本文主要是介绍Python爬虫爬取录用公务员职位表并保存为Excel表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
准备工作:
Python版本 python3.7
Python库:requests, bs4, xlwt
目标网址:http://www.shaanxi.gov.cn/xw/ztzl/zxzt/zkzl/2021/2021gwy/202102/t20210222_2153937.html
网页分析:
这个网站的内容用我之前写的博客Python爬虫爬取小说中的方法是不能爬取成功的。复制了表格中的selector值,但是在调试的时候发现找不到这个selector,找不到表格的内容。
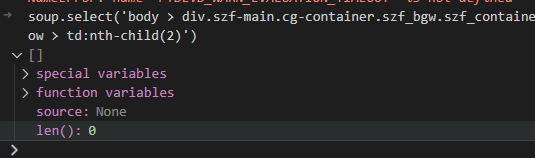
后来通过F12启动调试模式,刷新网页,然后看Network项,发现有一个html页面下载了好长时间,然后终于在里面找到了想要的数据:


找到了数据的位置,然后可以通过BeautifulSoup模块的find方法来定位元素:
import requests
import xlwt
from bs4 import BeautifulSoupurl = 'http://www.shaanxi.gov.cn/xw/ztzl/zxzt/zkzl/2021/2021gwy/202102/t20210222_2153937.html'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
data = soup.find('table')找到了整个表之后,然后就可以顺藤摸瓜,找到表内的元素,最后再按照行列将数据写入到Excel中就可以了:
xlwt是一个比较简单方便写入Excel表的模块:xlwt API介绍。主要用到的就是xlwt.Worksheet.Worksheet类的write方法,向指定坐标的单元格写入文字。
enc = response.encoding
workbook = xlwt.Workbook(encoding='utf-8')
sheet = workbook.add_sheet('sheet1')col,row = 0,0
table = data.contents[1]
for row_items in table.contents:for item in row_items.contents:item_str = item.getText().encode(enc).decode('utf-8')sheet.write(row, col, item_str)col += 1row += 1col = 0注意:网页的编码格式可以通过requests.models.Response类中的成员encoding获取。比如,这个网页的编码格式就是ISO-8859-1的格式,不是我们常用的UTF-8格式,所以在获取文字的时候需要进行一个转码的操作。

最后,保存Excel文件即可:
with open(path, 'wb') as f:workbook.save(f)完整代码
import requests
import xlwt
from bs4 import BeautifulSoupurl = 'http://www.shaanxi.gov.cn/xw/ztzl/zxzt/zkzl/2021/2021gwy/202102/t20210222_2153937.html'path = r'F:\Code\Python\crawler\陕西省2021年统一考试录用公务员职位表.xls'headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36",
}response = requests.get(url)
print("get response success!")
soup = BeautifulSoup(response.text, 'html.parser')
print("soup parser success!")
data = soup.find('table')
if len(data) > 0:print("get data sucess!")
else:print("get data failed!")exit(1)enc = response.encoding
print("encoding = ", enc)workbook = xlwt.Workbook(encoding='utf-8')
sheet = workbook.add_sheet('sheet1')col,row = 0,0
table = data.contents[1]
for row_items in table.contents:for item in row_items.contents:item_str = item.getText().encode(enc).decode('utf-8')sheet.write(row, col, item_str)col += 1row += 1col = 0print("gather data sucess!")with open(path, 'wb') as f:workbook.save(f)print("save data sucess!")生成的Excel内容:

最后
我还是个爬虫菜鸟,只能爬一些不设防的简单网页。

这篇关于Python爬虫爬取录用公务员职位表并保存为Excel表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






