本文主要是介绍python客服机器人通过数据库_智能客服小讲堂丨客服机器人如何练就巧舌慧耳?...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

用户与智能客服对话流畅,满意度高
智能客服机器人发展到今天,已经能做到与人交互自如,不仅可以听懂客户诉求,还能像人一样发声交流。那么,智能客服机器人是如何做到“以假乱真”的?
除了上期小讲堂介绍的领先的对话能力(戳这里复习→,即机器人有理解语义并生成自然语言回复的“大脑”外,还需要机器人有“耳朵”和“嘴巴”接收和传达信息。今天的智能客服小讲堂就给大家科普下,智能客服机器人的巧舌慧耳是如何练成的。
三大技术加持
人机对话更自然
人类最自然的交互是通过耳朵去接收信息,通过嘴巴说出诉求,它们分别对应智能客服交互中最基础的两种技术:语音识别(Automatic Speech Recognition)和语音合成(Text To Speech)。
同时,人和人非面对面交流时,可通过声音大概判断对方身份,这与客服系统中的声纹识别技术(Voiceprint Recognition)相对应。
在智能客服的应用中
人机交互的过程大致可描述为:用户与机器人进行语音对话,机器首先收集语音信息并识别对方的语音内容与身份信息,经过“中枢大脑”,即对话系统处理生成对应回复文本后,再由语音合成技术转化为声音传递给用户。
语音识别技术(ASR)
识别人说的是什么
语音识别是一种将语音转换为文本的技术。
在这里可以简单地将语音识别比做“机器的听觉系统”,它就是一种让机器通过识别和理解,然后把语音信号转变为相应的文本或命令的技术。语音识别与声学、语音学、语言学、数字信号处理理论、信息论、计算机科学等众多学科紧密相连,是一个多学科交叉的领域。
那么,机器到底如何识别人说的是什么呢?
首先,机器会对人的大段声音进行录入,语音经过“分帧”被分为若干小段,然后机器将每个小段中的发音特征提取出来,并将发音特征相同的音素归为一类,这部分需要用到事先训练好的声学模型。
分类后的音素如何对应到具体文字?
这就要应用到语言模型。语言模型中收录了不同语言的发音特点和语言表达特点,计算机通过与已有数据库比对即可实现语音识别。而其识别准确率与语言模型和声学模型息息相关,因为中文中同音不同字的情况很多,比如音素“ma” 就可以对应“妈”、“嘛”、“马”、“骂”等多个文字,在机器识别到“ma”后,需要经过大量语料训练的声学模型和语言模型来判别确认,才能保证语音识别的准确率。
