本文主要是介绍YOLOv5:修改backbone为SPD-Conv,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
YOLOv5:修改backbone为SPD-Conv
- 前言
- 前提条件
- 相关介绍
- SPD-Conv
- YOLOv5修改backbone为SPD-Conv
- 修改common.py
- 修改yolo.py
- 修改yolov5.yaml配置
- 参考

前言
- 记录在YOLOv5修改backbone操作,方便自己查阅。
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入YOLO系列专栏、自然语言处理
专栏或我的个人主页查看- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
前提条件
- 熟悉Python
相关介绍
- Python是一种跨平台的计算机程序设计语言。是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。
- PyTorch 是一个深度学习框架,封装好了很多网络和深度学习相关的工具方便我们调用,而不用我们一个个去单独写了。它分为 CPU 和 GPU 版本,其他框架还有 TensorFlow、Caffe 等。PyTorch 是由 Facebook 人工智能研究院(FAIR)基于 Torch 推出的,它是一个基于 Python 的可续计算包,提供两个高级功能:1、具有强大的 GPU 加速的张量计算(如 NumPy);2、构建深度神经网络时的自动微分机制。
- YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。它是一个在COCO数据集上预训练的物体检测架构和模型系列,代表了Ultralytics对未来视觉AI方法的开源研究,其中包含了经过数千小时的研究和开发而形成的经验教训和最佳实践。
SPD-Conv
- SPD-Conv由一个空间到深度(SPD)层和一个非跨行卷积(Conv)层组成,可以应用于大多数CNN架构。SPD-Conv在不丢失可学习信息的情况下对特征图进行下采样,完全抛弃了目前广泛使用的跨行卷积和池化操作。该论文实验结果表明,在小物体和低分辨率图像上有显著的性能提高。
- 论文地址:https://arxiv.org/abs/2208.03641
- 官方源代码地址:https://github.com/LabSAINT/SPD-Conv
- 有兴趣可查阅论文和官方源代码地址。
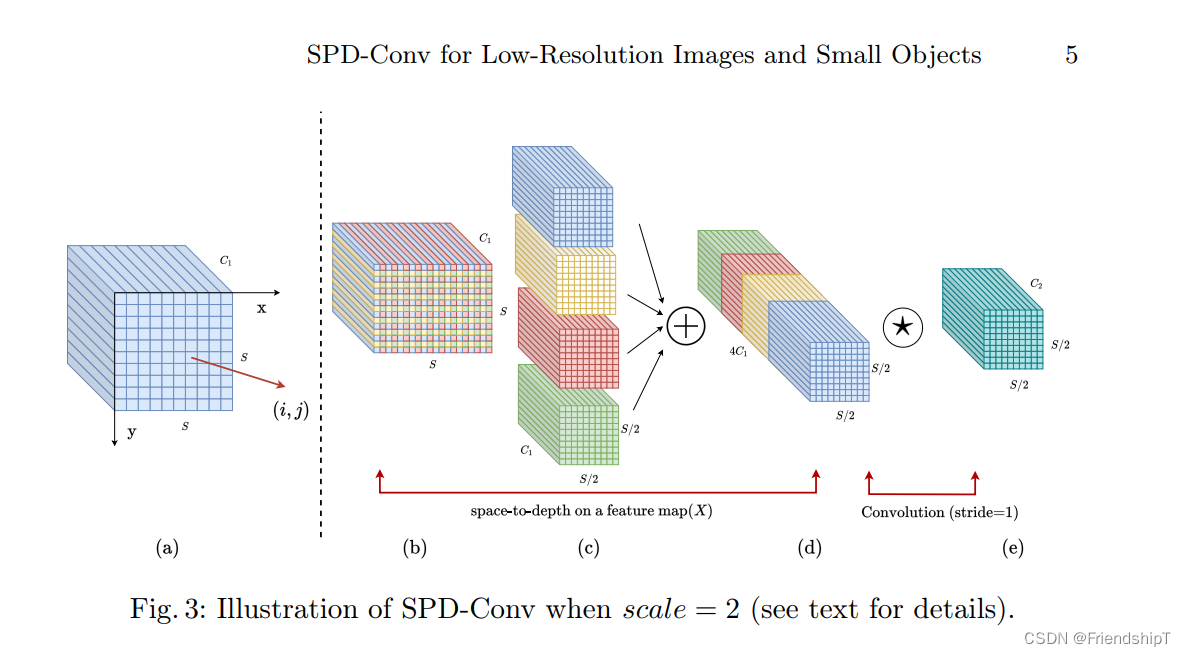
以下是使用Python实现SPD-Conv的简单例子,目的是方便大家理解SPD-Conv的操作。
import cv2
import torch
from torch import nn############## SPD-Conv ##############
class space_to_depth(nn.Module):# Changing the dimension of the Tensordef __init__(self, dimension=1):super().__init__()self.d = dimensiondef forward(self, x):return torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
############## SPD-Conv ##############if __name__=="__main__":img_tensor = torch.Tensor([[[[ 1, 2, 3, 4],[ 5, 6, 7, 8],[ 9, 10, 11, 12],[ 13, 14, 15, 16]],[[ 1, 2, 3, 4],[ 5, 6, 7, 8],[ 9, 10, 11, 12],[ 13, 14, 15, 16]],[[ 1, 2, 3, 4],[ 5, 6, 7, 8],[ 9, 10, 11, 12],[ 13, 14, 15, 16]]]])# print('img_tensor:',img_tensor)print('img_tensor.shape:',img_tensor.shape)spd = space_to_depth()res = spd.forward(img_tensor)# print('res:',res)print('res.shape:',res.shape)
img_tensor.shape: torch.Size([1, 3, 4, 4])
res: tensor([[[[ 1., 3.],[ 9., 11.]],[[ 1., 3.],[ 9., 11.]],[[ 1., 3.],[ 9., 11.]],[[ 5., 7.],[13., 15.]],[[ 5., 7.],[13., 15.]],[[ 5., 7.],[13., 15.]],[[ 2., 4.],[10., 12.]],[[ 2., 4.],[10., 12.]],[[ 2., 4.],[10., 12.]],[[ 6., 8.],[14., 16.]],[[ 6., 8.],[14., 16.]],[[ 6., 8.],[14., 16.]]]])
