本文主要是介绍广州大学机器学习与数据挖掘实验三:图像分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
相关资料
广州大学机器学习与数据挖掘实验一:线性回归
广州大学机器学习与数据挖掘实验二:决策树算法
广州大学机器学习与数据挖掘实验三:图像分类
广州大学机器学习与数据挖掘实验四:Apriori算法
四份实验报告下载链接🔗
图像分类
- 相关资料
- 一、实验目的
- 二、基本要求
- 三、实验软件
- 四、实验内容
- 五、实验过程与实现
- 六、实验结果与评估
- 七、实验代码
一、实验目的
本实验课程是计算机、智能、物联网等专业学生的一门专业课程,通过实验,帮助学生更好地掌握数据挖掘相关概念、技术、原理、应用等;通过实验提高学生编写实验报告、总结实验结果的能力;使学生对机器学习算法、数据挖掘实现等有比较深入的认识。
1.掌握机器学习中涉及的相关概念、算法。
2.熟悉数据挖掘中的具体编程方法;
3.掌握问题表示、求解及编程实现。
二、基本要求
1.实验前,复习《机器学习与数据挖掘》课程中的有关内容。
2.准备好实验数据。
3.编程要独立完成,程序应加适当的注释。
4.完成实验报告。
三、实验软件
使用Python或R语言实现。
四、实验内容
猫狗图像识别实验
整个数据集包含25000张狗和猫的图像,其中,每个图像的文件名就包含了标签,例如文件名cat0.jpg表示这是猫的图像。请将数据集的前面70%样本作为训练集,后面30%样本作为测试集。利用训练集设计一个分类模型,在测试集验证分类精度。
五、实验过程与实现
- 迁移学习:使用预训练模型:
用别人训练好的卷积神经网络模型权重作为我们的初始化,提取特征。
然后接上我们自定义的全连接层
base_model = ResNet50(include_top='False') #下载到本地的预训练模型
x= base_model.output
x = Dense(512, activation='relu')(x)
x= Dropout(0.2)(x)
x = Dense(64, activation='relu')(x)
preds=Dense(CLASS_NUM,activation='softmax')(x)
model=Model(inputs=base_model.input,outputs=preds)for layer in base_model.layers: #开放预训练模型所有层layer.trainable = True
- 预训练模型的选择——ResNet50:
自从深度学习发展以来,从最经典的LeNet、AlexNet、VGG,到Inception系列、Resnet系列,再到这两年最流行、精度sota的NasNet系列和EFficientNet系列,我们拥有很多经过大量训练的预训练模型选择。
针对本题的数据,猫狗训练集分别为8750张,测试集分别为3750张,考虑到数据不多,不需要使用高精度复杂模型,我们选择了低精度简单模型ResNet50,加快我们的训练过程,并且得到一个不错的结果。
-
数据增广:
因为数据量还挺适合的,不多也不少,但往往在实际情况下训练模型会导致过拟合,选择数据增广,则可以扩增我们的数据集,避免我们的训练产生过拟合,获得更好的结果。
width_shift_range=0.2, #宽度平移
height_shift_range=0.1, #高度平移
shear_range=0.1, #剪切概率
zoom_range=0.1 #缩放概率 -
优化函数:
Adam优化算法:对随机目标函数执行一阶梯度优化算法,比SGD等表现更好。 -
实现细节:
因为题目要求以前面70%样本作为训练集,后面30%样本作为测试集,因此不能采用随机划分数据集,采用的方法是用代码去进行固定的划分数据集。 -
实验实现机器:
Google提供的免费GPU资源,线上连接Colab使用,显卡为teslaT4。
六、实验结果与评估
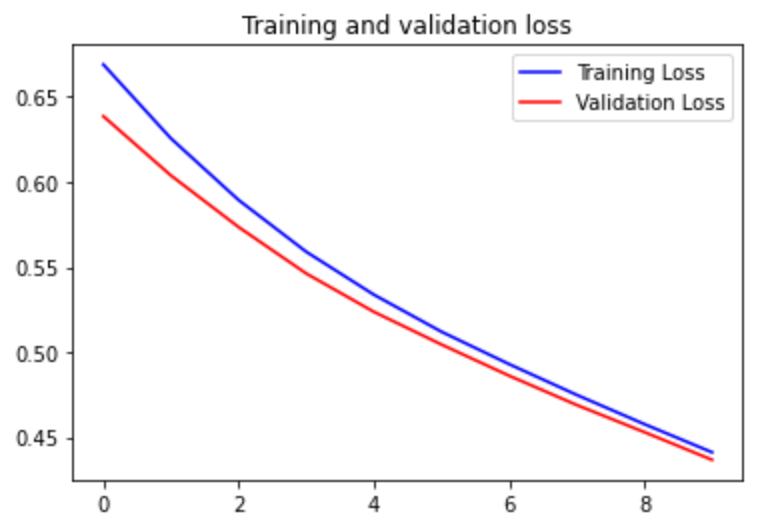
训练集和验证集训练10代的损失:
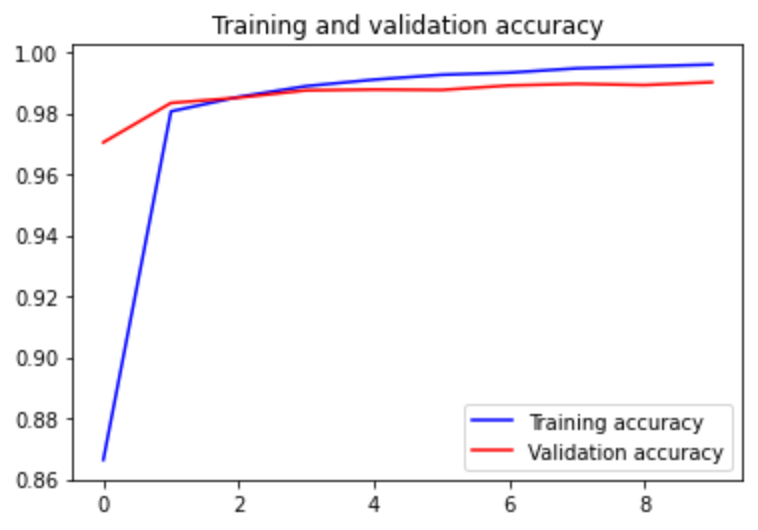
训练集和验证集训练10代的精度:
具体训练过程如下:

评估:
(一)可以看到,最终训练集和验证集的精度都达到了99%以上,说明该模型效果还不错。
(二)在这训练的10个epoch中,训练集和验证集的loss都是同步下降,而精度同步上升,说明训练集与验证集分布差异不大,并且网络在训练过程中使用了dropout、数据增强等正则化手段,使得训练出来的网络结构的参数不会异常过大,不容易过拟合,可以将该模型很好的推广到别的数据中。
(三)值得注意的地方是验证集在第一个epoch的精度就达到了0.9704,说明模型所用到的数据增强的效果显著,将为训练的验证集模型也能精准分类。
