本文主要是介绍【Python原创毕设|课设】基于(Flask、机器学习、含报告)朴素贝叶斯的垃圾邮件分类算法与检测系统-文末附下载方式以及往届优秀论文,原创项目其他均为抄袭,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于(Flask、机器学习)朴素贝叶斯的垃圾邮件分类算法与检测系统(获取方式访问文末官网)
- 一、项目简介
- 二、开发环境
- 三、项目技术
- 四、功能结构
- 五、运行截图
- 六、功能实现
- 七、源码获取
一、项目简介
随着信息时代的快速发展,电子邮件作为人们日常沟通的重要方式也变得日益普及。然而,随之而来的垃圾邮件问题不可避免地困扰着用户,对邮件通信质量造成负面影响。为了解决这一问题,我们开发了基于朴素贝叶斯算法和TF-IDF特征提取的邮件分类系统。
技术方面,我们借助Python编程语言和Sklearn、Flask、Echarts等库与框架,构建了这个功能强大的系统。朴素贝叶斯算法被选作核心分类算法,通过Sklearn库实现模型训练和分类,以提高系统的准确性。TF-IDF算法用于邮件特征提取,进一步优化了分类性能。
系统功能包括邮件检测与数据管理两大模块。邮件检测模块通过朴素贝叶斯算法和TF-IDF特征提取,对邮件进行准确分类,解决了垃圾邮件的问题。数据管理模块涵盖了数据存储、分析和可视化,通过Echarts库将检测日志内容以词云、分类饼状图和流量折线图的形式进行可视化展示,使用户能够直观了解邮件流量和分类情况。
这个系统的意义在于为用户提供了一个高效、智能的垃圾邮件分类解决方案。通过朴素贝叶斯算法,我们可以在海量的邮件中迅速准确地筛选出垃圾邮件,提升了邮件通信质量,释放了邮箱存储空间。同时,数据分析和可视化功能让用户能够更好地了解邮件流量和分类情况,为邮件管理提供了有力的支持。这样的系统符合现代社会信息化发展的趋势,对个人、企业和社会都具有积极的意义。
二、开发环境
| 开发环境 | 版本/工具 |
|---|---|
| PYTHON | 3.6.8 |
| 开发工具 | PyCharm |
| 操作系统 | Windows 10 |
| 内存要求 | 8GB 以上 |
| 浏览器 | Firefox (推荐)、Google Chrome (推荐)、Edge |
| 数据库 | MySQL 8.0 (推荐) |
| 数据库工具 | Navicat Premium 15 (推荐) |