res.shape: torch.Size([1, 12, 2, 2])
YOLOv5修改backbone为SPD-Conv
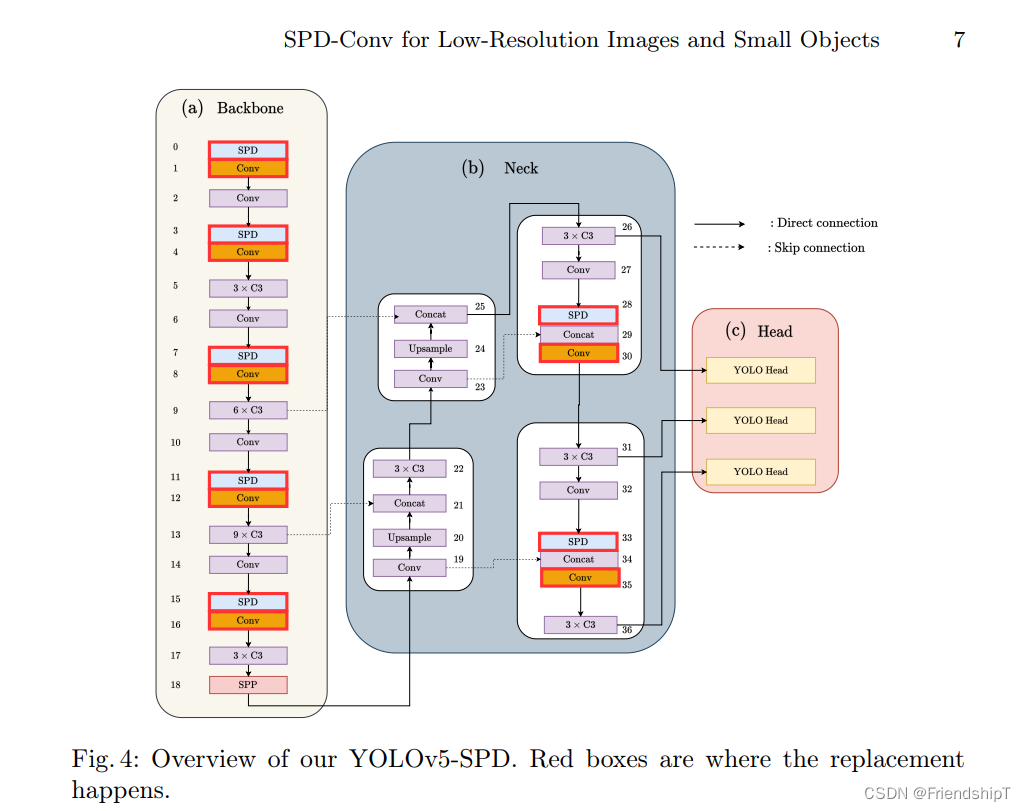
修改common.py
将以下代码,添加进common.py。
############## SPD-Conv ##############
class space_to_depth(nn.Module):# Changing the dimension of the Tensordef __init__(self, dimension=1):super().__init__()self.d = dimensiondef forward(self, x):return torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
############## SPD-Conv ##############
修改yolo.py
elif m is space_to_depth:c2 = 4 * ch[f]

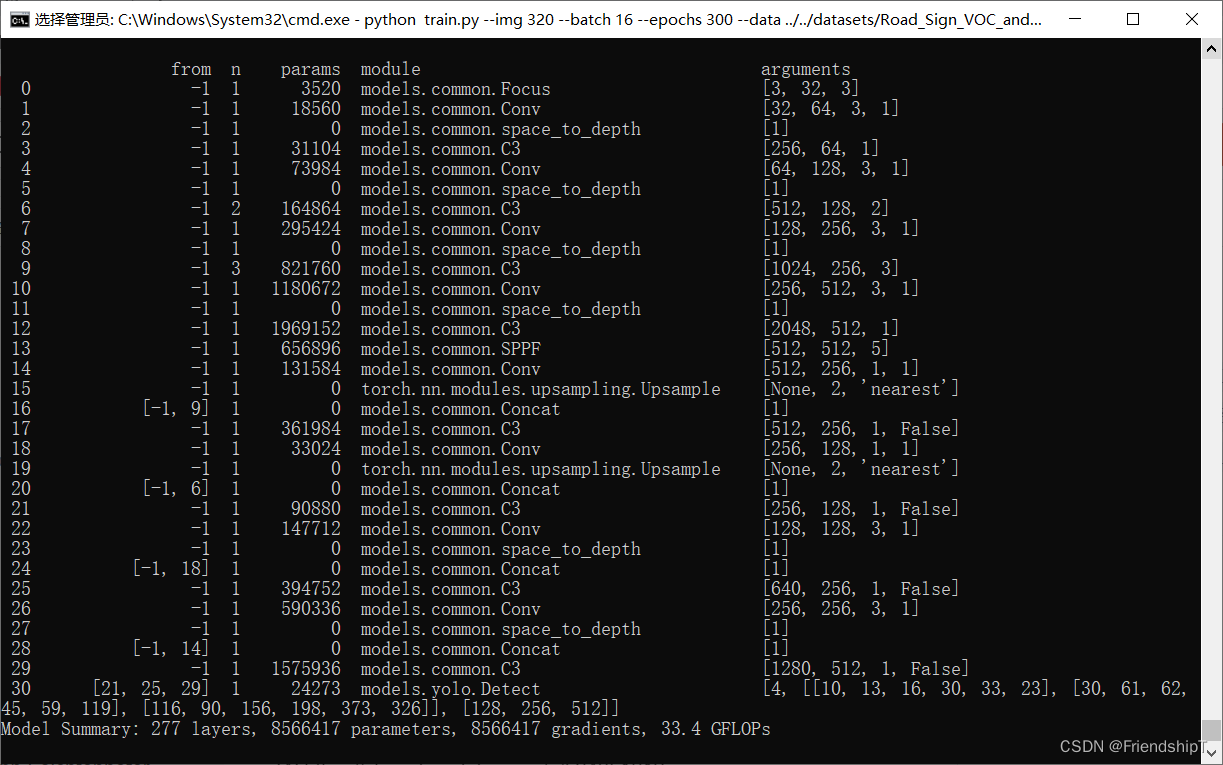
修改yolov5.yaml配置
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Focus, [64, 3]], # 0-P1/2[-1, 1, Conv, [128, 3, 1]], # 1[-1,1,space_to_depth,[1]], # 2 -P2/4[-1, 3, C3, [128]], # 3[-1, 1, Conv, [256, 3, 1]], # 4[-1,1,space_to_depth,[1]], # 5 -P3/8[-1, 6, C3, [256]], # 6[-1, 1, Conv, [512, 3, 1]], # 7-P4/16[-1,1,space_to_depth,[1]], # 8 -P4/16[-1, 9, C3, [512]], # 9[-1, 1, Conv, [1024, 3, 1]], # 10-P5/32[-1,1,space_to_depth,[1]], # 11 -P5/32[-1, 3, C3, [1024]], # 12[-1, 1, SPPF, [1024, 5]], # 13]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]], # 