本文主要是介绍因果论(五)——Structural Causal Model(SCM 结构因果模型、函数模型和图模型),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、核心思想
SCM的核心思想是因果图,因果图之前已经介绍过,SCM和RCM是等价的。
SCM的关键在于图模型,来源于贝叶斯网络,将Bayes网络加上外部干预,用来定义外部干预的因果作用和描述多个变量之间的因果关系,利用因果网络不仅能定量评价因果作用,还能定性确定混杂因素,用于从数据挖掘因果关系
二、结构方程
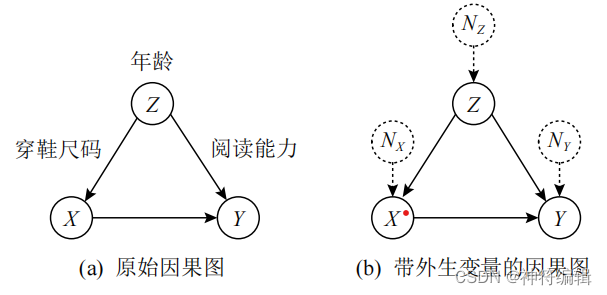
与代数方程不同,结构方程其代表 变量的生成机制,只能由等式右边对左边赋值,而不能随意变换方向。外生变量描述的是对应节点变量的所有随机因素,其自身具有确定性的概率分布,通常 未被观测也无法进行控制,而且 SCM 中假设所有外生变量之间相互独立。
三、SCM基本概念
SCM就是加入do算子,前文已经介绍过。
根据do操作,变可以定义因果效应,比如二值得Z对于Y的平均因果效应定义为:
上面do操作下的期望,分别对应do操作下的分布。
四、d分离
前文已经介绍过
五、前门法则和后门法则
六、因果模型中的概率预测
已知一个函数因果模型(如下式),如果我们从pai的每个成员画一个指向Xi的箭头,那么得到的图G称为因果图。如果因果图是无欢的,那么对应的模型称为半马尔科夫模型,变量X的值由变量U的值唯一决定。在这样的条件下,联合分布P(x1,x2,...,xn)由误差变量的分布P(u)唯一决定。如果除了无环以外,误差项是联合独立的,那么该模型称为马尔科夫模型。
七、函数模型中的反事实
反事实语句不能在随机因果网络的框架下定义。
这篇关于因果论(五)——Structural Causal Model(SCM 结构因果模型、函数模型和图模型)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




