本文主要是介绍Pandas 按周、月、年、统计数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Pandas 按周、月、年、统计数据
第一步
将日期转为时间格式 并设置为索引
import pandas as pd
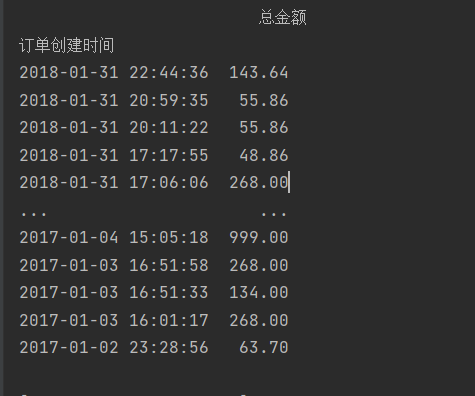
data=pd.read_excel('5\TB201812.xls',usecols=['订单创建时间','总金额'])
print(data)
data['订单创建时间']=pd.to_datetime(data['订单创建时间'])
data=data.set_index('订单创建时间')
print(data)
按周、月、季度、年统计数据
import pandas as pd
data=pd.read_excel('5\TB201812.xls',usecols=['订单创建时间','总金额'])
data['订单创建时间']=pd.to_datetime(data['订单创建时间'])
data=data.set_index('订单创建时间')
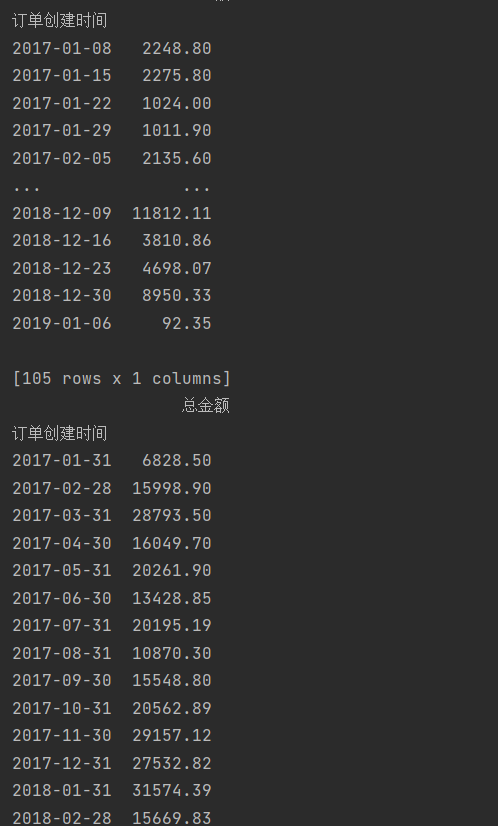
print(data.resample('w').sum())
print(data.resample('m').sum())
print(data.resample('Q').sum())
print(data.resample('AS').sum())
使用to_period()方法 优化
按月、季度和年显示数据(不统计数据)
import pandas as pd
data=pd.read_excel('5\TB201812.xls',usecols=['订单创建时间','总金额'])
data['订单创建时间']=pd.to_datetime(data['订单创建时间'])
data=data.set_index('订单创建时间')
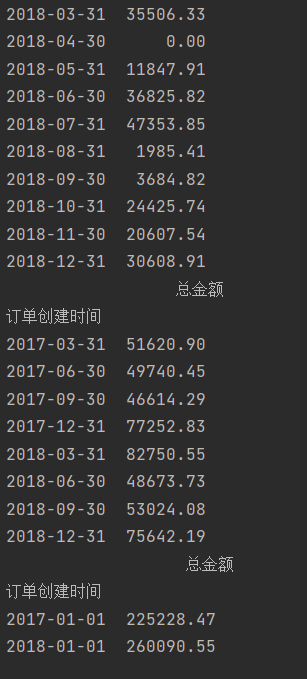
print(data.resample('w').sum().to_period('w'))
print(data.resample('m').sum().to_period('m'))
print(data.resample('q').sum().to_period('q'))
print(data.resample('as').sum().to_period('a'))
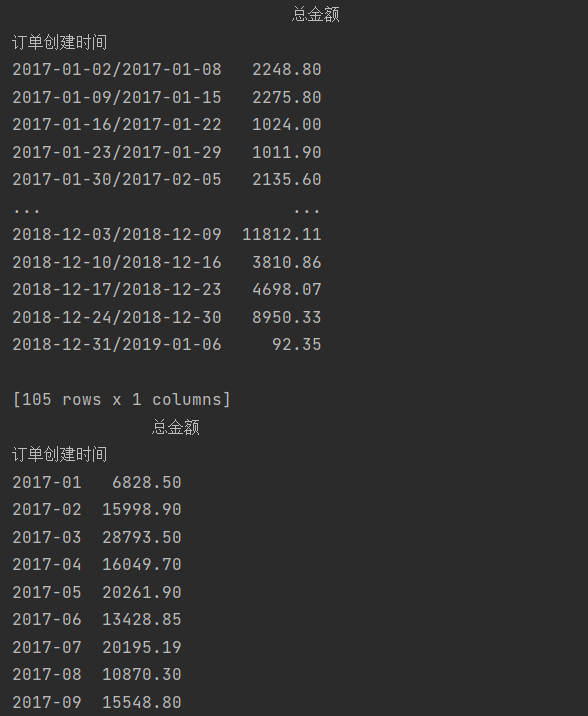

与之前相比 日期的显示方式发生了改变
这篇关于Pandas 按周、月、年、统计数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!