本文主要是介绍论文解读(DCRN)《Deep Graph Clustering via Dual Correlation Reduction》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
🚀 优质资源分享 🚀
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |
| 💛Python量化交易实战💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
论文信息
论文标题:Deep Graph Clustering via Dual Correlation Reduction论文作者:Yue Liu, Wenxuan Tu, Sihang Zhou, Xinwang Liu, Linxuan Song, Xihong Yang, En Zhu论文来源:2022, AAAI论文地址:download 论文代码:download
1 介绍
表示崩塌问题:倾向于将所有数据映射到相同表示。

创新点:提出使用表示相关性来解决表示坍塌的问题。
2 方法
2.1 整体框架
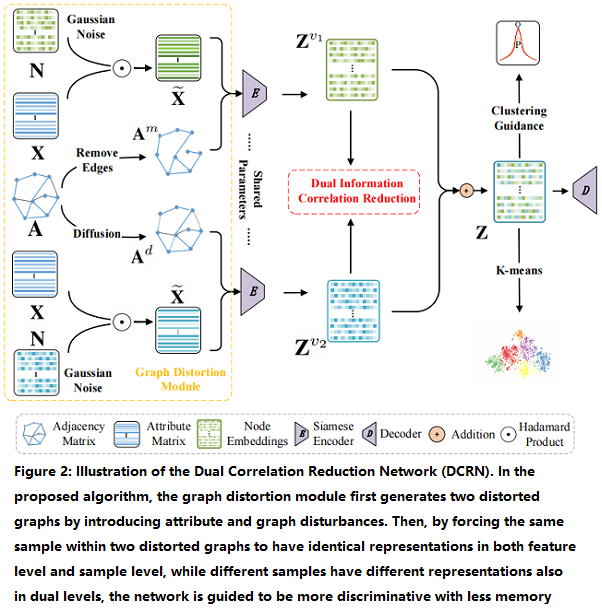
该框架包括两个模块:
-
- a graph distortion module;
- a dual information correlation reduction (DICR) module;
- a graph distortion module;
2.2 相关定义

A˜=D−1(A+I)andA˜∈RN×NA=D−1(A+I)andA∈RN×N\widetilde{\mathbf{A}}=\mathbf{D}^{-1}(\mathbf{A}+\mathbf{I})\quad\quad \text{and}
这篇关于论文解读(DCRN)《Deep Graph Clustering via Dual Correlation Reduction》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