百度智能云智能客服依托百度语音识别技术为企业提供语音门户的客户服务,是智能客服与用户交互的首要窗口。
百度智能云语音识别技术采用业界首次成功应用的流式多级截断注意力模型(SMLTA),并且在LSTM和CTC的基础上引入了注意力机制,进而获取更大范围和更有层次的上下文信息,识别准确率高达97%。
百度智能云语音识别模型具备四大创新点:
截断、流式、多级、基于CTC&Attention实现高精度、低功耗,线上应用相对准确率提升15%,且针对离线语音文件识别由同一个ASR引擎的不同接口支持,无需采购两个ASR引擎;
在算法工程上,支持8k与16k模型混合部署在一个集群,统一对外接口服务,同时支持IVR与Mobile app语音应用,是低延迟、高并发的企业级语音服务;
采用高可用流式传输语音识别与语音合成协议,实现全双工流式交互;
定制化训练方面,允许私有化部署语言模型训练平台,并且可以由甲方自行根据新词、热词、专属名词需要定制训练,全面支持热词、语句、语篇三种优化训练。
语音合成技术(TTS)
让机器发声更像真人
语音合成技术像是一种逆向的语音识别技术,它作为智能客服的“嘴巴”,会将整个经过智能客服的“耳朵”、“大脑”等技术处理的文本,用合成音这个“嘴巴”输出。
因此,小白客户评判一款智能客服产品好坏的标准就是合成音听起来像不像人,这也是直达普通用户的客服信息载体。
此外,机器“朗读”有不同方式。
第一种是串联合成方法,即需要事先通过大量的语音录音训练,机器从中提取基本单元,对应相应的文本将基础单元拼凑起来。
第二种是基于参数的语音合成,即根据文本对应的声学特征的统计模型来预测基频、共振峰频率等相关语音参数,然后把参数转化为波形。为提高机器发声的拟人度,语音合成还引入了神经网络进行机器学习,模仿人发声的音长、韵律、重音等特征,让机器发声更像真人。
需要注意的是,合成音的好坏评价具有主观性,因此,语音合成算法拟人度评测需要投入大量人力去做MOS评测或者AB test。由于其本质还是深度学习算法,发声声优的有效数据覆盖面越广,数据量越大效果越好。而好的合成音会让用户在发音韵律、发音停顿上都有上佳感受,至于音色和语调等则与声优本身发声特点,或者录制时情感特征关联密切。
2013年4月,百度智能云开始对语音合成进行研究。从在线合成发布,hts的离线参数合成,到形成DNN的参数合成系统,EMPHASIS声学建模,以及现在Tacotron+wavRNN的联合训练模式,百度智能云技术效果显著,逐渐形成了端对端的深度学习解决方案。
