本文主要是介绍医学图像 | DualGAN与儿科超声心动图分割 | MICCAI,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
-
文章转自微信公众号:「机器学习炼丹术」
-
作者:炼丹兄(已授权)
-
联系方式:微信cyx645016617(欢迎交流共同进步)
-
论文名称:“Dual Network Generative Adversarial Networks for Pediatric Echocardiography Segmentation”
0 准备工作
0.1 生词
- Pediatric 儿童的
- Pediatric echocardiography 小儿超声心动图
- CHD : congenital heart disease 先天心脏病
0.2
1 综述
为了获得高质量的分割结果,目前临床上小儿超声心动图的分割主要由超声工作者手工完成,这既费时费力,又高度依赖于超声工作者的专业水平。为了解决这些问题,本文提出了一种新的卷积神经网络(CNN)结构,称为双网络一般对抗网络(DNGAN)。DNGAN由一个产生器和两个鉴别器组成,产生器采用并行对偶网络来提取更多有用的特征以提高性能。我们使用双重鉴别器来强制生成器学习更多的空间特征,并更准确地分割左心的边缘。
2 问题提出

图中是儿童的心脏的左心室和左心房的分割标注label,可以发现:左心房的变化比较明显,并且内壁会存在模糊,因此目前的对于四腔的分割存在一下挑战:
(1)因为噪音和模糊出现的边界不清晰;
(2)心脏的尺寸对于不同人是不同的;
(3)每一个心动周期心房和心室的变化是不同的。
3 模型结构

这个DNGAN的结构如上所示:包含一个生成器和两个鉴别器。
3.1 generator
由一个U-net和FCN并行构成,分别从输入图片中提取两种特征,然后特征进行像素相乘.
FCN输出的特征图为 f 1 f_1 f1,U-net输出的特征图为 f 2 f_2 f2,那么由generator输出的图像分割结果为 F G = f 1 × f 2 F_G = f_1 \times f_2 FG=f1×f2.
3.2 discriminator
是一个六层的全卷积网络,然后分别用7,5,3作为卷积核的大小。卷积层后面跟着BN层和LeakReLU激活层。
使用的是multi-scale L1损失,类似于2014年的图像分割网络Richer conv net。
4 损失
4.1 generator损失
先回顾一下一般的GAN的损失函数:
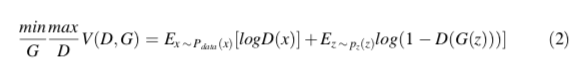
在公式中:
- x是real image
- z是random import for generator
- G(z)是生成的mask
- D(x) 是判别起判断x是true的概率
再来看一下DNGAN的损失函数:
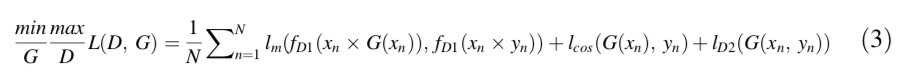
-
N为样本的数量;
-
x n x_n xn为某一张儿童超声心动图四腔图, y n y_n yn为对应的ground truth;
-
l m l_m lm是mean absolute error,也就是我们说的L1loss;
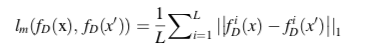
这个可以看到, f D ( x ) f_D(x) fD(x)是discrimintor提取的特征,L表示discrimintor的层数,所以 f D i ( x ) f_D^i(x) fDi(x)表示discrimintor第i层提取出来的特征图 -
l c o s l_{cos} lcos就是常说的cross entropy;
-
l D 2 l_{D_2} lD2是第二个discriminitor的损失函数,也比较复杂我们来看一下,这个损失函数分辨的是:输入的是生成的mask还是真实的mask。
5 数据描述
- 数据集包含87个儿童超声心动图;
- 搜集的是0到10岁的健康的儿童,每个视频至少包含24帧和一个完成的心动周期;
- 随机选择67个视频,抽取了1765个图片作为训练集;剩下20个视频抽取451个视频作为测试集;
- 原始图片的分辨率是1016x708或者636x432,所有的图片经过中心crop后变成704x704和448x448;
6 总结
1, 这篇文章的结果和过程存在疑点,文章中出现一处公式的疑似符号错误。
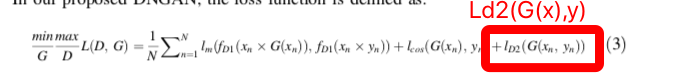
2, 文章中的并没有给出第二个discrimintor的loss使用MSE和BCE的平均值的原因,不确定是否之前就有文章已经讨论过这个样做的优势。从结果来看,使用GAN的框架来训练造成的提升并不高,反而提升分割精度的重点应该是分割网络的特征融合和宽度增加。
3, 文章使用GAN应用在儿童超声心脏病上的出发点很好,希望可以帮助更多的儿童摆脱先天性心脏病的困扰。
这篇关于医学图像 | DualGAN与儿科超声心动图分割 | MICCAI的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