| 项目框架 | FLASK、Skite-learn |
三、项目技术
Python: 作为开发语言,用于编写后端逻辑和数据处理。
Flask: Python的Web框架,用于搭建后端数据接口和处理HTTP请求。
PyMySQL: 用于Python与MySQL数据库的交互,实现数据的存储和读取。
Echarts: JavaScript的数据可视化库,用于将数据转化为图表形式展示给用户。
LAYUI: 轻量级前端UI框架,用于构建用户友好的交互界面。
JavaScript: 用于实现前端交互和处理用户输入。
HTML和CSS: 用于构建前端界面和样式设计。
scikit-learn、pandas和numpy: Python的数据处理和机器学习库,用于数据预测和分析。
AJAX: 用于实现前后端数据交互,异步请求后端数据接口。
MySQL: 数据库管理系统,用于持久化数据。
四、功能结构
-
系统功能结构图:
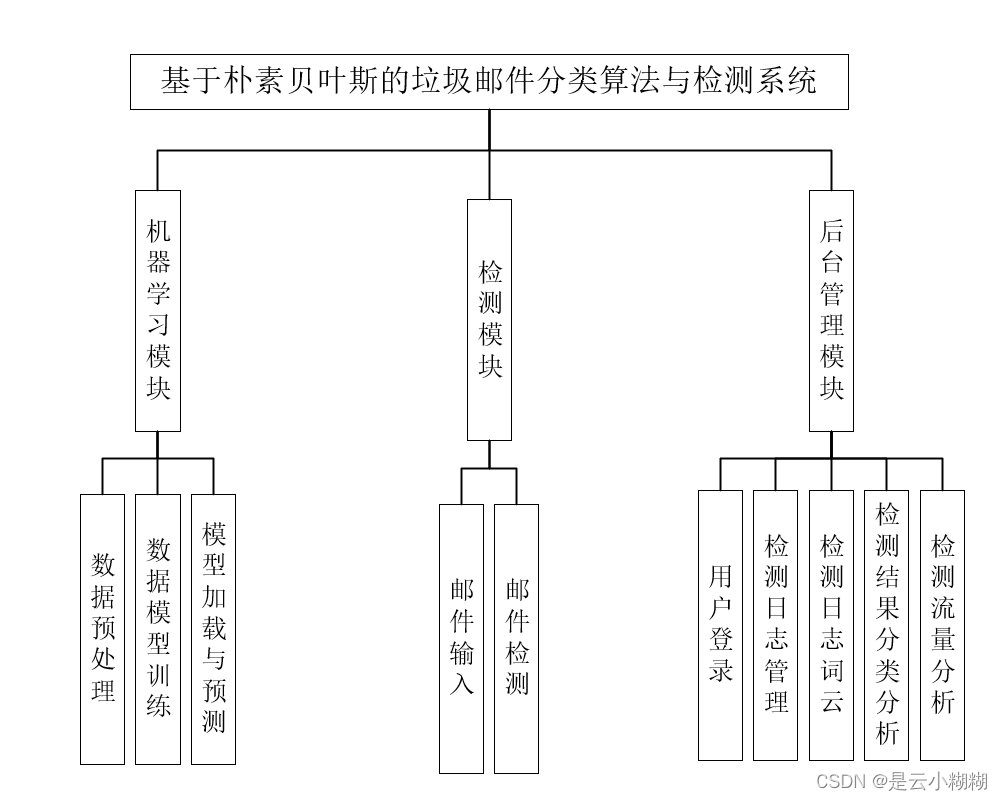
-
系统详细报告论文截图:
-
邮件检测与分类模块:
-
功能描述
用户可以将邮件内容输入系统,系统基于朴素贝叶斯算法和TF-IDF特征提取进行邮件分类。将邮件分为垃圾邮件和正常邮件,以净化用户的邮箱。
-
技术实现简介
使用Sklearn库实现朴素贝叶斯算法模型的训练,将训练好的模型应用于用户输入的邮件内容,进行分类判别。TF-IDF算法用于对邮件内容进行特征提取,生成特征向量。
-
-
数据管理模块:
-
功能描述
此模块负责存储和管理系统处理的邮件数据,包括垃圾邮件和正常邮件的分类结果,以及相关的检测日志。
-
技术实现简介
使用MySQL数据库进行数据存储,将邮件分类结果、检测日志等信息存储于数据库中。通过SQL语句实现对数据的存取、管理、查询等操作。
-
-
可视化分析模块:
-
功能描述
提供对系统运行情况的数据分析和可视化展示,包括词云展示常见关键词、饼状图展示邮件分类比例、折线图展示检测流量趋势等。
-
技术实现简介
使用Echarts技术实现数据的可视化分析,根据数据从数据库中提取相应信息并以图表的形式展示。使用JavaScript对Echarts进行配置和调用,呈现给用户直观的数据分析结果。
-
这三个模块共同构成了整个系统的功能结构。邮件检测与分类模块解决了垃圾邮件分类问题,数据管理模块负责数据的存储和管理,可视化分析模块则通过图表直观展示数据分析结果,为用户提供全面的邮件管理解决方案。
五、运行截图
检测页面