14[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 15[[-1, 9], 1, Concat, [1]], # 16 cat backbone P4[-1, 3, C3, [512, False]], # 17[-1, 1, Conv, [256, 1, 1]], # 18[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 19[[-1, 6], 1, Concat, [1]], # 20 cat backbone P3[-1, 3, C3, [256, False]], # 21 (P3/8-small)[-1, 1, Conv, [256, 3, 1]], # 22[-1,1,space_to_depth,[1]], # 23 -P2/4[[-1, 18], 1, Concat, [1]], # 24 cat head P4[-1, 3, C3, [512, False]], # 25 (P4/16-medium)[-1, 1, Conv, [512, 3, 1]], # 26[-1,1,space_to_depth,[1]], # 27 -P2/4[[-1, 14], 1, Concat, [1]], # 28 cat head P5[-1, 3, C3, [1024, False]], # 29 (P5/32-large)[[21, 25, 29], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
参考
[1] Raja Sunkara, Tie Luo. No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution Images and Small Objects. 2022
[2] https://github.com/LabSAINT/SPD-Conv
[3] https://github.com/ultralytics/yolov5.git
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入YOLO系列专栏、自然语言处理
专栏或我的个人主页查看- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
这篇关于YOLOv5:修改backbone为SPD-Conv的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





