能效果和之前差不多, 甚至会更差。但当提交的事务越多时, group commit 的效果越明显,数据库性能的提升也就越大。
ssdss参数 ③ :binlog_max_flush_queue_time: 用来控制 Flush 阶段中等待的时间,即使之前的一组事务完成提交, 当前一组的事务也不马上进入Sync 阶段,而是至少需要等待一段时间。这样做的好处是group commit 的事务数量更多,然而这也可能会导致事务的响应时间变慢。该参数的默认值为0, 且推荐设置依然为0。除非用户的MySQL 数据库系统中有着大量的连接(如100 个连接) ,并且不断地在进行事务的写入或更新操作。
💖感谢各位的暴击三连~💖
这篇关于MySQL:事务(事务的实现之undo、purge、group commit)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