检测结果

系统登录页面

后台管理首页面

日志管理模块页面

检测日志词云分析

检测日志分类分析

检测日志流量分析

六、功能实现
机器学习预测核心代码
# 绘制混淆矩阵
def plot_confusion_matrix(cm, classes, title='Confusion matrix', cmap=plt.cm.Blues):plt.imshow(cm, interpolation='nearest', cmap=cmap)plt.title(title)plt.colorbar()tick_marks = np.arange(len(classes))plt.xticks(tick_marks, classes, rotation=0)plt.yticks(tick_marks, classes)thresh = cm.max() / 2.for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):plt.text(j, i, cm[i, j],horizontalalignment="center",color="white" if cm[i, j] > thresh else "black")plt.tight_layout()plt.ylabel('True label')plt.xlabel('Predicted label')def train():content_list, label_list = get_train_data() # 获取训练数据stopword_list = get_stop_word() # 获取停用词cutWords_list = split_words(content_list, stopword_list) # 分词+停用词处理counts = calc_tf(cutWords_list) # 统计词频tfidf_matrix = calc_idf(counts) # 计算概率train_X, test_X, train_y, test_y = train_test_split(tfidf_matrix, label_list, test_size=0.2,random_state=0) # 分割数据集print("训练集:", train_X[0].shape)mnb = MultinomialNB() # 创建模型startTime = time.time()mnb.fit(train_X, train_y) # 训练过程print('贝叶斯分类器训练用时%.2f秒' % (time.time() - startTime))sc1 = mnb.score(test_X, test_y) # 在测试集上计算得分print('准确率为:', sc1)y_pred1 = mnb.predict(test_X)joblib.dump(mnb, "./mnb.joblib")print('召回率为:', recall_score(test_y, y_pred1))plot_confusion_matrix(confusion_matrix(test_y, y_pred1), [0, 1])print(test_X[0])print(y_pred1[0])plt.show()
创建数据库连接核心代码
def connect(self):self.conn = pymysql.connect(host=DB_CONFIG["host"],port=DB_CONFIG["port"],user=DB_CONFIG["user"],passwd=DB_CONFIG["passwd"],db=DB_CONFIG["db"],charset=DB_CONFIG["charset"],cursorclass=pymysql.cursors.DictCursor)self.cursor = self.conn.cursor()
检测接口核心代码
import jieba
from machine_learning import predict as pt
from service.slog_service import insert_slog# 简单统计模块
# 连续字母且不成单词
# 连续数字且不具备含义
# 连续标点符号
def isPunctuation(word):'''判断是否为特殊字符'''string = "《》?“”:{}+——!~@#¥%……&*()/*-,。‘’;】【、|·,.;'][`\!$^()_"if word in string:return Trueelse:return Falsedef isChinese(word):'''判断是否为中文汉字'''for i in word:if word >= u'\u4e00' and word <= u'\u9fa5':continueelse:return Falsereturn True# 文本统计学分析
# number_minlen 字母串长度(最小长度,大于则统计)
# letter_minlen 字母串长度(最小长度,大于则统计)
# alnum_minlen 混合长度(最小长度,大于则统计)
def wordAnalysis(text, number_minlen, letter_minlen, alnum_minlen):words_arr = jieba.cut(text)word_num, words_num, punctuation_num, letter_num, number_num, alnum_num, chi_len, num_len, letter_len = 0.001, 0.001, 0.001, 0.001, 0.001, 0.001, 0.001, 0.001, 0.001for word in words_arr:word_len = len(word)if isChinese(word):if word_len >= 2:words_num += 1else:word_num += 1chi_len += len(word)else:if isPunctuation(word):punctuation_num += 1elif word_len > letter_minlen and word.isalpha():letter_num += 1letter_len += word_lenelif word_len > number_minlen and word.isdigit():number_num += 1num_len += word_lenelif word_len > alnum_minlen and word.isalnum():alnum_num += 1for i in word:if i.isalpha():letter_len += 1else:num_len += 1return word_num, words_num, punctuation_num, letter_num, number_num, alnum_num, chi_len, num_len, letter_len# 预测邮件
def predict(text):y = pt.predict([text])y = 1 if len(y) <= 0 else y[0]insert_slog({'content': text, 'result': y})return y七、源码获取
源码、安装教程文档、项目简介文档以及其它相关文档已经上传到是云猿实战官网,可以通过下面官网进行获取项目!
这篇关于【Python原创毕设|课设】基于(Flask、机器学习、含报告)朴素贝叶斯的垃圾邮件分类算法与检测系统-文末附下载方式以及往届优秀论文,原创项目其他均为抄袭的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