(四)这里设置的训练集和验证集的batch_size均为125,训练集有25000*0.7 = 17500张图片,17500/125 = 140,说明需要140个batch才能训练完一轮训练集,因此10个epoch,每个epoch需要训练140个batch的图片,每个batch训练125张图片,这里说明该模型充分训练了所划分的17500张猫狗数据集。
七、实验代码
import keras
from keras.layers import Dense,GlobalAveragePooling2D,Dropout,Flatten,BatchNormalization,Input
from keras.applications import MobileNet,ResNet50,VGG16,VGG19,InceptionV3,InceptionResNetV2,NASNetLarge,ResNet50 #Efficientnet
from keras.applications.resnet50 import preprocess_input
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Model
from keras.optimizers import Adam,Nadam
import time
import os
import shutil# 切割数据集
path = "./"
data = os.listdir(path+'train')
print(len(data))if not os.path.exists(path+'cat'):os.makedirs(path+'cat')if not os.path.exists(path+'dog'):os.makedirs(path+'dog')if not os.path.exists(path+'new_train'):os.makedirs(path+'new_train')if not os.path.exists(path+'test'):os.makedirs(path+'test')if not os.path.exists(path + 'new_train/train_cat'):os.makedirs(path + 'new_train/train_cat')if not os.path.exists(path + 'test/vail_cat'):os.makedirs(path + 'test/vail_cat')if not os.path.exists(path + 'new_train/train_dog'):os.makedirs(path + 'new_train/train_dog')if not os.path.exists(path + 'test/vail_dog'):os.makedirs(path + 'test/vail_dog')for str in data:old = path+ 'train/' + strif str.split('.')[0] =='dog':new = path + 'dog/' + strelif str.split('.')[0] =='cat':new = path + 'cat/' + strshutil.copyfile(old, new)cat_data = os.listdir(path+'cat')
print(len(cat_data))
dog_data = os.listdir(path+'dog')
print(len(dog_data))num = 12500 *0.7
print(num)i = 0
for str in os.listdir(path+'cat'):i +=1old = path + 'cat/' + strstt = strarr = stt.split('.')if (int(arr[1]) < num):new = path + 'new_train/train_cat/' + strelse:new = path + 'test/vail_cat/' + strshutil.copyfile(old, new)i = 0
for str in os.listdir(path+'dog'):i +=1old = path + 'dog/' + strstt = strarr = stt.split('.')if (int(arr[1]) < num):new = path + 'new_train/train_dog/' + strelse:new = path + 'test/vail_dog/' + strshutil.copyfile(old, new)base_model = ResNet50(include_top='False') #下载到本地的预训练模型