目前,百度智能云可提供多种客服女声合成音,支持客户对语速、语调、音色进行自定义修改,且具备低延时、高并发优势。
声纹识别技术(VPR)
精准判断电方身份
智能客服是名副其实的“顺风耳”,也就是说,机器可以通过来电方的声纹判断或验证对方的身份。
这就衍伸出了声纹识别技术的概念。具体来讲,声纹识别是生物识别技术的一种,即把声信号转换成电信号,再用计算机进行识别。
众所周知,每个人的声音都具有独特性,因此每人都独有“声音名片”。这是因为人在讲话时使用的发声器官都是独特的,它们的构造千差万别,这就造成了不同人的语音的物理属性(音质、音长、音高、音强)是不同的。而声纹技术的核心就是将说话人的声音进行向量化、特征化,以取得其核心特征。声音特征的差异最终表现为语音图谱上参数的差异,然后声纹技术就可以根据特征参数,确定是否为同一人。
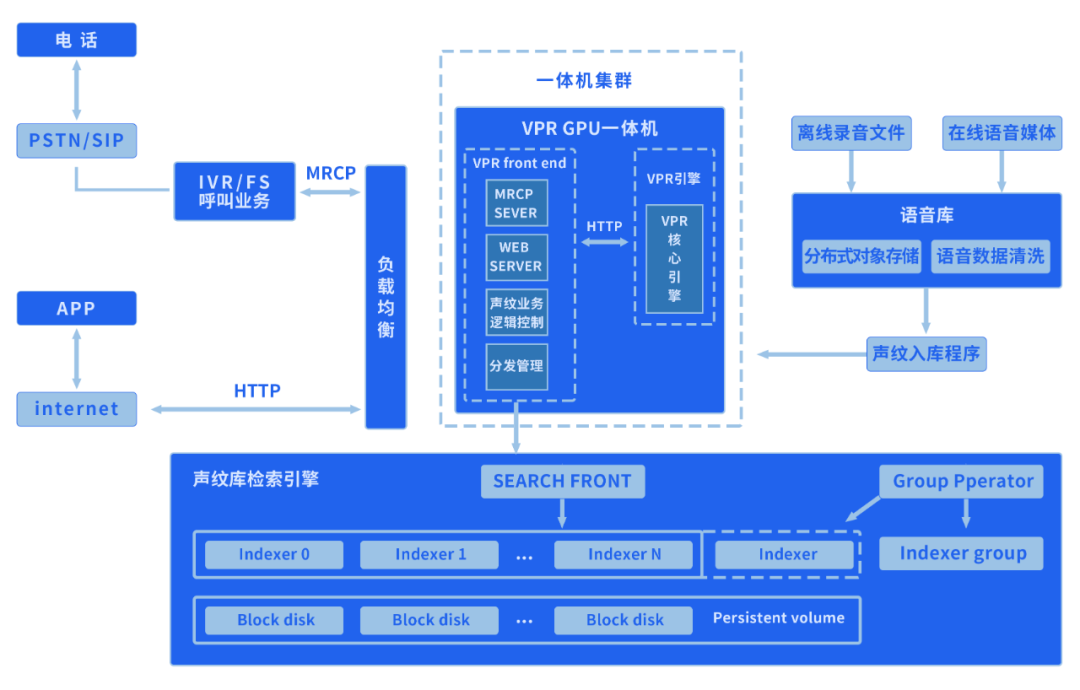
而且,任务和应用不同,使用的声纹技术也不同。
目前,百度智能云的声纹技术主要包括
1:1核验(文本无关/文本相关)
1:N比对(文本无关/文本相关)
N:N声纹聚类
话者分离
性别识别
简单举几个例子,外呼中可以利用声纹核验技术核验被呼叫人身份;在离线转写存量音频时,用话者分离技术区分客服或客户身份;通过1:N检索判断黑产用户,协助银行构建信用卡申请人黑名单;通过声纹和识别技术,对摘机前振铃识别进行分析,区别欠费、停机、无人接听等电话状态,避免客服人员一直耗时耗力听完之后再判断业务码等。
AI技术驱动
持续优化用户体验
百度智能客服语音技术涵盖语音识别、语音合成、声纹识别三大技术,构成了智能客服机器人与客户交互交流的重要桥梁,也是智能化最重要的基础能力之一。
在经过百度智能云工程化封装后,以上各能力都可以以私有云或公有云PaaS等多种形式呈现,而且整体性更强,优化速度更快,输出渠道更加多元化。
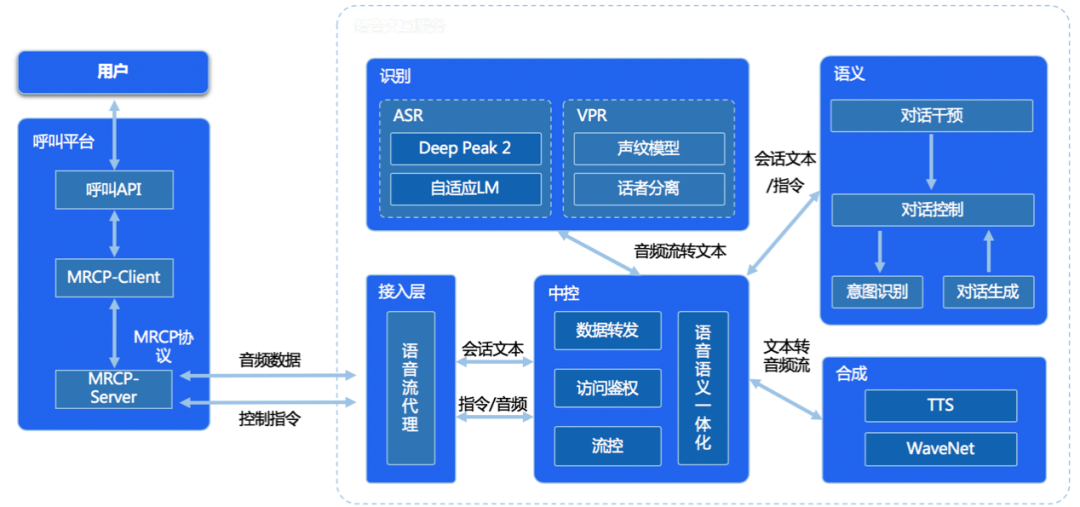
(智能语音呼叫中心整体解决方案)
面向未来,百度智能云智能客服将持续以强有力的基础技术为引擎,在不断优化用户体验的同时,打造领先的客户服务联络中心,助力企业智能化转型。




这篇关于python客服机器人通过数据库_智能客服小讲堂丨客服机器人如何练就巧舌慧耳?...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




