本文主要是介绍学习笔记【多模态理解任务的半壁江山CLIP】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 任务:计算图片和文本之间的相似度
1. CLIP
Training
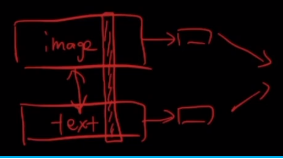
- 有监督的对比学习。通过两个encoder(Image Encoder、Text Encoder)分别对图片和文本编码。模型的训练任务是输入N个图片和N个文本的特征表示,将这些特征两两做相似度计算形成一个 N ∗ N N*N N∗N的相似度矩阵,优化目标是相似度矩阵为单位阵

效果很好的原因之一:数据量巨大,400million
Application
(1)zero-shot image classification
- 将最后的输出特征映射到分类的矩阵 W W W可以看做分类的类别特征,线性映射(乘以矩阵)可以看成是类别特征与输出特征进行相似度计算。
- 将 W W W换成对应类别的特征表示,而不再是可训练参数。将类别例如cat、dog等传入Text Encoder编码得到对应的特征;再将图像传入Image Encoder得到相应的特征,然后计算相似度
- Prompt Engineering:在实际操作中并不是直接将类别输入Text Encoder,而是会加入额外的一些提示。在CLIP中一般默认使用“an image of xxx”这样的模板。文本的选择有时候会影响分类的正确性
- 思考:语言指导的神经网络具有更好的泛化性
(2)re-ranking
CLIP虽然不能直接生成图像或文本,但是可以对生成的东西进行打分
- DALLE:给定文本生成图片(text->image),使用CLIP进行后处理。对生成的若干候选图片进行打分(文本与图片计算相似度)并选择
- CLIP-Score:给定图片生成文本(image->text,image caption),文章发现CLIP的打分与人工标注BUEU Score有高度的相关性,提出可以将CLIP-Score作为无监督的评测指标
改进工作
- data efficient:改进数据使用效率。用预训练好的encoder进行初始化
- 提升速度:知识蒸馏
2. 另外半壁
- 在做图片和文本的理解任务时,不能分别对图片和文本进行编码,之后再接下游任务,因为这样做缺少了两种模态特征之间的交互。基于此,有一些工作提出在两个encoder之间进行信息的交互。
- 但是目前还并没有一项标志性的工作。基本上是对encoder得到的embeddings之间做attention,或者concate之后输入bert_base之类的模型
学习视频参考:多模态理解类任务的标志性工作CLIP带给我们的启发
这篇关于学习笔记【多模态理解任务的半壁江山CLIP】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