print(base_model.summary())
CLASS_NUM=2x=base_model.output
x = Dense(512, activation='relu')(x)
x= Dropout(0.2)(x)
x = Dense(64, activation='relu')(x)
preds=Dense(CLASS_NUM,activation='softmax')(x)
model=Model(inputs=base_model.input,outputs=preds)# 预训练模型不可训练
for layer in base_model.layers: #开放预训练所有层layer.trainable = Truetrain_datagen=ImageDataGenerator(preprocessing_function=preprocess_input, #数据预处理width_shift_range=0.2, #宽度平移height_shift_range=0.1, #高度平移shear_range=0.1, #剪切概率zoom_range=0.1)test_datagen=ImageDataGenerator(preprocessing_function=preprocess_input) #数据预处理
root_dir = './'
TRAIN_DIR= root_dir + 'new_train/'
Test_Dir = root_dir + 'test/'train_generator=train_datagen.flow_from_directory(TRAIN_DIR,target_size=(224,224), #ResNet50color_mode='rgb',batch_size=125, #防止内存耗尽class_mode='categorical',shuffle=True)test_generator=test_datagen.flow_from_directory(Test_Dir,target_size=(224,224), #ResNet50color_mode='rgb',batch_size=125, #防止内存耗尽class_mode='categorical',shuffle=False)
# 以比较小的速率训练
model.compile(optimizer=Adam(lr=1e-5),loss='categorical_crossentropy',metrics=['accuracy'])
step_size_train=train_generator.n//train_generator.batch_size
step_size_test=test_generator.n//test_generator.batch_sizestart_time = time.time()
history = model.fit_generator(generator=train_generator,steps_per_epoch=step_size_train,epochs=10,validation_data = test_generator,validation_steps = step_size_test)print("Model run time: %.2f s"%( (time.time()-start_time)))import matplotlib.pyplot as plt
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']epochs = range(len(acc))plt.plot(epochs, acc, 'b', label='Training accuracy')
plt.plot(epochs, val_acc, 'r', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()plt.figure()plt.plot(epochs, loss, 'b', label='Training Loss')
plt.plot(epochs, val_loss, 'r', label='Validation Loss')
plt.title('Training and validation loss')
plt.legend()plt.show()
这篇关于广州大学机器学习与数据挖掘实验三:图像分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





